 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeSpecBench: Benchmarking LLMs for Executable Behavioral Specification Generation
Apr 14, 2026Large language models (LLMs) can generate code from natural language, but the extent to which they capture intended program behavior remains unclear. Executable behavioral specifications, defined via preconditions and postconditions, provide a concrete means to assess such understanding. However, existing work on specification generation is constrained in evaluation methodology, task settings, and specification expressiveness. We introduce CodeSpecBench, a benchmark for executable behavioral specification generation under an execution-based evaluation protocol. CodeSpecBench supports both function-level and repository-level tasks and encodes specifications as executable Python functions. Constructed from diverse real-world codebases, it enables a realistic assessment of both correctness (accepting valid behaviors) and completeness (rejecting invalid behaviors). Evaluating 15 state-of-the-art LLMs on CodeSpecBench, we observe a sharp performance degradation on repository-level tasks, where the best model attains only a 20.2% pass rate. We further find that specification generation is substantially more challenging than code generation, indicating that strong coding performance does not necessarily reflect deep understanding of intended program semantics. Our data and code are available at https://github.com/SparksofAGI/CodeSpecBench.
SWE-Lego: Pushing the Limits of Supervised Fine-tuning for Software Issue Resolving
Jan 07, 2026We present SWE-Lego, a supervised fine-tuning (SFT) recipe designed to achieve state-ofthe-art performance in software engineering (SWE) issue resolving. In contrast to prevalent methods that rely on complex training paradigms (e.g., mid-training, SFT, reinforcement learning, and their combinations), we explore how to push the limits of a lightweight SFT-only approach for SWE tasks. SWE-Lego comprises three core building blocks, with key findings summarized as follows: 1) the SWE-Lego dataset, a collection of 32k highquality task instances and 18k validated trajectories, combining real and synthetic data to complement each other in both quality and quantity; 2) a refined SFT procedure with error masking and a difficulty-based curriculum, which demonstrably improves action quality and overall performance. Empirical results show that with these two building bricks alone,the SFT can push SWE-Lego models to state-of-the-art performance among open-source models of comparable size on SWE-bench Verified: SWE-Lego-Qwen3-8B reaches 42.2%, and SWE-Lego-Qwen3-32B attains 52.6%. 3) We further evaluate and improve test-time scaling (TTS) built upon the SFT foundation. Based on a well-trained verifier, SWE-Lego models can be significantly boosted--for example, 42.2% to 49.6% and 52.6% to 58.8% under TTS@16 for the 8B and 32B models, respectively.
SwingArena: Competitive Programming Arena for Long-context GitHub Issue Solving
May 29, 2025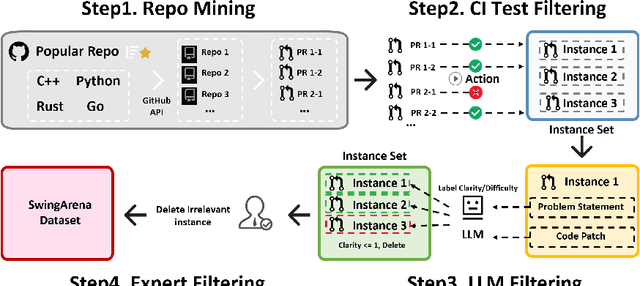
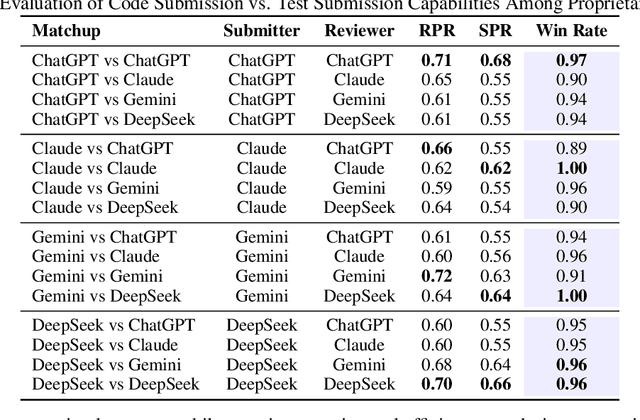
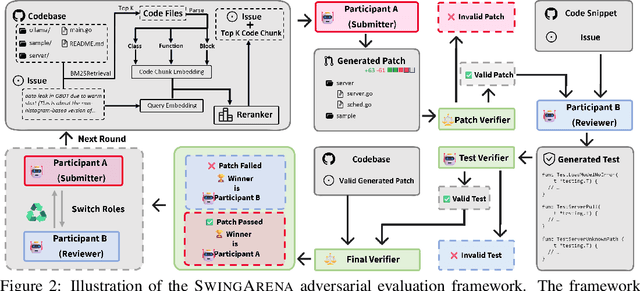
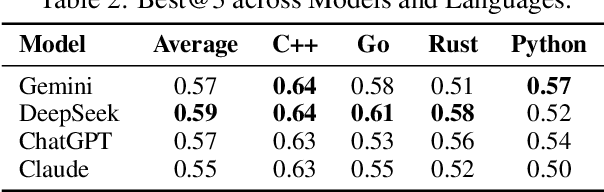
We present SwingArena, a competitive evaluation framework for Large Language Models (LLMs) that closely mirrors real-world software development workflows. Unlike traditional static benchmarks, SwingArena models the collaborative process of software iteration by pairing LLMs as submitters, who generate patches, and reviewers, who create test cases and verify the patches through continuous integration (CI) pipelines. To support these interactive evaluations, we introduce a retrieval-augmented code generation (RACG) module that efficiently handles long-context challenges by providing syntactically and semantically relevant code snippets from large codebases, supporting multiple programming languages (C++, Python, Rust, and Go). This enables the framework to scale across diverse tasks and contexts while respecting token limitations. Our experiments, using over 400 high-quality real-world GitHub issues selected from a pool of 2,300 issues, show that models like GPT-4o excel at aggressive patch generation, whereas DeepSeek and Gemini prioritize correctness in CI validation. SwingArena presents a scalable and extensible methodology for evaluating LLMs in realistic, CI-driven software development settings. More details are available on our project page: swing-bench.github.io
Effi-Code: Unleashing Code Efficiency in Language Models
Oct 14, 2024



As the use of large language models (LLMs) for code generation becomes more prevalent in software development, it is critical to enhance both the efficiency and correctness of the generated code. Existing methods and models primarily focus on the correctness of LLM-generated code, ignoring efficiency. In this work, we present Effi-Code, an approach to enhancing code generation in LLMs that can improve both efficiency and correctness. We introduce a Self-Optimization process based on Overhead Profiling that leverages open-source LLMs to generate a high-quality dataset of correct and efficient code samples. This dataset is then used to fine-tune various LLMs. Our method involves the iterative refinement of generated code, guided by runtime performance metrics and correctness checks. Extensive experiments demonstrate that models fine-tuned on the Effi-Code show significant improvements in both code correctness and efficiency across task types. For example, the pass@1 of DeepSeek-Coder-6.7B-Instruct generated code increases from \textbf{43.3\%} to \textbf{76.8\%}, and the average execution time for the same correct tasks decreases by \textbf{30.5\%}. Effi-Code offers a scalable and generalizable approach to improving code generation in AI systems, with potential applications in software development, algorithm design, and computational problem-solving. The source code of Effi-Code was released in \url{https://github.com/huangd1999/Effi-Code}.
MR-BEN: A Comprehensive Meta-Reasoning Benchmark for Large Language Models
Jun 20, 2024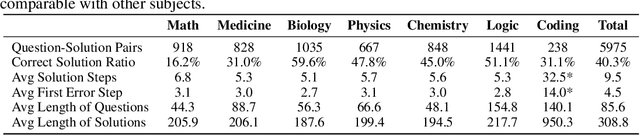
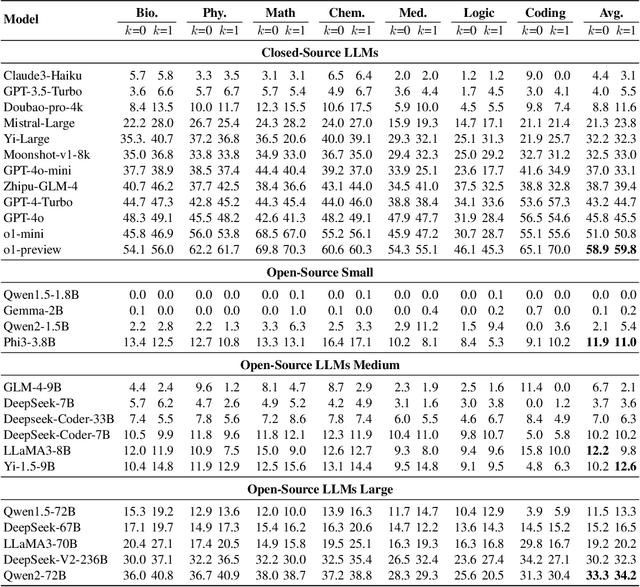
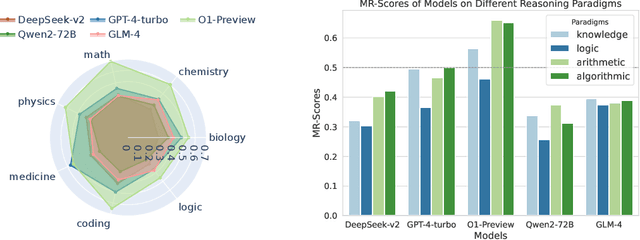
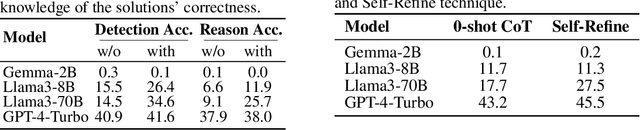
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, it has been increasingly challenging to evaluate the reasoning capability of LLMs. Concretely, existing outcome-based benchmarks begin to saturate and become less sufficient to monitor the progress. To this end, we present a process-based benchmark MR-BEN that demands a meta reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. MR-BEN is a comprehensive benchmark comprising 5,975 questions collected from human experts, covering various subjects such as physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, open-source models are seemingly comparable to GPT-4 on outcome-based benchmarks, but they lag far behind on our benchmark, revealing the underlying reasoning capability gap between them. Our dataset and codes are available on https://randolph-zeng.github.io/Mr-Ben.github.io/.
AutoCV: Empowering Reasoning with Automated Process Labeling via Confidence Variation
May 29, 2024



In this work, we propose a novel method named \textbf{Auto}mated Process Labeling via \textbf{C}onfidence \textbf{V}ariation (\textbf{\textsc{AutoCV}}) to enhance the reasoning capabilities of large language models (LLMs) by automatically annotating the reasoning steps. Our approach begins by training a verification model on the correctness of final answers, enabling it to generate automatic process annotations. This verification model assigns a confidence score to each reasoning step, indicating the probability of arriving at the correct final answer from that point onward. We detect relative changes in the verification's confidence scores across reasoning steps to automatically annotate the reasoning process. This alleviates the need for numerous manual annotations or the high computational costs associated with model-induced annotation approaches. We experimentally validate that the confidence variations learned by the verification model trained on the final answer correctness can effectively identify errors in the reasoning steps. Subsequently, we demonstrate that the process annotations generated by \textsc{AutoCV} can improve the accuracy of the verification model in selecting the correct answer from multiple outputs generated by LLMs. Notably, we achieve substantial improvements across five datasets in mathematics and commonsense reasoning. The source code of \textsc{AutoCV} is available at \url{https://github.com/rookie-joe/AUTOCV}.
SOAP: Enhancing Efficiency of Generated Code via Self-Optimization
May 24, 2024



Large language models (LLMs) have shown remarkable progress in code generation, but their generated code often suffers from inefficiency, resulting in longer execution times and higher memory consumption. To address this issue, we propose Self Optimization based on OverheAd Profile (SOAP), a self-optimization framework that utilizes execution overhead profiles to improve the efficiency of LLM-generated code. SOAP first generates code using an LLM, then executes it locally to capture execution time and memory usage profiles. These profiles are fed back to the LLM, which then revises the code to reduce overhead. To evaluate the effectiveness of SOAP, we conduct extensive experiments on the EffiBench, HumanEval, and MBPP with 16 open-source and 6 closed-source models. Our evaluation results demonstrate that through iterative self-optimization, SOAP significantly enhances the efficiency of LLM-generated code. For example, the execution time (ET) of StarCoder2-15B for the EffiBench decreases from 0.93 (s) to 0.12 (s) which reduces 87.1% execution time requirement compared with the initial code. The total memory usage (TMU) of StarCoder2-15B also decreases from 22.02 (Mb*s) to 2.03 (Mb*s), which decreases 90.8% total memory consumption during the execution process. The source code of SOAP was released in https://github.com/huangd1999/SOAP.
MHPP: Exploring the Capabilities and Limitations of Language Models Beyond Basic Code Generation
May 19, 2024



Recent advancements in large language models (LLMs) have greatly improved code generation, specifically at the function level. For instance, GPT-4 has achieved an 88.4% pass rate on HumanEval. However, this draws into question the adequacy of existing benchmarks in thoroughly assessing function-level code generation capabilities. Our study analyzed two common benchmarks, HumanEval and MBPP, and found that these might not thoroughly evaluate LLMs' code generation capacities due to limitations in quality, difficulty, and granularity. To resolve this, we introduce the Mostly Hard Python Problems (MHPP) dataset, consisting of 140 unique human-curated problems. By focusing on the combination of natural language and code reasoning, MHPP gauges LLMs' abilities to comprehend specifications and restrictions, engage in multi-step reasoning, and apply coding knowledge effectively. Initial evaluations of 22 LLMs using MHPP showed many high-performing models on HumanEval failed to achieve similar success on MHPP. Moreover, MHPP highlighted various previously undiscovered limitations within various LLMs, leading us to believe that it could pave the way for a better understanding of LLMs' capabilities and limitations. Dataset and code are available at https://github.com/SparksofAGI/MHPP.