 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Boundaries to Semantics: Prompt-Guided Multi-Task Learning for Petrographic Thin-section Segmentation
Apr 16, 2026Grain-edge segmentation (GES) and lithology semantic segmentation (LSS) are two pivotal tasks for quantifying rock fabric and composition. However, these two tasks are often treated separately, and the segmentation quality is implausible albeit expensive, time-consuming, and expert-annotated datasets have been used. Recently, foundation models, especially the Segment Anything Model (SAM), have demonstrated impressive robustness for boundary alignment. However, directly adapting SAM to joint GES and LSS is nontrivial due to 1) severe domain gap induced by extinction-dependent color variations and ultra-fine grain boundaries, and 2) lacking novel modules for joint learning on multi-angle petrographic image stacks. In this paper, we propose Petro-SAM, a novel two-stage, multi-task framework that can achieve high-quality joint GES and LSS on petrographic images. Specifically, based on SAM, we introduce a Merge Block to integrate seven polarized views, effectively solving the extinction issue. Moreover, we introduce multi-scale feature fusion and color-entropy priors to refine the detection.
CytoCrowd: A Multi-Annotator Benchmark Dataset for Cytology Image Analysis
Feb 06, 2026High-quality annotated datasets are crucial for advancing machine learning in medical image analysis. However, a critical gap exists: most datasets either offer a single, clean ground truth, which hides real-world expert disagreement, or they provide multiple annotations without a separate gold standard for objective evaluation. To bridge this gap, we introduce CytoCrowd, a new public benchmark for cytology analysis. The dataset features 446 high-resolution images, each with two key components: (1) raw, conflicting annotations from four independent pathologists, and (2) a separate, high-quality gold-standard ground truth established by a senior expert. This dual structure makes CytoCrowd a versatile resource. It serves as a benchmark for standard computer vision tasks, such as object detection and classification, using the ground truth. Simultaneously, it provides a realistic testbed for evaluating annotation aggregation algorithms that must resolve expert disagreements. We provide comprehensive baseline results for both tasks. Our experiments demonstrate the challenges presented by CytoCrowd and establish its value as a resource for developing the next generation of models for medical image analysis.
MedInsightBench: Evaluating Medical Analytics Agents Through Multi-Step Insight Discovery in Multimodal Medical Data
Dec 15, 2025In medical data analysis, extracting deep insights from complex, multi-modal datasets is essential for improving patient care, increasing diagnostic accuracy, and optimizing healthcare operations. However, there is currently a lack of high-quality datasets specifically designed to evaluate the ability of large multi-modal models (LMMs) to discover medical insights. In this paper, we introduce MedInsightBench, the first benchmark that comprises 332 carefully curated medical cases, each annotated with thoughtfully designed insights. This benchmark is intended to evaluate the ability of LMMs and agent frameworks to analyze multi-modal medical image data, including posing relevant questions, interpreting complex findings, and synthesizing actionable insights and recommendations. Our analysis indicates that existing LMMs exhibit limited performance on MedInsightBench, which is primarily attributed to their challenges in extracting multi-step, deep insights and the absence of medical expertise. Therefore, we propose MedInsightAgent, an automated agent framework for medical data analysis, composed of three modules: Visual Root Finder, Analytical Insight Agent, and Follow-up Question Composer. Experiments on MedInsightBench highlight pervasive challenges and demonstrate that MedInsightAgent can improve the performance of general LMMs in medical data insight discovery.
SCAR: A Characterization Scheme for Multi-Modal Dataset
Aug 27, 2025Foundation models exhibit remarkable generalization across diverse tasks, largely driven by the characteristics of their training data. Recent data-centric methods like pruning and compression aim to optimize training but offer limited theoretical insight into how data properties affect generalization, especially the data characteristics in sample scaling. Traditional perspectives further constrain progress by focusing predominantly on data quantity and training efficiency, often overlooking structural aspects of data quality. In this study, we introduce SCAR, a principled scheme for characterizing the intrinsic structural properties of datasets across four key measures: Scale, Coverage, Authenticity, and Richness. Unlike prior data-centric measures, SCAR captures stable characteristics that remain invariant under dataset scaling, providing a robust and general foundation for data understanding. Leveraging these structural properties, we introduce Foundation Data-a minimal subset that preserves the generalization behavior of the full dataset without requiring model-specific retraining. We model single-modality tasks as step functions and estimate the distribution of the foundation data size to capture step-wise generalization bias across modalities in the target multi-modal dataset. Finally, we develop a SCAR-guided data completion strategy based on this generalization bias, which enables efficient, modality-aware expansion of modality-specific characteristics in multimodal datasets. Experiments across diverse multi-modal datasets and model architectures validate the effectiveness of SCAR in predicting data utility and guiding data acquisition. Code is available at https://github.com/McAloma/SCAR.
Towards Fine-Grained Explainability for Heterogeneous Graph Neural Network
Dec 23, 2023Heterogeneous graph neural networks (HGNs) are prominent approaches to node classification tasks on heterogeneous graphs. Despite the superior performance, insights about the predictions made from HGNs are obscure to humans. Existing explainability techniques are mainly proposed for GNNs on homogeneous graphs. They focus on highlighting salient graph objects to the predictions whereas the problem of how these objects affect the predictions remains unsolved. Given heterogeneous graphs with complex structures and rich semantics, it is imperative that salient objects can be accompanied with their influence paths to the predictions, unveiling the reasoning process of HGNs. In this paper, we develop xPath, a new framework that provides fine-grained explanations for black-box HGNs specifying a cause node with its influence path to the target node. In xPath, we differentiate the influence of a node on the prediction w.r.t. every individual influence path, and measure the influence by perturbing graph structure via a novel graph rewiring algorithm. Furthermore, we introduce a greedy search algorithm to find the most influential fine-grained explanations efficiently. Empirical results on various HGNs and heterogeneous graphs show that xPath yields faithful explanations efficiently, outperforming the adaptations of advanced GNN explanation approaches.
Two-Stage Holistic and Contrastive Explanation of Image Classification
Jun 10, 2023



The need to explain the output of a deep neural network classifier is now widely recognized. While previous methods typically explain a single class in the output, we advocate explaining the whole output, which is a probability distribution over multiple classes. A whole-output explanation can help a human user gain an overall understanding of model behaviour instead of only one aspect of it. It can also provide a natural framework where one can examine the evidence used to discriminate between competing classes, and thereby obtain contrastive explanations. In this paper, we propose a contrastive whole-output explanation (CWOX) method for image classification, and evaluate it using quantitative metrics and through human subject studies. The source code of CWOX is available at https://github.com/vaynexie/CWOX.
Model Debiasing via Gradient-based Explanation on Representation
May 20, 2023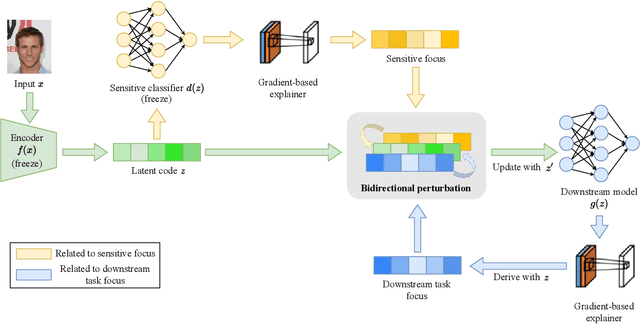



Machine learning systems produce biased results towards certain demographic groups, known as the fairness problem. Recent approaches to tackle this problem learn a latent code (i.e., representation) through disentangled representation learning and then discard the latent code dimensions correlated with sensitive attributes (e.g., gender). Nevertheless, these approaches may suffer from incomplete disentanglement and overlook proxy attributes (proxies for sensitive attributes) when processing real-world data, especially for unstructured data, causing performance degradation in fairness and loss of useful information for downstream tasks. In this paper, we propose a novel fairness framework that performs debiasing with regard to both sensitive attributes and proxy attributes, which boosts the prediction performance of downstream task models without complete disentanglement. The main idea is to, first, leverage gradient-based explanation to find two model focuses, 1) one focus for predicting sensitive attributes and 2) the other focus for predicting downstream task labels, and second, use them to perturb the latent code that guides the training of downstream task models towards fairness and utility goals. We show empirically that our framework works with both disentangled and non-disentangled representation learning methods and achieves better fairness-accuracy trade-off on unstructured and structured datasets than previous state-of-the-art approaches.
Contrastive Domain Generalization via Logit Attribution Matching
May 13, 2023



Domain Generalization (DG) is an important open problem in machine learning. Deep models are susceptible to domain shifts of even minute degrees, which severely compromises their reliability in real applications. To alleviate the issue, most existing methods enforce various invariant constraints across multiple training domains. However,such an approach provides little performance guarantee for novel test domains in general. In this paper, we investigate a different approach named Contrastive Domain Generalization (CDG), which exploits semantic invariance exhibited by strongly contrastive data pairs in lieu of multiple domains. We present a causal DG theory that shows the potential capability of CDG; together with a regularization technique, Logit Attribution Matching (LAM), for realizing CDG. We empirically show that LAM outperforms state-of-the-art DG methods with only a small portion of paired data and that LAM helps models better focus on semantic features which are crucial to DG.
Towards Efficient Visual Simplification of Computational Graphs in Deep Neural Networks
Dec 21, 2022A computational graph in a deep neural network (DNN) denotes a specific data flow diagram (DFD) composed of many tensors and operators. Existing toolkits for visualizing computational graphs are not applicable when the structure is highly complicated and large-scale (e.g., BERT [1]). To address this problem, we propose leveraging a suite of visual simplification techniques, including a cycle-removing method, a module-based edge-pruning algorithm, and an isomorphic subgraph stacking strategy. We design and implement an interactive visualization system that is suitable for computational graphs with up to 10 thousand elements. Experimental results and usage scenarios demonstrate that our tool reduces 60% elements on average and hence enhances the performance for recognizing and diagnosing DNN models. Our contributions are integrated into an open-source DNN visualization toolkit, namely, MindInsight [2].
ViT-CX: Causal Explanation of Vision Transformers
Nov 06, 2022



Despite the popularity of Vision Transformers (ViTs) and eXplainable AI (XAI), only a few explanation methods have been proposed for ViTs thus far. They use attention weights of the classification token on patch embeddings and often produce unsatisfactory saliency maps. In this paper, we propose a novel method for explaining ViTs called ViT-CX. It is based on patch embeddings, rather than attentions paid to them, and their causal impacts on the model output. ViT-CX can be used to explain different ViT models. Empirical results show that, in comparison with previous methods, ViT-CX produces more meaningful saliency maps and does a better job at revealing all the important evidence for prediction. It is also significantly more faithful to the model as measured by deletion AUC and insertion AUC.