 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitsFusion: 1.99 bits Weight Quantization of Diffusion Model
Paper and Code

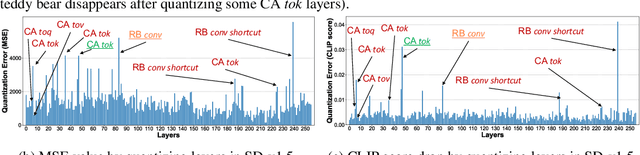
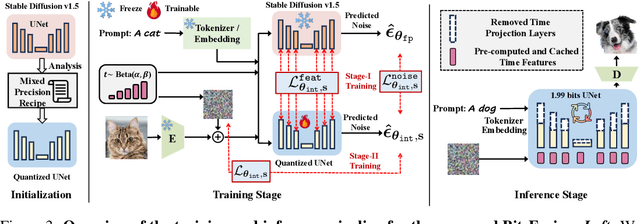
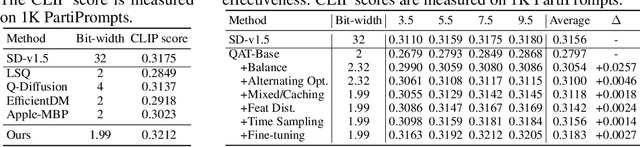
Diffusion-based image generation models have achieved great success in recent years by showing the capability of synthesizing high-quality content. However, these models contain a huge number of parameters, resulting in a significantly large model size. Saving and transferring them is a major bottleneck for various applications, especially those running on resource-constrained devices. In this work, we develop a novel weight quantization method that quantizes the UNet from Stable Diffusion v1.5 to 1.99 bits, achieving a model with 7.9X smaller size while exhibiting even better generation quality than the original one. Our approach includes several novel techniques, such as assigning optimal bits to each layer, initializing the quantized model for better performance, and improving the training strategy to dramatically reduce quantization error. Furthermore, we extensively evaluate our quantized model across various benchmark datasets and through human evaluation to demonstrate its superior generation quality.