 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSnapGen++: Unleashing Diffusion Transformers for Efficient High-Fidelity Image Generation on Edge Devices
Jan 13, 2026Recent advances in diffusion transformers (DiTs) have set new standards in image generation, yet remain impractical for on-device deployment due to their high computational and memory costs. In this work, we present an efficient DiT framework tailored for mobile and edge devices that achieves transformer-level generation quality under strict resource constraints. Our design combines three key components. First, we propose a compact DiT architecture with an adaptive global-local sparse attention mechanism that balances global context modeling and local detail preservation. Second, we propose an elastic training framework that jointly optimizes sub-DiTs of varying capacities within a unified supernetwork, allowing a single model to dynamically adjust for efficient inference across different hardware. Finally, we develop Knowledge-Guided Distribution Matching Distillation, a step-distillation pipeline that integrates the DMD objective with knowledge transfer from few-step teacher models, producing high-fidelity and low-latency generation (e.g., 4-step) suitable for real-time on-device use. Together, these contributions enable scalable, efficient, and high-quality diffusion models for deployment on diverse hardware.
SnapGen: Taming High-Resolution Text-to-Image Models for Mobile Devices with Efficient Architectures and Training
Dec 12, 2024Existing text-to-image (T2I) diffusion models face several limitations, including large model sizes, slow runtime, and low-quality generation on mobile devices. This paper aims to address all of these challenges by developing an extremely small and fast T2I model that generates high-resolution and high-quality images on mobile platforms. We propose several techniques to achieve this goal. First, we systematically examine the design choices of the network architecture to reduce model parameters and latency, while ensuring high-quality generation. Second, to further improve generation quality, we employ cross-architecture knowledge distillation from a much larger model, using a multi-level approach to guide the training of our model from scratch. Third, we enable a few-step generation by integrating adversarial guidance with knowledge distillation. For the first time, our model SnapGen, demonstrates the generation of 1024x1024 px images on a mobile device around 1.4 seconds. On ImageNet-1K, our model, with only 372M parameters, achieves an FID of 2.06 for 256x256 px generation. On T2I benchmarks (i.e., GenEval and DPG-Bench), our model with merely 379M parameters, surpasses large-scale models with billions of parameters at a significantly smaller size (e.g., 7x smaller than SDXL, 14x smaller than IF-XL).
Efficient Training with Denoised Neural Weights
Jul 16, 2024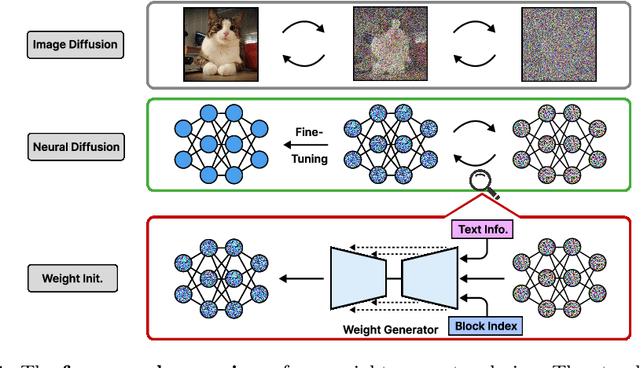
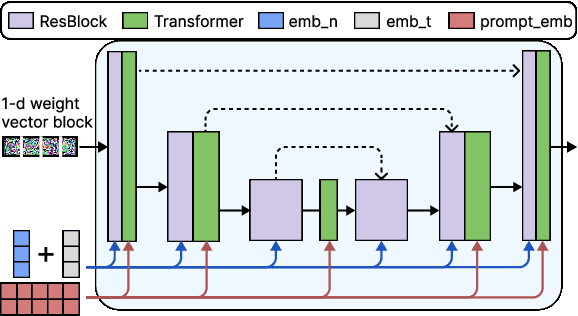
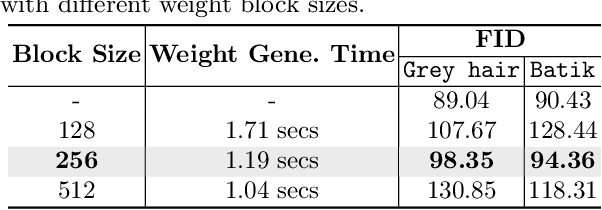
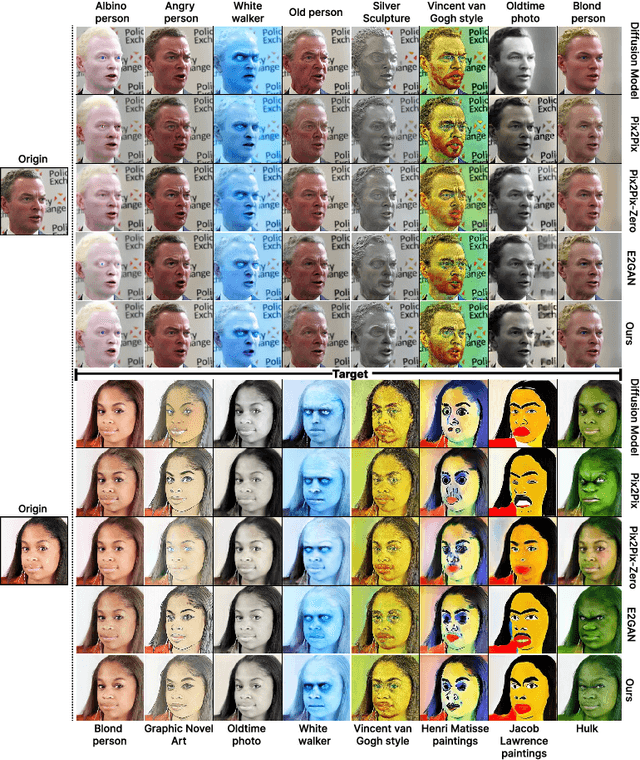
Good weight initialization serves as an effective measure to reduce the training cost of a deep neural network (DNN) model. The choice of how to initialize parameters is challenging and may require manual tuning, which can be time-consuming and prone to human error. To overcome such limitations, this work takes a novel step towards building a weight generator to synthesize the neural weights for initialization. We use the image-to-image translation task with generative adversarial networks (GANs) as an example due to the ease of collecting model weights spanning a wide range. Specifically, we first collect a dataset with various image editing concepts and their corresponding trained weights, which are later used for the training of the weight generator. To address the different characteristics among layers and the substantial number of weights to be predicted, we divide the weights into equal-sized blocks and assign each block an index. Subsequently, a diffusion model is trained with such a dataset using both text conditions of the concept and the block indexes. By initializing the image translation model with the denoised weights predicted by our diffusion model, the training requires only 43.3 seconds. Compared to training from scratch (i.e., Pix2pix), we achieve a 15x training time acceleration for a new concept while obtaining even better image generation quality.
BitsFusion: 1.99 bits Weight Quantization of Diffusion Model
Jun 06, 2024
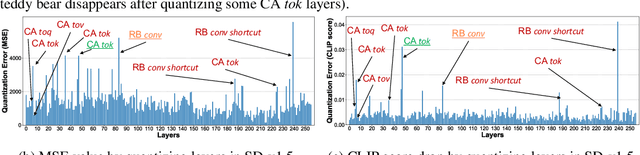
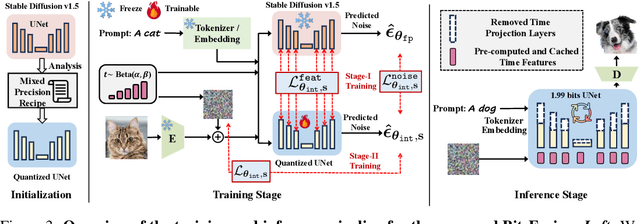
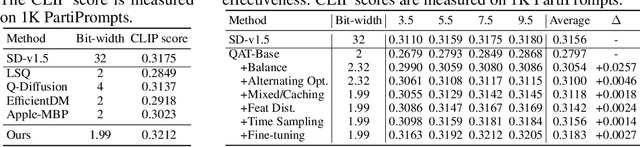
Diffusion-based image generation models have achieved great success in recent years by showing the capability of synthesizing high-quality content. However, these models contain a huge number of parameters, resulting in a significantly large model size. Saving and transferring them is a major bottleneck for various applications, especially those running on resource-constrained devices. In this work, we develop a novel weight quantization method that quantizes the UNet from Stable Diffusion v1.5 to 1.99 bits, achieving a model with 7.9X smaller size while exhibiting even better generation quality than the original one. Our approach includes several novel techniques, such as assigning optimal bits to each layer, initializing the quantized model for better performance, and improving the training strategy to dramatically reduce quantization error. Furthermore, we extensively evaluate our quantized model across various benchmark datasets and through human evaluation to demonstrate its superior generation quality.
TextCraftor: Your Text Encoder Can be Image Quality Controller
Mar 27, 2024



Diffusion-based text-to-image generative models, e.g., Stable Diffusion, have revolutionized the field of content generation, enabling significant advancements in areas like image editing and video synthesis. Despite their formidable capabilities, these models are not without their limitations. It is still challenging to synthesize an image that aligns well with the input text, and multiple runs with carefully crafted prompts are required to achieve satisfactory results. To mitigate these limitations, numerous studies have endeavored to fine-tune the pre-trained diffusion models, i.e., UNet, utilizing various technologies. Yet, amidst these efforts, a pivotal question of text-to-image diffusion model training has remained largely unexplored: Is it possible and feasible to fine-tune the text encoder to improve the performance of text-to-image diffusion models? Our findings reveal that, instead of replacing the CLIP text encoder used in Stable Diffusion with other large language models, we can enhance it through our proposed fine-tuning approach, TextCraftor, leading to substantial improvements in quantitative benchmarks and human assessments. Interestingly, our technique also empowers controllable image generation through the interpolation of different text encoders fine-tuned with various rewards. We also demonstrate that TextCraftor is orthogonal to UNet finetuning, and can be combined to further improve generative quality.
E$^{2}$GAN: Efficient Training of Efficient GANs for Image-to-Image Translation
Jan 11, 2024



One highly promising direction for enabling flexible real-time on-device image editing is utilizing data distillation by leveraging large-scale text-to-image diffusion models, such as Stable Diffusion, to generate paired datasets used for training generative adversarial networks (GANs). This approach notably alleviates the stringent requirements typically imposed by high-end commercial GPUs for performing image editing with diffusion models. However, unlike text-to-image diffusion models, each distilled GAN is specialized for a specific image editing task, necessitating costly training efforts to obtain models for various concepts. In this work, we introduce and address a novel research direction: can the process of distilling GANs from diffusion models be made significantly more efficient? To achieve this goal, we propose a series of innovative techniques. First, we construct a base GAN model with generalized features, adaptable to different concepts through fine-tuning, eliminating the need for training from scratch. Second, we identify crucial layers within the base GAN model and employ Low-Rank Adaptation (LoRA) with a simple yet effective rank search process, rather than fine-tuning the entire base model. Third, we investigate the minimal amount of data necessary for fine-tuning, further reducing the overall training time. Extensive experiments show that we can efficiently empower GANs with the ability to perform real-time high-quality image editing on mobile devices with remarkable reduced training cost and storage for each concept.
Model compression as constrained optimization, with application to neural nets. Part V: combining compressions
Jul 09, 2021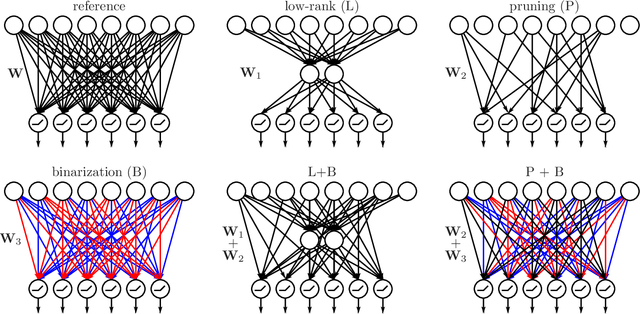
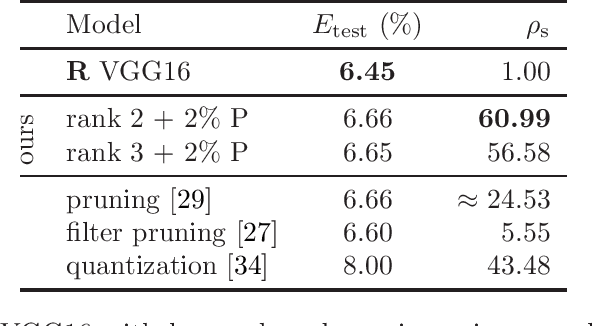
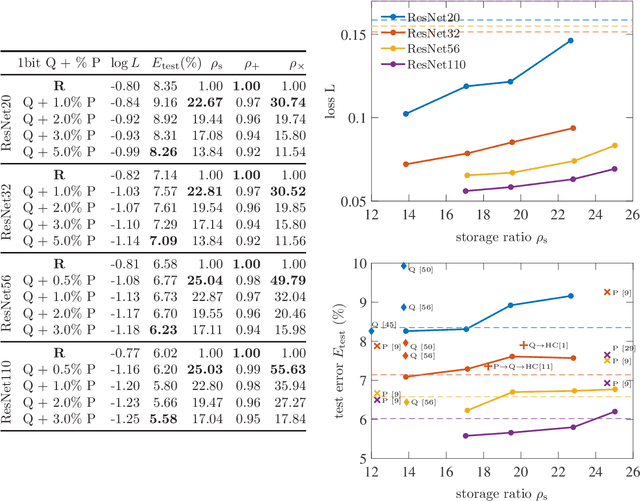

Model compression is generally performed by using quantization, low-rank approximation or pruning, for which various algorithms have been researched in recent years. One fundamental question is: what types of compression work better for a given model? Or even better: can we improve by combining compressions in a suitable way? We formulate this generally as a problem of optimizing the loss but where the weights are constrained to equal an additive combination of separately compressed parts; and we give an algorithm to learn the corresponding parts' parameters. Experimentally with deep neural nets, we observe that 1) we can find significantly better models in the error-compression space, indicating that different compression types have complementary benefits, and 2) the best type of combination depends exquisitely on the type of neural net. For example, we can compress ResNets and AlexNet using only 1 bit per weight without error degradation at the cost of adding a few floating point weights. However, VGG nets can be better compressed by combining low-rank with a few floating point weights.
A flexible, extensible software framework for model compression based on the LC algorithm
May 15, 2020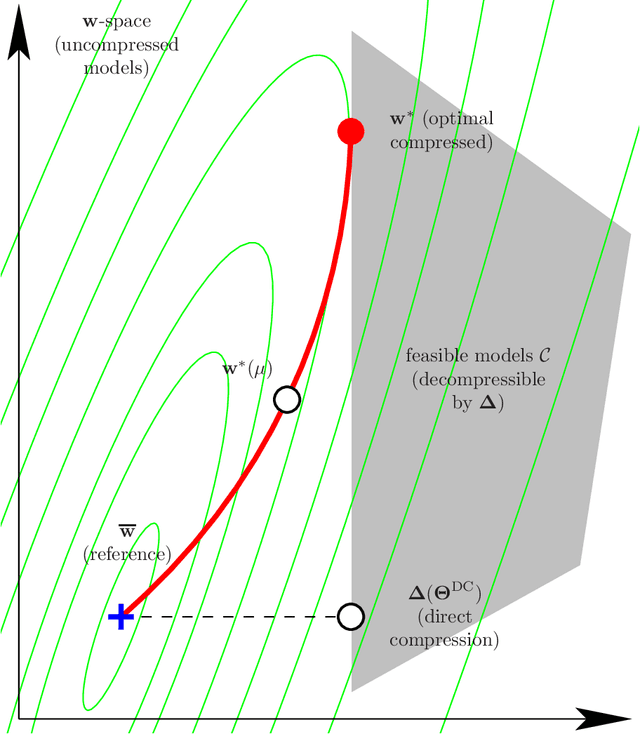


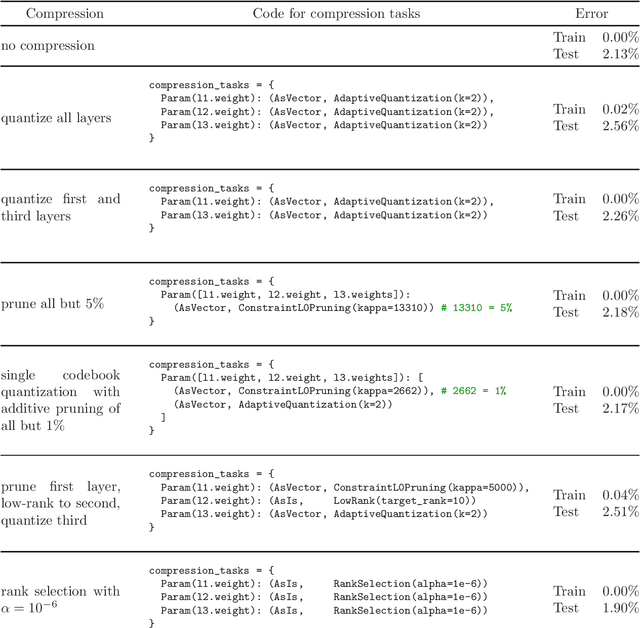
We propose a software framework based on the ideas of the Learning-Compression (LC) algorithm, that allows a user to compress a neural network or other machine learning model using different compression schemes with minimal effort. Currently, the supported compressions include pruning, quantization, low-rank methods (including automatically learning the layer ranks), and combinations of those, and the user can choose different compression types for different parts of a neural network. The LC algorithm alternates two types of steps until convergence: a learning (L) step, which trains a model on a dataset (using an algorithm such as SGD); and a compression (C) step, which compresses the model parameters (using a compression scheme such as low-rank or quantization). This decoupling of the "machine learning" aspect from the "signal compression" aspect means that changing the model or the compression type amounts to calling the corresponding subroutine in the L or C step, respectively. The library fully supports this by design, which makes it flexible and extensible. This does not come at the expense of performance: the runtime needed to compress a model is comparable to that of training the model in the first place; and the compressed model is competitive in terms of prediction accuracy and compression ratio with other algorithms (which are often specialized for specific models or compression schemes). The library is written in Python and PyTorch and available in Github.
Structured Multi-Hashing for Model Compression
Nov 25, 2019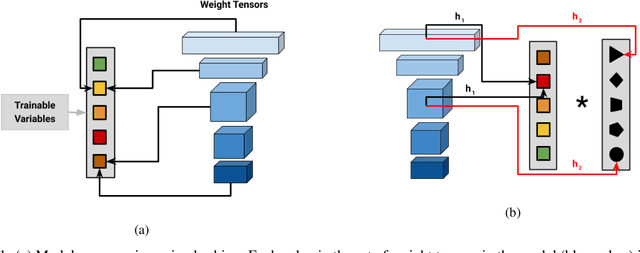
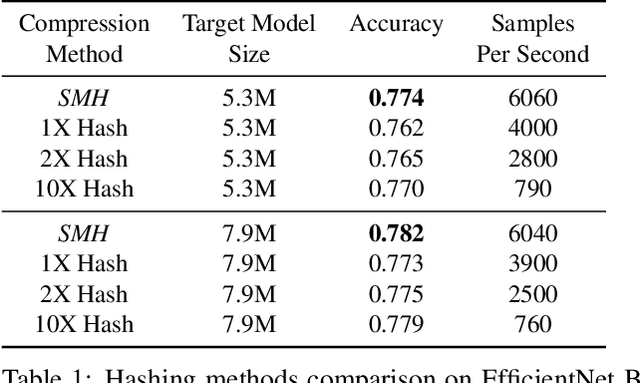
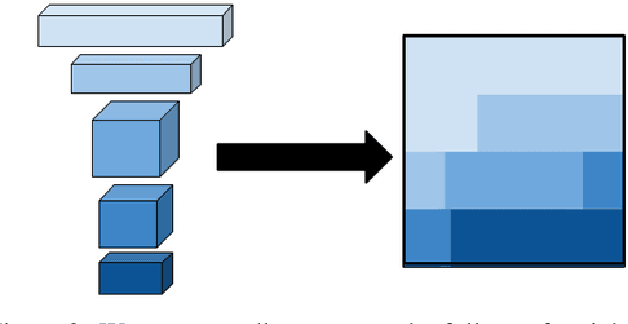
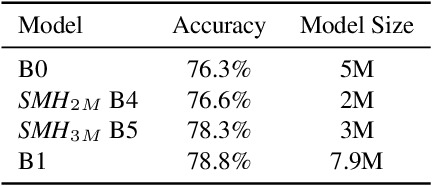
Despite the success of deep neural networks (DNNs), state-of-the-art models are too large to deploy on low-resource devices or common server configurations in which multiple models are held in memory. Model compression methods address this limitation by reducing the memory footprint, latency, or energy consumption of a model with minimal impact on accuracy. We focus on the task of reducing the number of learnable variables in the model. In this work we combine ideas from weight hashing and dimensionality reductions resulting in a simple and powerful structured multi-hashing method based on matrix products that allows direct control of model size of any deep network and is trained end-to-end. We demonstrate the strength of our approach by compressing models from the ResNet, EfficientNet, and MobileNet architecture families. Our method allows us to drastically decrease the number of variables while maintaining high accuracy. For instance, by applying our approach to EfficentNet-B4 (16M parameters) we reduce it to to the size of B0 (5M parameters), while gaining over 3% in accuracy over B0 baseline. On the commonly used benchmark CIFAR10 we reduce the ResNet32 model by 75% with no loss in quality, and are able to do a 10x compression while still achieving above 90% accuracy.
Model compression as constrained optimization, with application to neural nets. Part II: quantization
Jul 13, 2017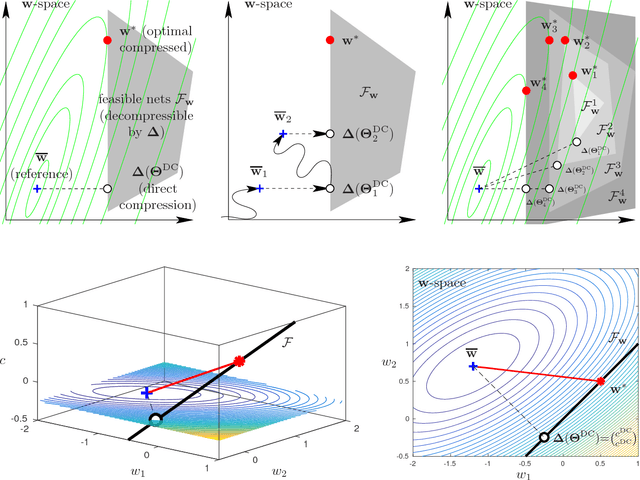
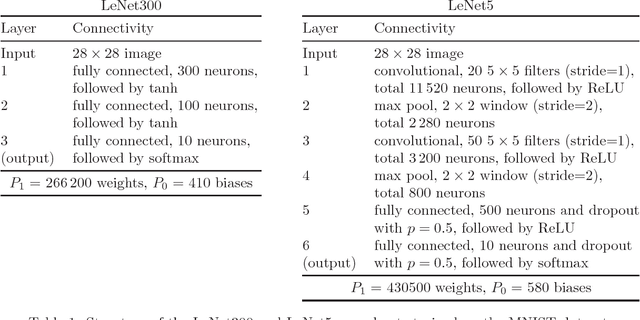


We consider the problem of deep neural net compression by quantization: given a large, reference net, we want to quantize its real-valued weights using a codebook with $K$ entries so that the training loss of the quantized net is minimal. The codebook can be optimally learned jointly with the net, or fixed, as for binarization or ternarization approaches. Previous work has quantized the weights of the reference net, or incorporated rounding operations in the backpropagation algorithm, but this has no guarantee of converging to a loss-optimal, quantized net. We describe a new approach based on the recently proposed framework of model compression as constrained optimization \citep{Carreir17a}. This results in a simple iterative "learning-compression" algorithm, which alternates a step that learns a net of continuous weights with a step that quantizes (or binarizes/ternarizes) the weights, and is guaranteed to converge to local optimum of the loss for quantized nets. We develop algorithms for an adaptive codebook or a (partially) fixed codebook. The latter includes binarization, ternarization, powers-of-two and other important particular cases. We show experimentally that we can achieve much higher compression rates than previous quantization work (even using just 1 bit per weight) with negligible loss degradation.