 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOViP: Online Vision-Language Preference Learning
May 21, 2025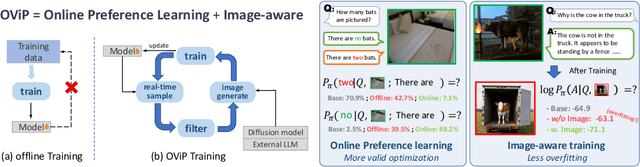
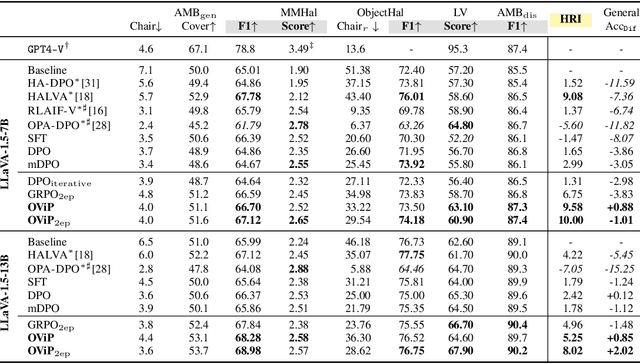
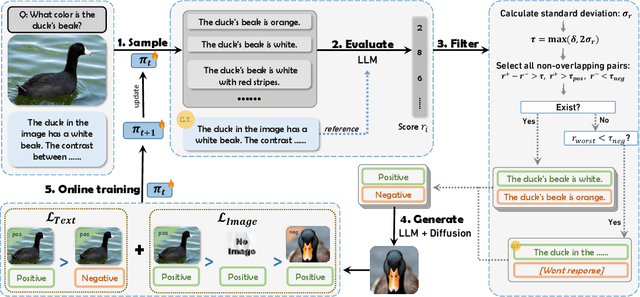

Large vision-language models (LVLMs) remain vulnerable to hallucination, often generating content misaligned with visual inputs. While recent approaches advance multi-modal Direct Preference Optimization (DPO) to mitigate hallucination, they typically rely on predefined or randomly edited negative samples that fail to reflect actual model errors, limiting training efficacy. In this work, we propose an Online Vision-language Preference Learning (OViP) framework that dynamically constructs contrastive training data based on the model's own hallucinated outputs. By identifying semantic differences between sampled response pairs and synthesizing negative images using a diffusion model, OViP generates more relevant supervision signals in real time. This failure-driven training enables adaptive alignment of both textual and visual preferences. Moreover, we refine existing evaluation protocols to better capture the trade-off between hallucination suppression and expressiveness. Experiments on hallucination and general benchmarks demonstrate that OViP effectively reduces hallucinations while preserving core multi-modal capabilities.
How Jailbreak Defenses Work and Ensemble? A Mechanistic Investigation
Feb 20, 2025Jailbreak attacks, where harmful prompts bypass generative models' built-in safety, raise serious concerns about model vulnerability. While many defense methods have been proposed, the trade-offs between safety and helpfulness, and their application to Large Vision-Language Models (LVLMs), are not well understood. This paper systematically examines jailbreak defenses by reframing the standard generation task as a binary classification problem to assess model refusal tendencies for both harmful and benign queries. We identify two key defense mechanisms: safety shift, which increases refusal rates across all queries, and harmfulness discrimination, which improves the model's ability to distinguish between harmful and benign inputs. Using these mechanisms, we develop two ensemble defense strategies-inter-mechanism ensembles and intra-mechanism ensembles-to balance safety and helpfulness. Experiments on the MM-SafetyBench and MOSSBench datasets with LLaVA-1.5 models show that these strategies effectively improve model safety or optimize the trade-off between safety and helpfulness.
Multi-Agent Simulator Drives Language Models for Legal Intensive Interaction
Feb 08, 2025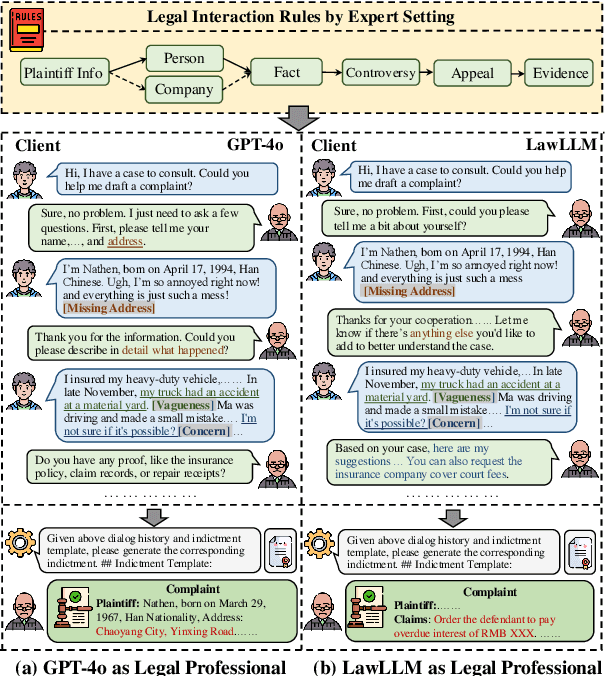
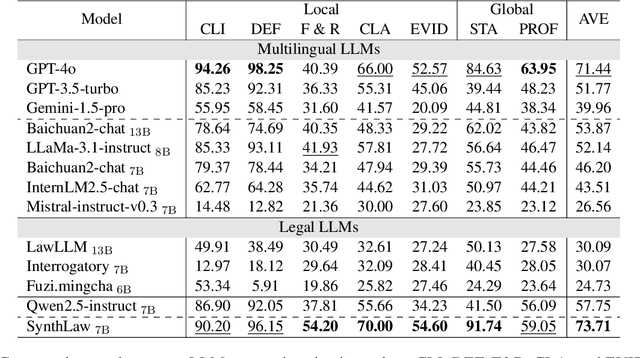
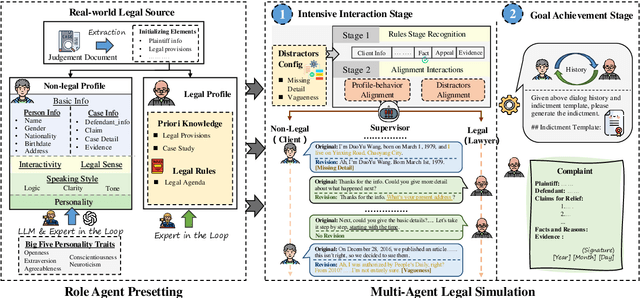
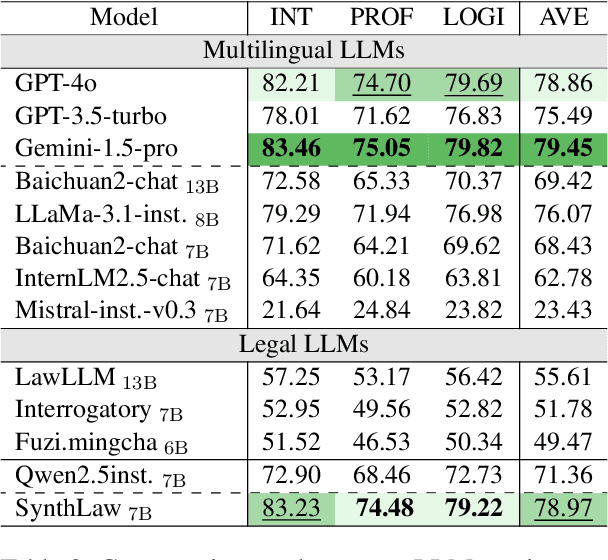
Large Language Models (LLMs) have significantly advanced legal intelligence, but the scarcity of scenario data impedes the progress toward interactive legal scenarios. This paper introduces a Multi-agent Legal Simulation Driver (MASER) to scalably generate synthetic data by simulating interactive legal scenarios. Leveraging real-legal case sources, MASER ensures the consistency of legal attributes between participants and introduces a supervisory mechanism to align participants' characters and behaviors as well as addressing distractions. A Multi-stage Interactive Legal Evaluation (MILE) benchmark is further constructed to evaluate LLMs' performance in dynamic legal scenarios. Extensive experiments confirm the effectiveness of our framework.
HAF-RM: A Hybrid Alignment Framework for Reward Model Training
Jul 04, 2024The reward model has become increasingly important in alignment, assessment, and data construction for large language models (LLMs). Most existing researchers focus on enhancing reward models through data improvements, following the conventional training framework for reward models that directly optimizes the predicted rewards. In this paper, we propose a hybrid alignment framework HaF-RM for reward model training by introducing an additional constraint on token-level policy probabilities in addition to the reward score. It can simultaneously supervise the internal preference model at the token level and optimize the mapping layer of the reward model at the sequence level. Theoretical justifications and experiment results on five datasets show the validity and effectiveness of our proposed hybrid framework for training a high-quality reward model. By decoupling the reward modeling procedure and incorporating hybrid supervision, our HaF-RM framework offers a principled and effective approach to enhancing the performance and alignment of reward models, a critical component in the responsible development of powerful language models. We release our code at https://haf-rm.github.io.
ALaRM: Align Language Models via Hierarchical Rewards Modeling
Mar 16, 2024We introduce ALaRM, the first framework modeling hierarchical rewards in reinforcement learning from human feedback (RLHF), which is designed to enhance the alignment of large language models (LLMs) with human preferences. The framework addresses the limitations of current alignment approaches, which often struggle with the inconsistency and sparsity of human supervision signals, by integrating holistic rewards with aspect-specific rewards. This integration enables more precise and consistent guidance of language models towards desired outcomes, particularly in complex and open text generation tasks. By employing a methodology that filters and combines multiple rewards based on their consistency, the framework provides a reliable mechanism for improving model alignment. We validate our approach through applications in long-form question answering and machine translation tasks, employing gpt-3.5-turbo for pairwise comparisons, and demonstrate improvements over existing baselines. Our work underscores the effectiveness of hierarchical rewards modeling in refining LLM training processes for better human preference alignment. We release our code at https://ALaRM-fdu.github.io.
DISC-LawLLM: Fine-tuning Large Language Models for Intelligent Legal Services
Sep 23, 2023We propose DISC-LawLLM, an intelligent legal system utilizing large language models (LLMs) to provide a wide range of legal services. We adopt legal syllogism prompting strategies to construct supervised fine-tuning datasets in the Chinese Judicial domain and fine-tune LLMs with legal reasoning capability. We augment LLMs with a retrieval module to enhance models' ability to access and utilize external legal knowledge. A comprehensive legal benchmark, DISC-Law-Eval, is presented to evaluate intelligent legal systems from both objective and subjective dimensions. Quantitative and qualitative results on DISC-Law-Eval demonstrate the effectiveness of our system in serving various users across diverse legal scenarios. The detailed resources are available at https://github.com/FudanDISC/DISC-LawLLM.
Pitch Preservation In Singing Voice Synthesis
Oct 12, 2021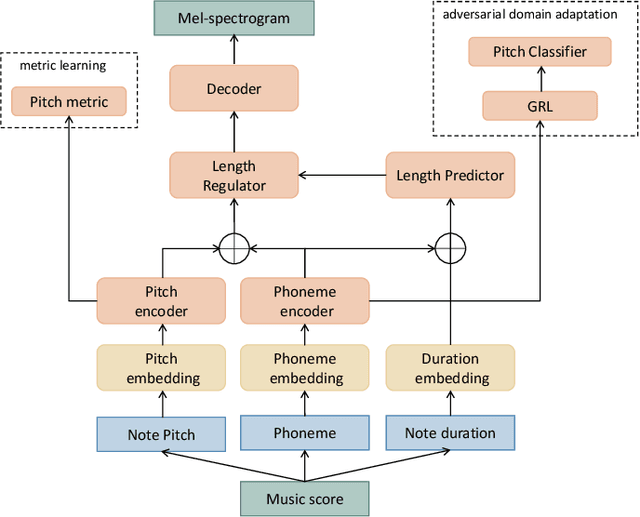
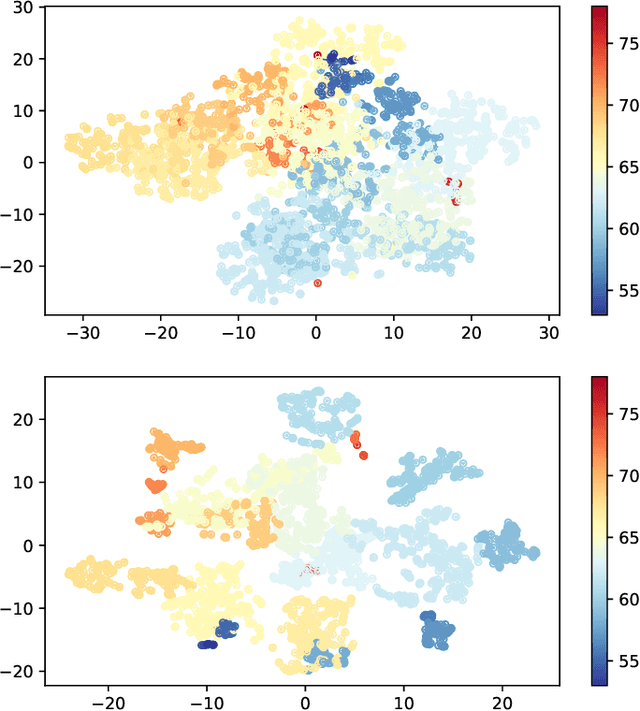
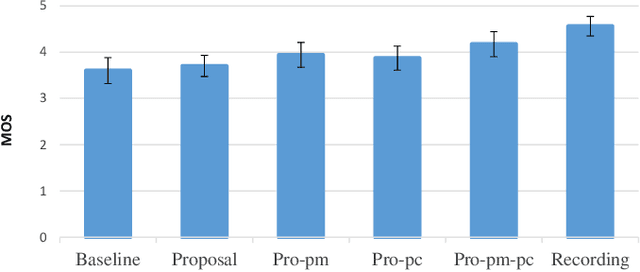
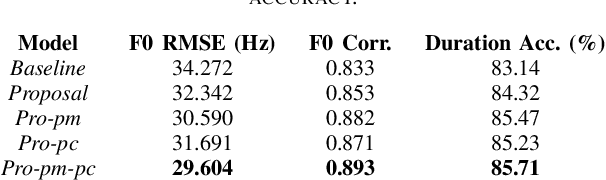
Suffering from limited singing voice corpus, existing singing voice synthesis (SVS) methods that build encoder-decoder neural networks to directly generate spectrogram could lead to out-of-tune issues during the inference phase. To attenuate these issues, this paper presents a novel acoustic model with independent pitch encoder and phoneme encoder, which disentangles the phoneme and pitch information from music score to fully utilize the corpus. Specifically, according to equal temperament theory, the pitch encoder is constrained by a pitch metric loss that maps distances between adjacent input pitches into corresponding frequency multiples between the encoder outputs. For the phoneme encoder, based on the analysis that same phonemes corresponding to varying pitches can produce similar pronunciations, this encoder is followed by an adversarially trained pitch classifier to enforce the identical phonemes with different pitches mapping into the same phoneme feature space. By these means, the sparse phonemes and pitches in original input spaces can be transformed into more compact feature spaces respectively, where the same elements cluster closely and cooperate mutually to enhance synthesis quality. Then, the outputs of the two encoders are summed together to pass through the following decoder in the acoustic model. Experimental results indicate that the proposed approaches can characterize intrinsic structure between pitch inputs to obtain better pitch synthesis accuracy and achieve superior singing synthesis performance against the advanced baseline system.
Deep Adaptive Network: An Efficient Deep Neural Network with Sparse Binary Connections
Apr 21, 2016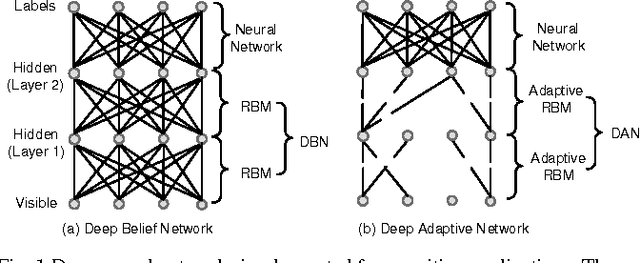
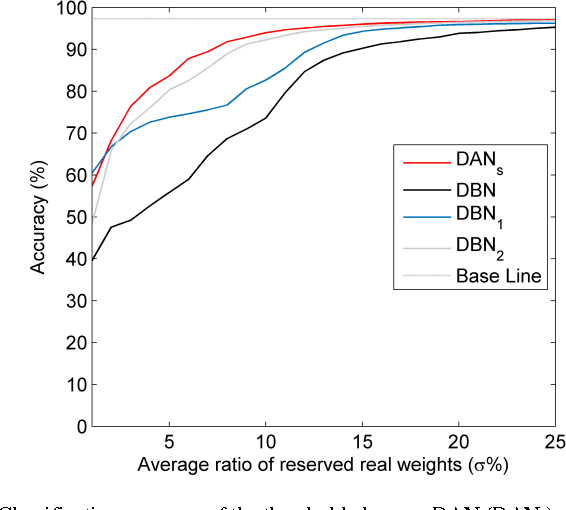
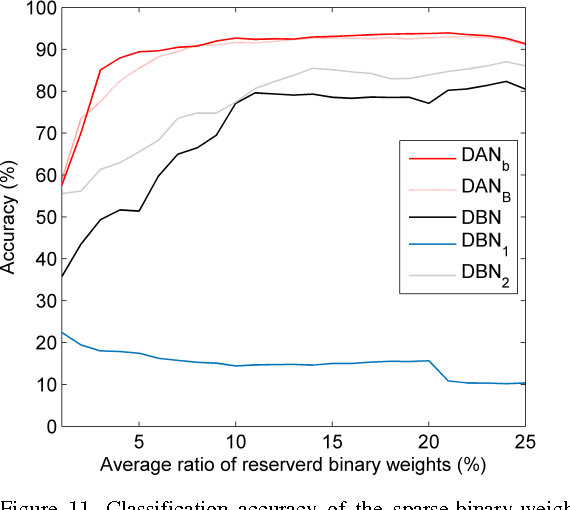
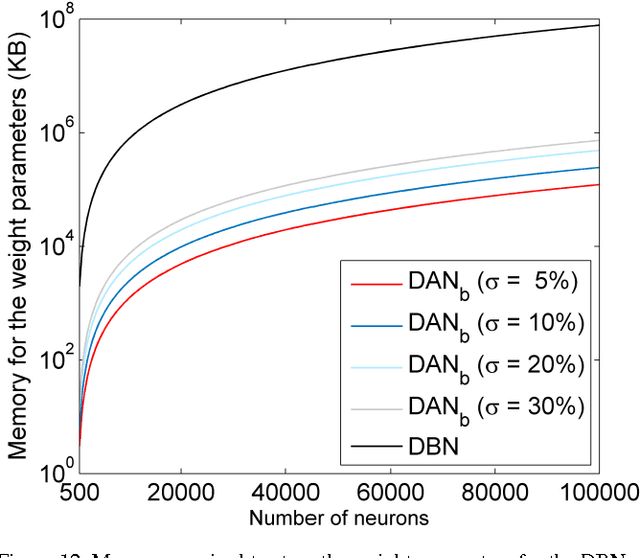
Deep neural networks are state-of-the-art models for understanding the content of images, video and raw input data. However, implementing a deep neural network in embedded systems is a challenging task, because a typical deep neural network, such as a Deep Belief Network using 128x128 images as input, could exhaust Giga bytes of memory and result in bandwidth and computing bottleneck. To address this challenge, this paper presents a hardware-oriented deep learning algorithm, named as the Deep Adaptive Network, which attempts to exploit the sparsity in the neural connections. The proposed method adaptively reduces the weights associated with negligible features to zero, leading to sparse feedforward network architecture. Furthermore, since the small proportion of important weights are significantly larger than zero, they can be robustly thresholded and represented using single-bit integers (-1 and +1), leading to implementations of deep neural networks with sparse and binary connections. Our experiments showed that, for the application of recognizing MNIST handwritten digits, the features extracted by a two-layer Deep Adaptive Network with about 25% reserved important connections achieved 97.2% classification accuracy, which was almost the same with the standard Deep Belief Network (97.3%). Furthermore, for efficient hardware implementations, the sparse-and-binary-weighted deep neural network could save about 99.3% memory and 99.9% computation units without significant loss of classification accuracy for pattern recognition applications.