 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization Loss Re-Learning Method
May 30, 2019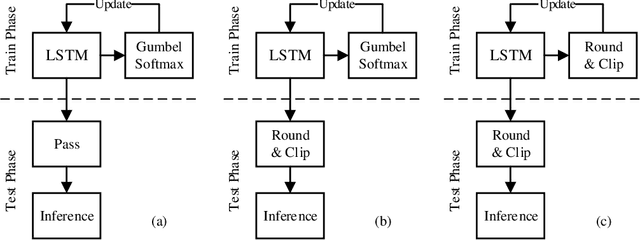

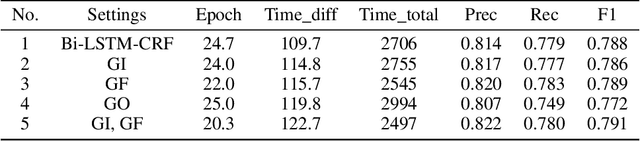
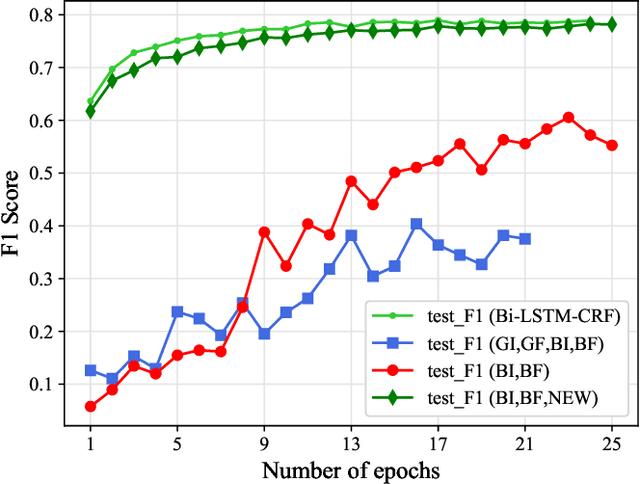
In order to quantize the gate parameters of the LSTM (Long Short-Term Memory) neural network model with almost no recognition performance degraded, a new quantization method named Quantization Loss Re-Learn Method is proposed in this paper. The method does lossy quantization on gate parameters during training iterations, and the weight parameters learn to offset the loss of gate parameters quantization by adjusting the gradient in back propagation during weight parameters optimization. We proved the effectiveness of this method through theoretical derivation and experiments. The gate parameters had been quantized to 0, 0.5, 1 three values, and on the Named Entity Recognition dataset, the F1 score of the model with the new quantization method on gate parameters decreased by only 0.7% compared to the baseline model.
Deep Adaptive Network: An Efficient Deep Neural Network with Sparse Binary Connections
Apr 21, 2016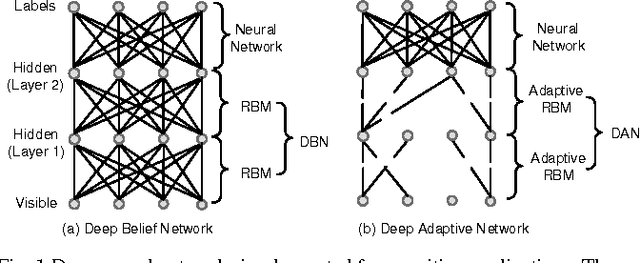
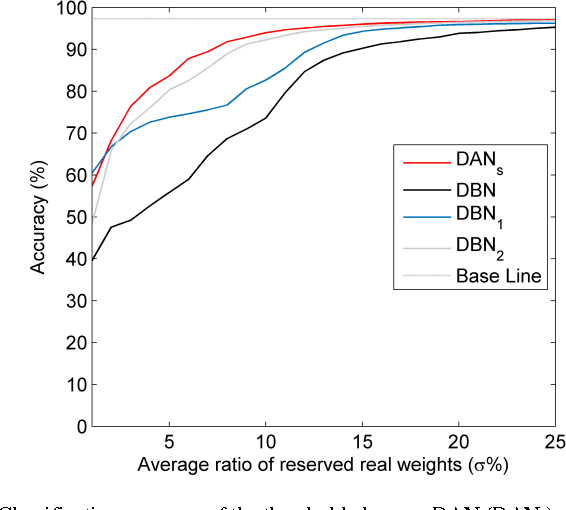
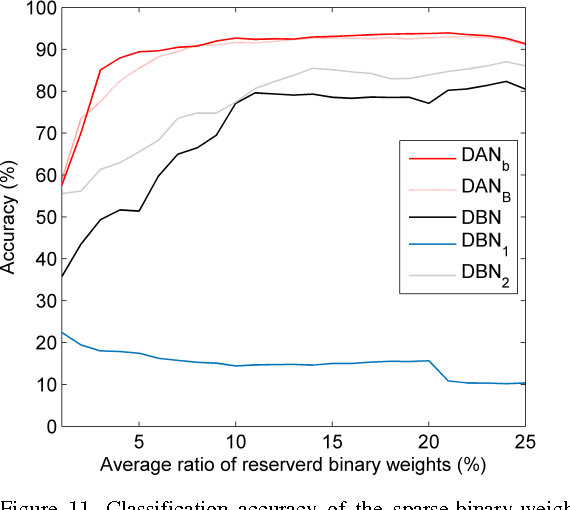
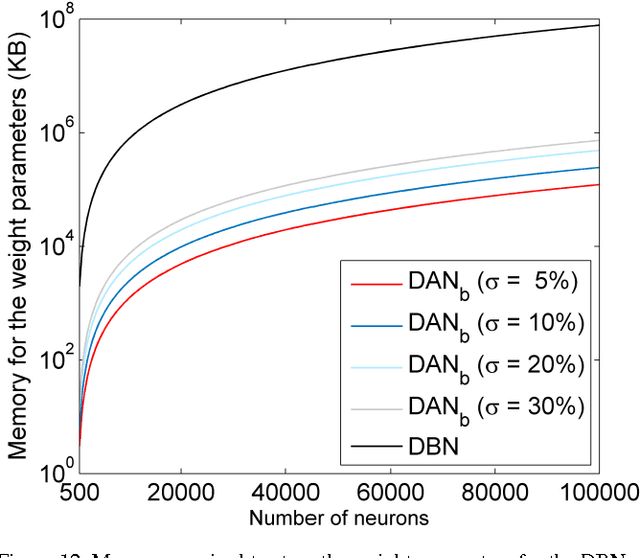
Deep neural networks are state-of-the-art models for understanding the content of images, video and raw input data. However, implementing a deep neural network in embedded systems is a challenging task, because a typical deep neural network, such as a Deep Belief Network using 128x128 images as input, could exhaust Giga bytes of memory and result in bandwidth and computing bottleneck. To address this challenge, this paper presents a hardware-oriented deep learning algorithm, named as the Deep Adaptive Network, which attempts to exploit the sparsity in the neural connections. The proposed method adaptively reduces the weights associated with negligible features to zero, leading to sparse feedforward network architecture. Furthermore, since the small proportion of important weights are significantly larger than zero, they can be robustly thresholded and represented using single-bit integers (-1 and +1), leading to implementations of deep neural networks with sparse and binary connections. Our experiments showed that, for the application of recognizing MNIST handwritten digits, the features extracted by a two-layer Deep Adaptive Network with about 25% reserved important connections achieved 97.2% classification accuracy, which was almost the same with the standard Deep Belief Network (97.3%). Furthermore, for efficient hardware implementations, the sparse-and-binary-weighted deep neural network could save about 99.3% memory and 99.9% computation units without significant loss of classification accuracy for pattern recognition applications.