 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCPSDBench: A Large Language Model Evaluation Benchmark and Baseline for Chinese Public Security Domain
Feb 11, 2024



Large Language Models (LLMs) have demonstrated significant potential and effectiveness across multiple application domains. To assess the performance of mainstream LLMs in public security tasks, this study aims to construct a specialized evaluation benchmark tailored to the Chinese public security domain--CPSDbench. CPSDbench integrates datasets related to public security collected from real-world scenarios, supporting a comprehensive assessment of LLMs across four key dimensions: text classification, information extraction, question answering, and text generation. Furthermore, this study introduces a set of innovative evaluation metrics designed to more precisely quantify the efficacy of LLMs in executing tasks related to public security. Through the in-depth analysis and evaluation conducted in this research, we not only enhance our understanding of the performance strengths and limitations of existing models in addressing public security issues but also provide references for the future development of more accurate and customized LLM models targeted at applications in this field.
A Causal Framework to Unify Common Domain Generalization Approaches
Jul 13, 2023



Domain generalization (DG) is about learning models that generalize well to new domains that are related to, but different from, the training domain(s). It is a fundamental problem in machine learning and has attracted much attention in recent years. A large number of approaches have been proposed. Different approaches are motivated from different perspectives, making it difficult to gain an overall understanding of the area. In this paper, we propose a causal framework for domain generalization and present an understanding of common DG approaches in the framework. Our work sheds new lights on the following questions: (1) What are the key ideas behind each DG method? (2) Why is it expected to improve generalization to new domains theoretically? (3) How are different DG methods related to each other and what are relative advantages and limitations? By providing a unified perspective on DG, we hope to help researchers better understand the underlying principles and develop more effective approaches for this critical problem in machine learning.
Two-Stage Holistic and Contrastive Explanation of Image Classification
Jun 10, 2023



The need to explain the output of a deep neural network classifier is now widely recognized. While previous methods typically explain a single class in the output, we advocate explaining the whole output, which is a probability distribution over multiple classes. A whole-output explanation can help a human user gain an overall understanding of model behaviour instead of only one aspect of it. It can also provide a natural framework where one can examine the evidence used to discriminate between competing classes, and thereby obtain contrastive explanations. In this paper, we propose a contrastive whole-output explanation (CWOX) method for image classification, and evaluate it using quantitative metrics and through human subject studies. The source code of CWOX is available at https://github.com/vaynexie/CWOX.
Gain without Pain: Recycling Reflected Energy from Wireless Powered RIS-aided Communications
Sep 27, 2022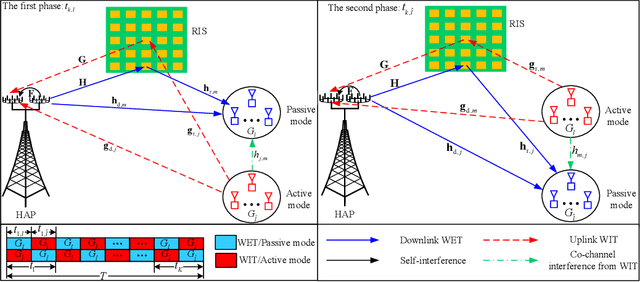
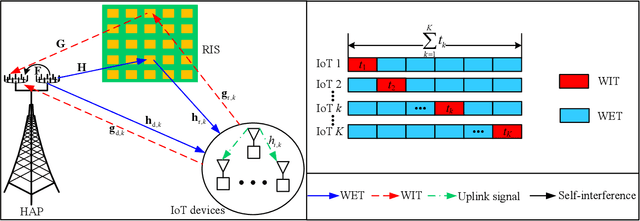
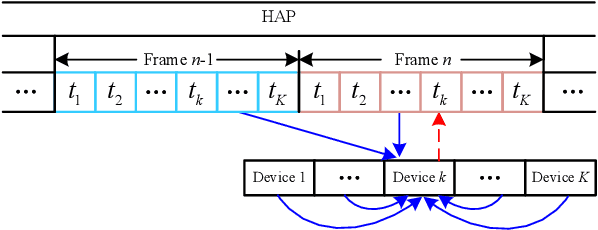
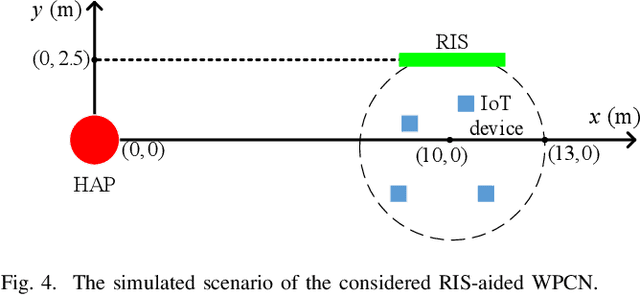
In this paper, we investigate and analyze energy recycling for a reconfigurable intelligent surface (RIS)-aided wireless-powered communication network. As opposed to the existing works where the energy harvested by Internet of things (IoT) devices only come from the power station, IoT devices are also allowed to recycle energy from other IoT devices. In particular, we propose group switching- and user switching-based protocols with time-division multiple access to evaluate the impact of energy recycling on system performance. Two different optimization problems are respectively formulated for maximizing the sum throughput by jointly optimizing the energy beamforming vectors, the transmit power, the transmission time, the receive beamforming vectors, the grouping factors, and the phase-shift matrices, where the constraints of the minimum throughput, the harvested energy, the maximum transmit power, the phase shift, the grouping, and the time allocation are taken into account. In light of the intractability of the above problems, we respectively develop two alternating optimization-based iterative algorithms by combining the successive convex approximation method and the penalty-based method to obtain corresponding sub-optimal solutions. Simulation results verify that the energy recycling-based mechanism can assist in enhancing the performance of IoT devices in terms of energy harvesting and information transmission. Besides, we also verify that the group switching-based algorithm can improve more sum throughput of IoT devices, and the user switching-based algorithm can harvest more energy.
A New Dataset and A Baseline Model for Breast Lesion Detection in Ultrasound Videos
Jul 01, 2022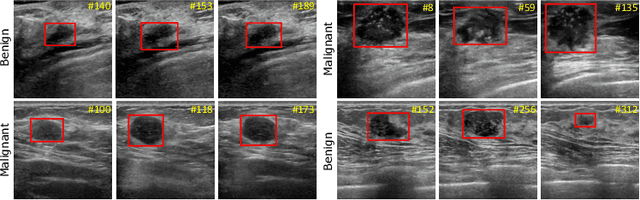
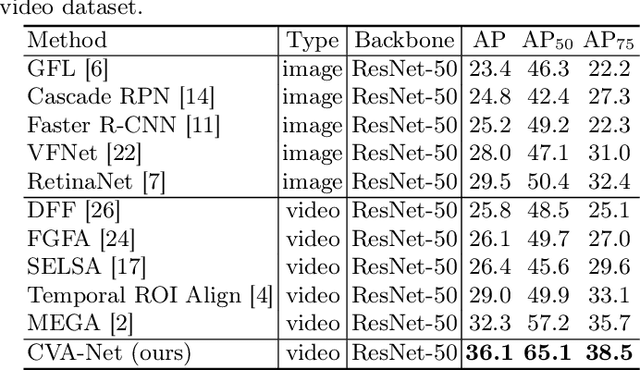
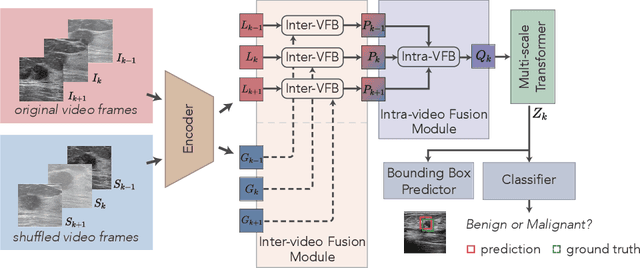
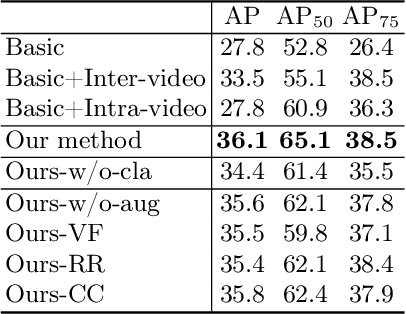
Breast lesion detection in ultrasound is critical for breast cancer diagnosis. Existing methods mainly rely on individual 2D ultrasound images or combine unlabeled video and labeled 2D images to train models for breast lesion detection. In this paper, we first collect and annotate an ultrasound video dataset (188 videos) for breast lesion detection. Moreover, we propose a clip-level and video-level feature aggregated network (CVA-Net) for addressing breast lesion detection in ultrasound videos by aggregating video-level lesion classification features and clip-level temporal features. The clip-level temporal features encode local temporal information of ordered video frames and global temporal information of shuffled video frames. In our CVA-Net, an inter-video fusion module is devised to fuse local features from original video frames and global features from shuffled video frames, and an intra-video fusion module is devised to learn the temporal information among adjacent video frames. Moreover, we learn video-level features to classify the breast lesions of the original video as benign or malignant lesions to further enhance the final breast lesion detection performance in ultrasound videos. Experimental results on our annotated dataset demonstrate that our CVA-Net clearly outperforms state-of-the-art methods. The corresponding code and dataset are publicly available at \url{https://github.com/jhl-Det/CVA-Net}.
* 11 pages, 4 figures
Example Perplexity
Mar 16, 2022
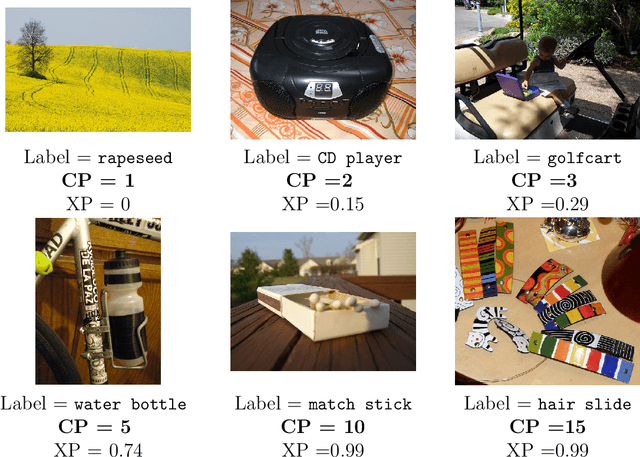

Some examples are easier for humans to classify than others. The same should be true for deep neural networks (DNNs). We use the term example perplexity to refer to the level of difficulty of classifying an example. In this paper, we propose a method to measure the perplexity of an example and investigate what factors contribute to high example perplexity. The related codes and resources are available at https://github.com/vaynexie/Example-Perplexity.
Deep Adaptive Network: An Efficient Deep Neural Network with Sparse Binary Connections
Apr 21, 2016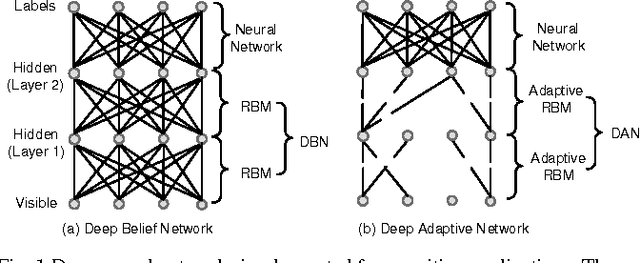
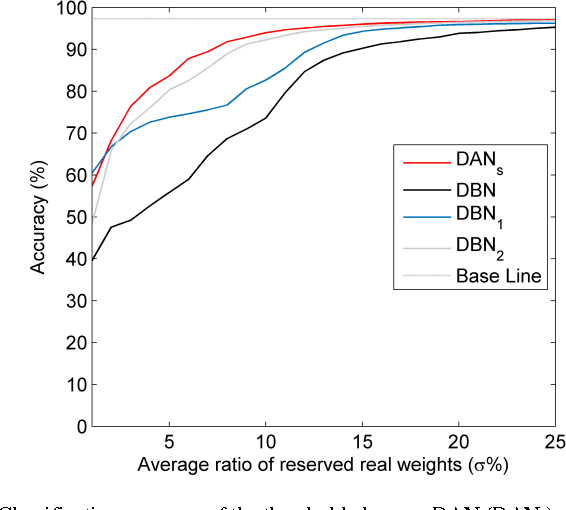
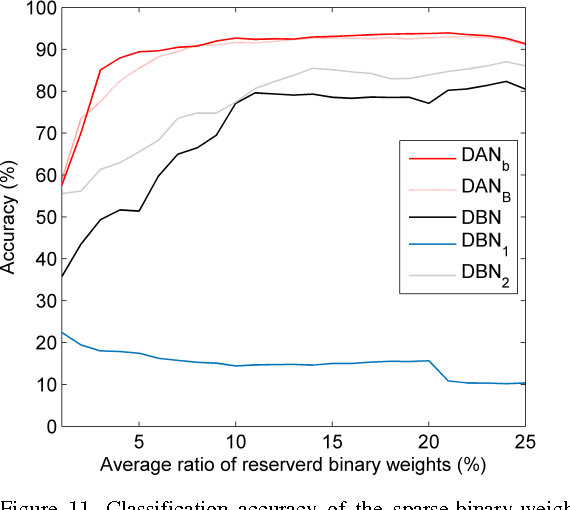
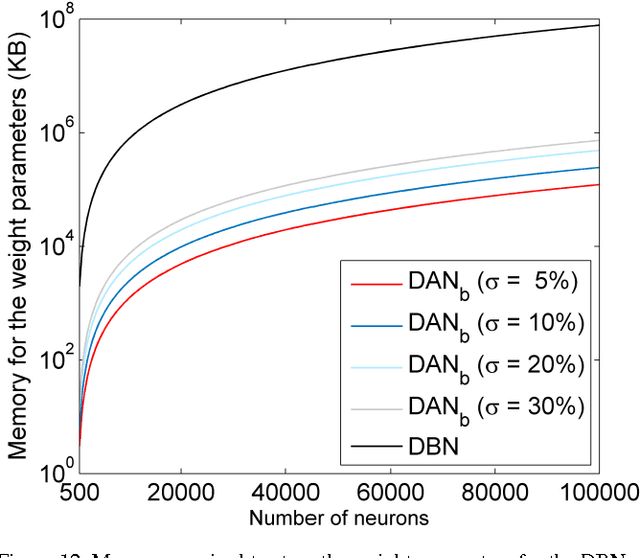
Deep neural networks are state-of-the-art models for understanding the content of images, video and raw input data. However, implementing a deep neural network in embedded systems is a challenging task, because a typical deep neural network, such as a Deep Belief Network using 128x128 images as input, could exhaust Giga bytes of memory and result in bandwidth and computing bottleneck. To address this challenge, this paper presents a hardware-oriented deep learning algorithm, named as the Deep Adaptive Network, which attempts to exploit the sparsity in the neural connections. The proposed method adaptively reduces the weights associated with negligible features to zero, leading to sparse feedforward network architecture. Furthermore, since the small proportion of important weights are significantly larger than zero, they can be robustly thresholded and represented using single-bit integers (-1 and +1), leading to implementations of deep neural networks with sparse and binary connections. Our experiments showed that, for the application of recognizing MNIST handwritten digits, the features extracted by a two-layer Deep Adaptive Network with about 25% reserved important connections achieved 97.2% classification accuracy, which was almost the same with the standard Deep Belief Network (97.3%). Furthermore, for efficient hardware implementations, the sparse-and-binary-weighted deep neural network could save about 99.3% memory and 99.9% computation units without significant loss of classification accuracy for pattern recognition applications.