 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel compression as constrained optimization, with application to neural nets. Part II: quantization
Paper and Code
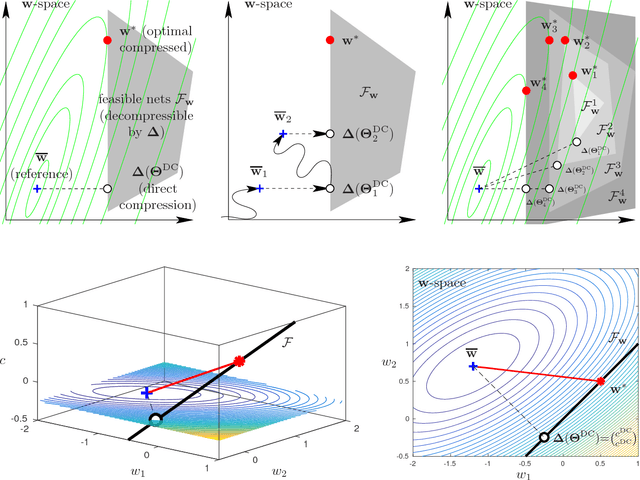


We consider the problem of deep neural net compression by quantization: given a large, reference net, we want to quantize its real-valued weights using a codebook with $K$ entries so that the training loss of the quantized net is minimal. The codebook can be optimally learned jointly with the net, or fixed, as for binarization or ternarization approaches. Previous work has quantized the weights of the reference net, or incorporated rounding operations in the backpropagation algorithm, but this has no guarantee of converging to a loss-optimal, quantized net. We describe a new approach based on the recently proposed framework of model compression as constrained optimization \citep{Carreir17a}. This results in a simple iterative "learning-compression" algorithm, which alternates a step that learns a net of continuous weights with a step that quantizes (or binarizes/ternarizes) the weights, and is guaranteed to converge to local optimum of the loss for quantized nets. We develop algorithms for an adaptive codebook or a (partially) fixed codebook. The latter includes binarization, ternarization, powers-of-two and other important particular cases. We show experimentally that we can achieve much higher compression rates than previous quantization work (even using just 1 bit per weight) with negligible loss degradation.