 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurrogate Ensemble in Expensive Multi-Objective Optimization via Deep Q-Learning
Jan 31, 2026Surrogate-assisted Evolutionary Algorithms~(SAEAs) have shown promising robustness in solving expensive optimization problems. A key aspect that impacts SAEAs' effectiveness is surrogate model selection, which in existing works is predominantly decided by human developer. Such human-made design choice introduces strong bias into SAEAs and may hurt their expected performance on out-of-scope tasks. In this paper, we propose a reinforcement learning-assisted ensemble framework, termed as SEEMOO, which is capable of scheduling different surrogate models within a single optimization process, hence boosting the overall optimization performance in a cooperative paradigm. Specifically, we focus on expensive multi-objective optimization problems, where multiple objective functions shape a compositional landscape and hence challenge surrogate selection. SEEMOO comprises following core designs: 1) A pre-collected model pool that maintains different surrogate models; 2) An attention-based state-extractor supports universal optimization state representation of problems with varied objective numbers; 3) a deep Q-network serves as dynamic surrogate selector: Given the optimization state, it selects desired surrogate model for current-step evaluation. SEEMOO is trained to maximize the overall optimization performance under a training problem distribution. Extensive benchmark results demonstrate SEEMOO's surrogate ensemble paradigm boosts the optimization performance of single-surrogate baselines. Further ablation studies underscore the importance of SEEMOO's design components.
3D CoCa v2: Contrastive Learners with Test-Time Search for Generalizable Spatial Intelligence
Jan 10, 2026Spatial intelligence refers to the ability to perceive, reason about, and describe objects and their relationships within three-dimensional environments, forming a foundation for embodied perception and scene understanding. 3D captioning aims to describe 3D scenes in natural language; however, it remains challenging due to the sparsity and irregularity of point clouds and, more critically, the weak grounding and limited out-of-distribution (OOD) generalization of existing captioners across drastically different environments, including indoor and outdoor 3D scenes. To address this challenge, we propose 3D CoCa v2, a generalizable 3D captioning framework that unifies contrastive vision-language learning with 3D caption generation and further improves robustness via test-time search (TTS) without updating the captioner parameters. 3D CoCa v2 builds on a frozen CLIP-based semantic prior, a spatially-aware 3D scene encoder for geometry, and a multimodal decoder jointly optimized with contrastive and captioning objectives, avoiding external detectors or handcrafted proposals. At inference, TTS produces diverse caption candidates and performs reward-guided selection using a compact scene summary. Experiments show improvements over 3D CoCa of +1.50 CIDEr@0.5IoU on ScanRefer and +1.61 CIDEr@0.5IoU on Nr3D, and +3.8 CIDEr@0.25 in zero-shot OOD evaluation on TOD3Cap. Code will be released at https://github.com/AIGeeksGroup/3DCoCav2.
OpenGround: Active Cognition-based Reasoning for Open-World 3D Visual Grounding
Dec 31, 20253D visual grounding aims to locate objects based on natural language descriptions in 3D scenes. Existing methods rely on a pre-defined Object Lookup Table (OLT) to query Visual Language Models (VLMs) for reasoning about object locations, which limits the applications in scenarios with undefined or unforeseen targets. To address this problem, we present OpenGround, a novel zero-shot framework for open-world 3D visual grounding. Central to OpenGround is the Active Cognition-based Reasoning (ACR) module, which is designed to overcome the fundamental limitation of pre-defined OLTs by progressively augmenting the cognitive scope of VLMs. The ACR module performs human-like perception of the target via a cognitive task chain and actively reasons about contextually relevant objects, thereby extending VLM cognition through a dynamically updated OLT. This allows OpenGround to function with both pre-defined and open-world categories. We also propose a new dataset named OpenTarget, which contains over 7000 object-description pairs to evaluate our method in open-world scenarios. Extensive experiments demonstrate that OpenGround achieves competitive performance on Nr3D, state-of-the-art on ScanRefer, and delivers a substantial 17.6% improvement on OpenTarget. Project Page at https://why-102.github.io/openground.io/.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
DC-Scene: Data-Centric Learning for 3D Scene Understanding
May 21, 20253D scene understanding plays a fundamental role in vision applications such as robotics, autonomous driving, and augmented reality. However, advancing learning-based 3D scene understanding remains challenging due to two key limitations: (1) the large scale and complexity of 3D scenes lead to higher computational costs and slower training compared to 2D counterparts; and (2) high-quality annotated 3D datasets are significantly scarcer than those available for 2D vision. These challenges underscore the need for more efficient learning paradigms. In this work, we propose DC-Scene, a data-centric framework tailored for 3D scene understanding, which emphasizes enhancing data quality and training efficiency. Specifically, we introduce a CLIP-driven dual-indicator quality (DIQ) filter, combining vision-language alignment scores with caption-loss perplexity, along with a curriculum scheduler that progressively expands the training pool from the top 25% to 75% of scene-caption pairs. This strategy filters out noisy samples and significantly reduces dependence on large-scale labeled 3D data. Extensive experiments on ScanRefer and Nr3D demonstrate that DC-Scene achieves state-of-the-art performance (86.1 CIDEr with the top-75% subset vs. 85.4 with the full dataset) while reducing training cost by approximately two-thirds, confirming that a compact set of high-quality samples can outperform exhaustive training. Code will be available at https://github.com/AIGeeksGroup/DC-Scene.
3D CoCa: Contrastive Learners are 3D Captioners
Apr 13, 20253D captioning, which aims to describe the content of 3D scenes in natural language, remains highly challenging due to the inherent sparsity of point clouds and weak cross-modal alignment in existing methods. To address these challenges, we propose 3D CoCa, a novel unified framework that seamlessly combines contrastive vision-language learning with 3D caption generation in a single architecture. Our approach leverages a frozen CLIP vision-language backbone to provide rich semantic priors, a spatially-aware 3D scene encoder to capture geometric context, and a multi-modal decoder to generate descriptive captions. Unlike prior two-stage methods that rely on explicit object proposals, 3D CoCa jointly optimizes contrastive and captioning objectives in a shared feature space, eliminating the need for external detectors or handcrafted proposals. This joint training paradigm yields stronger spatial reasoning and richer semantic grounding by aligning 3D and textual representations. Extensive experiments on the ScanRefer and Nr3D benchmarks demonstrate that 3D CoCa significantly outperforms current state-of-the-arts by 10.2% and 5.76% in CIDEr at 0.5IoU, respectively. Code will be available at https://github.com/AIGeeksGroup/3DCoCa.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Multi-Agent Simulator Drives Language Models for Legal Intensive Interaction
Feb 08, 2025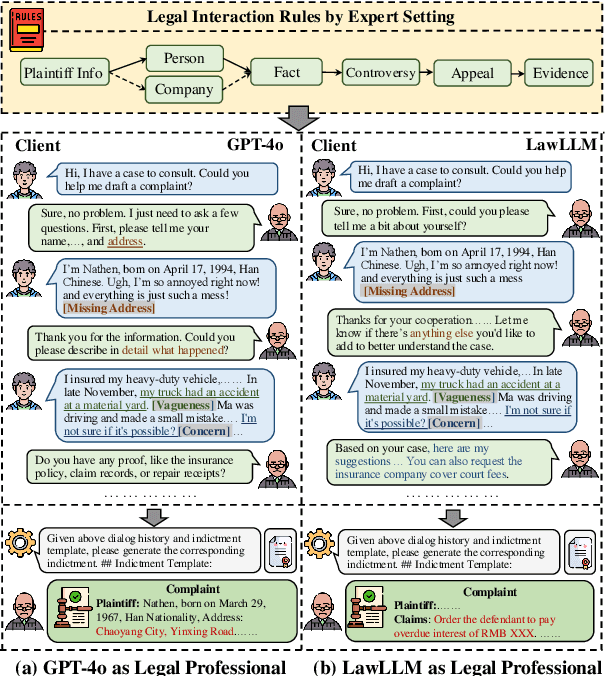
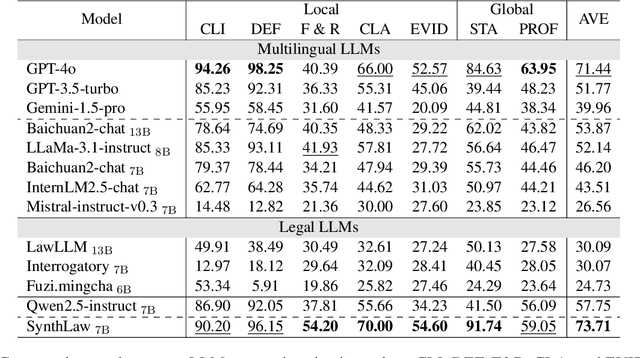
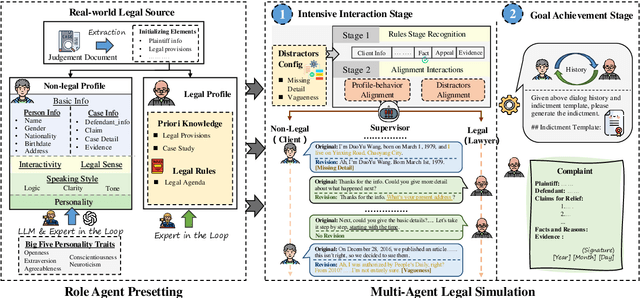
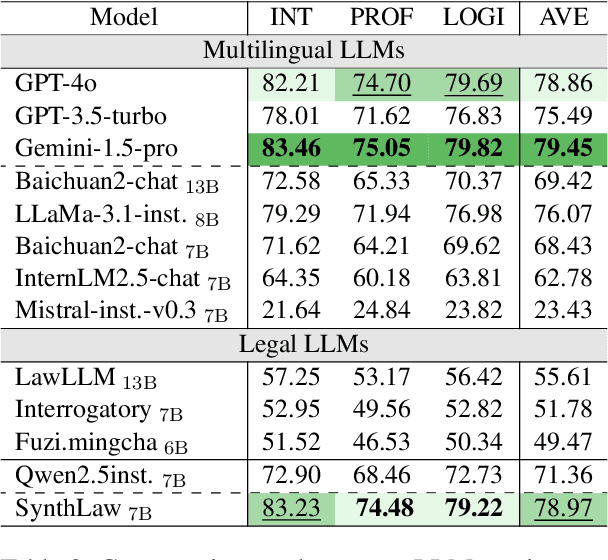
Large Language Models (LLMs) have significantly advanced legal intelligence, but the scarcity of scenario data impedes the progress toward interactive legal scenarios. This paper introduces a Multi-agent Legal Simulation Driver (MASER) to scalably generate synthetic data by simulating interactive legal scenarios. Leveraging real-legal case sources, MASER ensures the consistency of legal attributes between participants and introduces a supervisory mechanism to align participants' characters and behaviors as well as addressing distractions. A Multi-stage Interactive Legal Evaluation (MILE) benchmark is further constructed to evaluate LLMs' performance in dynamic legal scenarios. Extensive experiments confirm the effectiveness of our framework.
RLEMMO: Evolutionary Multimodal Optimization Assisted By Deep Reinforcement Learning
Apr 12, 2024
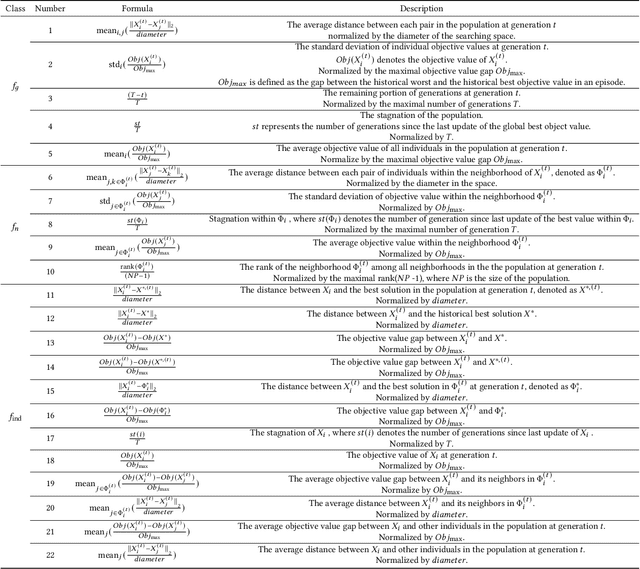


Solving multimodal optimization problems (MMOP) requires finding all optimal solutions, which is challenging in limited function evaluations. Although existing works strike the balance of exploration and exploitation through hand-crafted adaptive strategies, they require certain expert knowledge, hence inflexible to deal with MMOP with different properties. In this paper, we propose RLEMMO, a Meta-Black-Box Optimization framework, which maintains a population of solutions and incorporates a reinforcement learning agent for flexibly adjusting individual-level searching strategies to match the up-to-date optimization status, hence boosting the search performance on MMOP. Concretely, we encode landscape properties and evolution path information into each individual and then leverage attention networks to advance population information sharing. With a novel reward mechanism that encourages both quality and diversity, RLEMMO can be effectively trained using a policy gradient algorithm. The experimental results on the CEC2013 MMOP benchmark underscore the competitive optimization performance of RLEMMO against several strong baselines.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.