 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInSight-o3: Empowering Multimodal Foundation Models with Generalized Visual Search
Dec 21, 2025The ability for AI agents to "think with images" requires a sophisticated blend of reasoning and perception. However, current open multimodal agents still largely fall short on the reasoning aspect crucial for real-world tasks like analyzing documents with dense charts/diagrams and navigating maps. To address this gap, we introduce O3-Bench, a new benchmark designed to evaluate multimodal reasoning with interleaved attention to visual details. O3-Bench features challenging problems that require agents to piece together subtle visual information from distinct image areas through multi-step reasoning. The problems are highly challenging even for frontier systems like OpenAI o3, which only obtains 40.8% accuracy on O3-Bench. To make progress, we propose InSight-o3, a multi-agent framework consisting of a visual reasoning agent (vReasoner) and a visual search agent (vSearcher) for which we introduce the task of generalized visual search -- locating relational, fuzzy, or conceptual regions described in free-form language, beyond just simple objects or figures in natural images. We then present a multimodal LLM purpose-trained for this task via reinforcement learning. As a plug-and-play agent, our vSearcher empowers frontier multimodal models (as vReasoners), significantly improving their performance on a wide range of benchmarks. This marks a concrete step towards powerful o3-like open systems. Our code and dataset can be found at https://github.com/m-Just/InSight-o3 .
CannyEdit: Selective Canny Control and Dual-Prompt Guidance for Training-Free Image Editing
Aug 09, 2025Recent advances in text-to-image (T2I) models have enabled training-free regional image editing by leveraging the generative priors of foundation models. However, existing methods struggle to balance text adherence in edited regions, context fidelity in unedited areas, and seamless integration of edits. We introduce CannyEdit, a novel training-free framework that addresses these challenges through two key innovations: (1) Selective Canny Control, which masks the structural guidance of Canny ControlNet in user-specified editable regions while strictly preserving details of the source images in unedited areas via inversion-phase ControlNet information retention. This enables precise, text-driven edits without compromising contextual integrity. (2) Dual-Prompt Guidance, which combines local prompts for object-specific edits with a global target prompt to maintain coherent scene interactions. On real-world image editing tasks (addition, replacement, removal), CannyEdit outperforms prior methods like KV-Edit, achieving a 2.93 to 10.49 percent improvement in the balance of text adherence and context fidelity. In terms of editing seamlessness, user studies reveal only 49.2 percent of general users and 42.0 percent of AIGC experts identified CannyEdit's results as AI-edited when paired with real images without edits, versus 76.08 to 89.09 percent for competitor methods.
The Synergy Dilemma of Long-CoT SFT and RL: Investigating Post-Training Techniques for Reasoning VLMs
Jul 10, 2025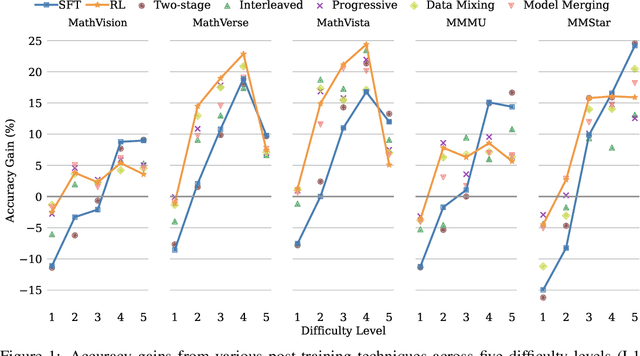
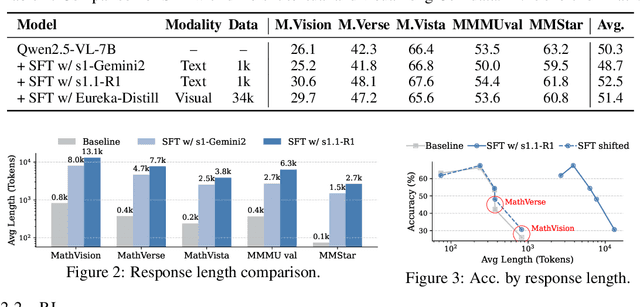
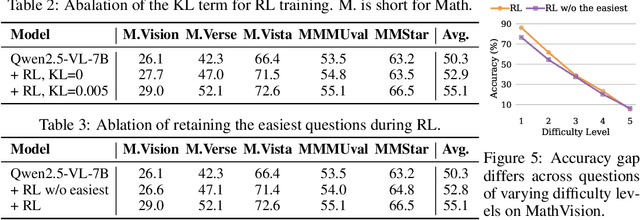
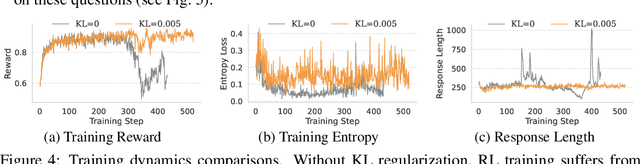
Large vision-language models (VLMs) increasingly adopt post-training techniques such as long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL) to elicit sophisticated reasoning. While these methods exhibit synergy in language-only models, their joint effectiveness in VLMs remains uncertain. We present a systematic investigation into the distinct roles and interplay of long-CoT SFT and RL across multiple multimodal reasoning benchmarks. We find that SFT improves performance on difficult questions by in-depth, structured reasoning, but introduces verbosity and degrades performance on simpler ones. In contrast, RL promotes generalization and brevity, yielding consistent improvements across all difficulty levels, though the improvements on the hardest questions are less prominent compared to SFT. Surprisingly, combining them through two-staged, interleaved, or progressive training strategies, as well as data mixing and model merging, all fails to produce additive benefits, instead leading to trade-offs in accuracy, reasoning style, and response length. This ``synergy dilemma'' highlights the need for more seamless and adaptive approaches to unlock the full potential of combined post-training techniques for reasoning VLMs.
Dual Risk Minimization: Towards Next-Level Robustness in Fine-tuning Zero-Shot Models
Nov 29, 2024



Fine-tuning foundation models often compromises their robustness to distribution shifts. To remedy this, most robust fine-tuning methods aim to preserve the pre-trained features. However, not all pre-trained features are robust and those methods are largely indifferent to which ones to preserve. We propose dual risk minimization (DRM), which combines empirical risk minimization with worst-case risk minimization, to better preserve the core features of downstream tasks. In particular, we utilize core-feature descriptions generated by LLMs to induce core-based zero-shot predictions which then serve as proxies to estimate the worst-case risk. DRM balances two crucial aspects of model robustness: expected performance and worst-case performance, establishing a new state of the art on various real-world benchmarks. DRM significantly improves the out-of-distribution performance of CLIP ViT-L/14@336 on ImageNet (75.9 to 77.1), WILDS-iWildCam (47.1 to 51.8), and WILDS-FMoW (50.7 to 53.1); opening up new avenues for robust fine-tuning. Our code is available at https://github.com/vaynexie/DRM .
Robustness May be More Brittle than We Think under Different Degrees of Distribution Shifts
Oct 10, 2023Out-of-distribution (OOD) generalization is a complicated problem due to the idiosyncrasies of possible distribution shifts between training and test domains. Most benchmarks employ diverse datasets to address this issue; however, the degree of the distribution shift between the training domains and the test domains of each dataset remains largely fixed. This may lead to biased conclusions that either underestimate or overestimate the actual OOD performance of a model. Our study delves into a more nuanced evaluation setting that covers a broad range of shift degrees. We show that the robustness of models can be quite brittle and inconsistent under different degrees of distribution shifts, and therefore one should be more cautious when drawing conclusions from evaluations under a limited range of degrees. In addition, we observe that large-scale pre-trained models, such as CLIP, are sensitive to even minute distribution shifts of novel downstream tasks. This indicates that while pre-trained representations may help improve downstream in-distribution performance, they could have minimal or even adverse effects on generalization in certain OOD scenarios of the downstream task if not used properly. In light of these findings, we encourage future research to conduct evaluations across a broader range of shift degrees whenever possible.
A Causal Framework to Unify Common Domain Generalization Approaches
Jul 13, 2023



Domain generalization (DG) is about learning models that generalize well to new domains that are related to, but different from, the training domain(s). It is a fundamental problem in machine learning and has attracted much attention in recent years. A large number of approaches have been proposed. Different approaches are motivated from different perspectives, making it difficult to gain an overall understanding of the area. In this paper, we propose a causal framework for domain generalization and present an understanding of common DG approaches in the framework. Our work sheds new lights on the following questions: (1) What are the key ideas behind each DG method? (2) Why is it expected to improve generalization to new domains theoretically? (3) How are different DG methods related to each other and what are relative advantages and limitations? By providing a unified perspective on DG, we hope to help researchers better understand the underlying principles and develop more effective approaches for this critical problem in machine learning.
Contrastive Domain Generalization via Logit Attribution Matching
May 13, 2023



Domain Generalization (DG) is an important open problem in machine learning. Deep models are susceptible to domain shifts of even minute degrees, which severely compromises their reliability in real applications. To alleviate the issue, most existing methods enforce various invariant constraints across multiple training domains. However,such an approach provides little performance guarantee for novel test domains in general. In this paper, we investigate a different approach named Contrastive Domain Generalization (CDG), which exploits semantic invariance exhibited by strongly contrastive data pairs in lieu of multiple domains. We present a causal DG theory that shows the potential capability of CDG; together with a regularization technique, Logit Attribution Matching (LAM), for realizing CDG. We empirically show that LAM outperforms state-of-the-art DG methods with only a small portion of paired data and that LAM helps models better focus on semantic features which are crucial to DG.
Regularization Penalty Optimization for Addressing Data Quality Variance in OoD Algorithms
Jun 12, 2022
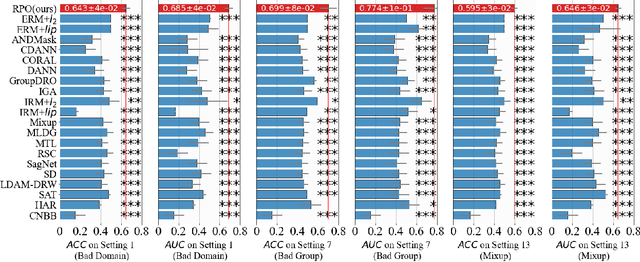

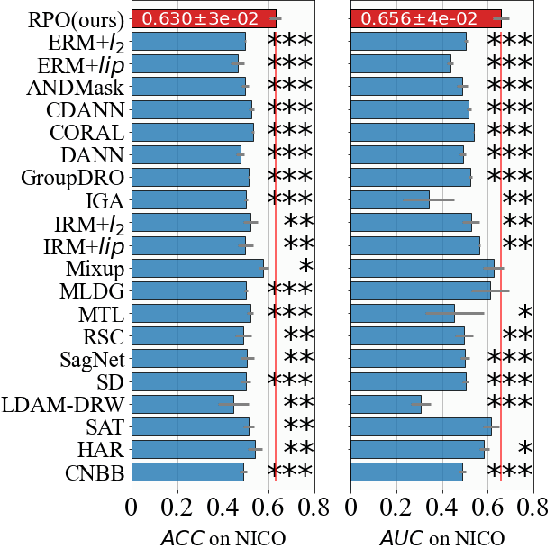
Due to the poor generalization performance of traditional empirical risk minimization (ERM) in the case of distributional shift, Out-of-Distribution (OoD) generalization algorithms receive increasing attention. However, OoD generalization algorithms overlook the great variance in the quality of training data, which significantly compromises the accuracy of these methods. In this paper, we theoretically reveal the relationship between training data quality and algorithm performance and analyze the optimal regularization scheme for Lipschitz regularized invariant risk minimization. A novel algorithm is proposed based on the theoretical results to alleviate the influence of low-quality data at both the sample level and the domain level. The experiments on both the regression and classification benchmarks validate the effectiveness of our method with statistical significance.
CODA: A Real-World Road Corner Case Dataset for Object Detection in Autonomous Driving
Mar 15, 2022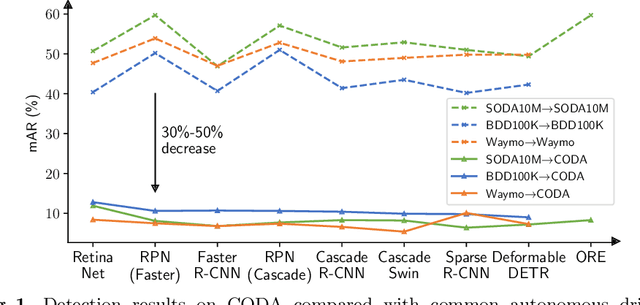
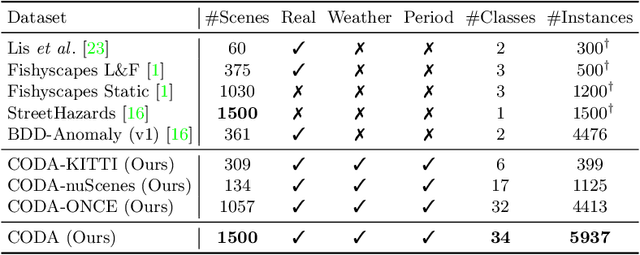

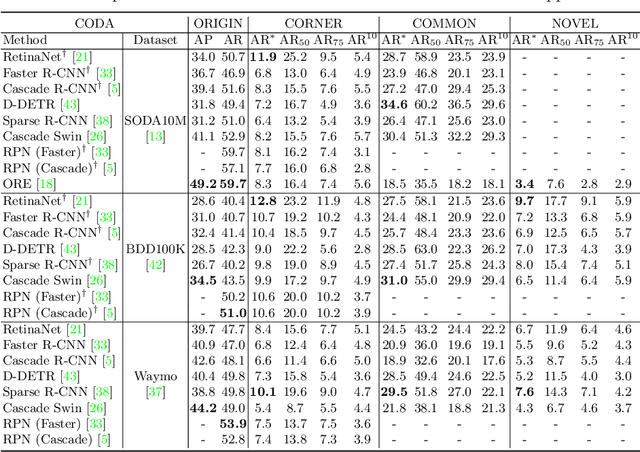
Contemporary deep-learning object detection methods for autonomous driving usually assume prefixed categories of common traffic participants, such as pedestrians and cars. Most existing detectors are unable to detect uncommon objects and corner cases (e.g., a dog crossing a street), which may lead to severe accidents in some situations, making the timeline for the real-world application of reliable autonomous driving uncertain. One main reason that impedes the development of truly reliably self-driving systems is the lack of public datasets for evaluating the performance of object detectors on corner cases. Hence, we introduce a challenging dataset named CODA that exposes this critical problem of vision-based detectors. The dataset consists of 1500 carefully selected real-world driving scenes, each containing four object-level corner cases (on average), spanning 30+ object categories. On CODA, the performance of standard object detectors trained on large-scale autonomous driving datasets significantly drops to no more than 12.8% in mAR. Moreover, we experiment with the state-of-the-art open-world object detector and find that it also fails to reliably identify the novel objects in CODA, suggesting that a robust perception system for autonomous driving is probably still far from reach. We expect our CODA dataset to facilitate further research in reliable detection for real-world autonomous driving. Our dataset will be released at https://coda-dataset.github.io.
OoD-Bench: Benchmarking and Understanding Out-of-Distribution Generalization Datasets and Algorithms
Jun 07, 2021
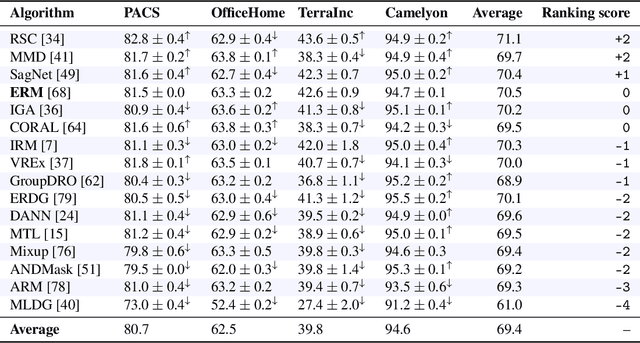
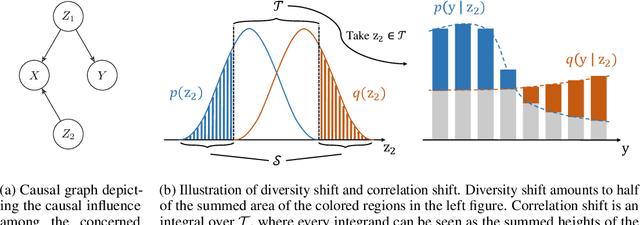
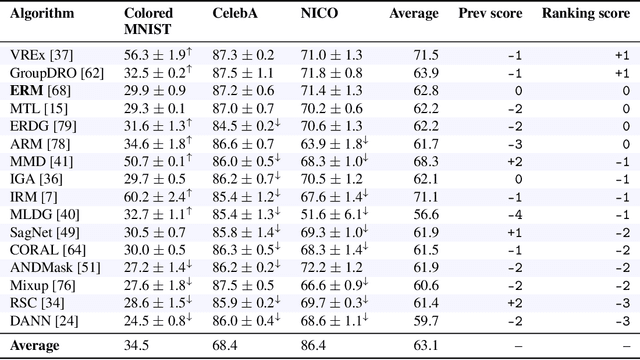
Deep learning has achieved tremendous success with independent and identically distributed (i.i.d.) data. However, the performance of neural networks often degenerates drastically when encountering out-of-distribution (OoD) data, i.e., training and test data are sampled from different distributions. While a plethora of algorithms has been proposed to deal with OoD generalization, our understanding of the data used to train and evaluate these algorithms remains stagnant. In this work, we position existing datasets and algorithms from various research areas (e.g., domain generalization, stable learning, invariant risk minimization) seemingly unconnected into the same coherent picture. First, we identify and measure two distinct kinds of distribution shifts that are ubiquitous in various datasets. Next, we compare various OoD generalization algorithms with a new benchmark dominated by the two distribution shifts. Through extensive experiments, we show that existing OoD algorithms that outperform empirical risk minimization on one distribution shift usually have limitations on the other distribution shift. The new benchmark may serve as a strong foothold that can be resorted to by future OoD generalization research.