 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaDual: Balancing Personalization and Objectivity via Adaptive Reasoning
Jan 13, 2026As users increasingly expect LLMs to align with their preferences, personalized information becomes valuable. However, personalized information can be a double-edged sword: it can improve interaction but may compromise objectivity and factual correctness, especially when it is misaligned with the question. To alleviate this problem, we propose PersonaDual, a framework that supports both general-purpose objective reasoning and personalized reasoning in a single model, and adaptively switches modes based on context. PersonaDual is first trained with SFT to learn two reasoning patterns, and then further optimized via reinforcement learning with our proposed DualGRPO to improve mode selection. Experiments on objective and personalized benchmarks show that PersonaDual preserves the benefits of personalization while reducing interference, achieving near interference-free performance and better leveraging helpful personalized signals to improve objective problem-solving.
Multi-Agent Simulator Drives Language Models for Legal Intensive Interaction
Feb 08, 2025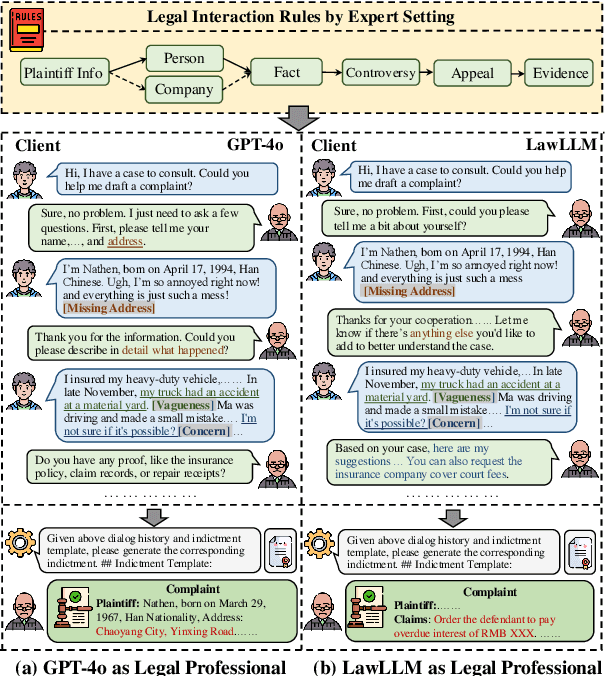
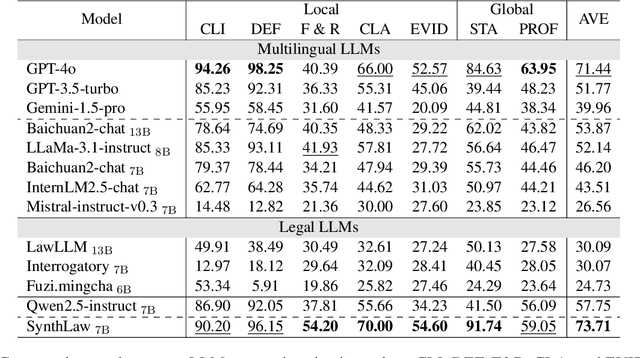
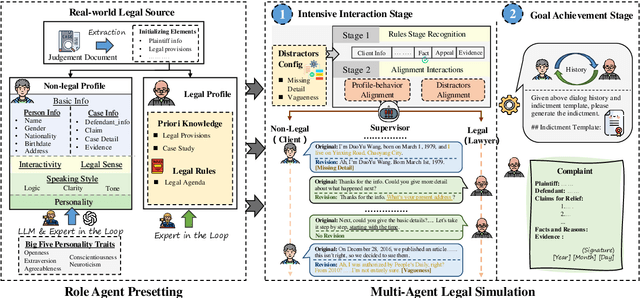
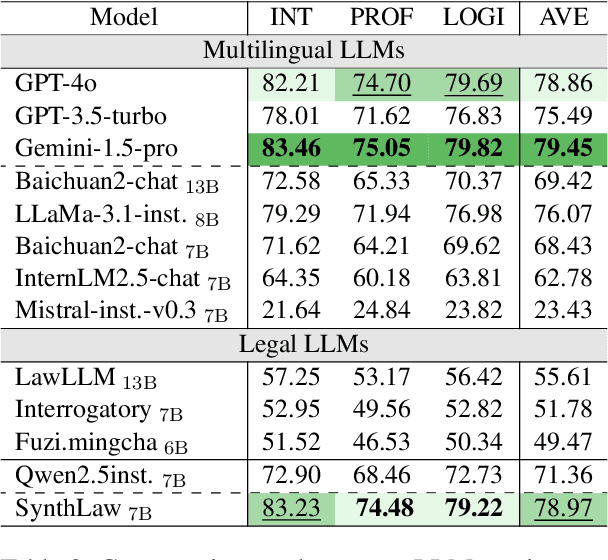
Large Language Models (LLMs) have significantly advanced legal intelligence, but the scarcity of scenario data impedes the progress toward interactive legal scenarios. This paper introduces a Multi-agent Legal Simulation Driver (MASER) to scalably generate synthetic data by simulating interactive legal scenarios. Leveraging real-legal case sources, MASER ensures the consistency of legal attributes between participants and introduces a supervisory mechanism to align participants' characters and behaviors as well as addressing distractions. A Multi-stage Interactive Legal Evaluation (MILE) benchmark is further constructed to evaluate LLMs' performance in dynamic legal scenarios. Extensive experiments confirm the effectiveness of our framework.
Synergistic Multi-Agent Framework with Trajectory Learning for Knowledge-Intensive Tasks
Jul 13, 2024Recent advancements in Large Language Models (LLMs) have led to significant breakthroughs in various natural language processing tasks. However, generating factually consistent responses in knowledge-intensive scenarios remains a challenge due to issues such as hallucination, difficulty in acquiring long-tailed knowledge, and limited memory expansion. This paper introduces SMART, a novel multi-agent framework that leverages external knowledge to enhance the interpretability and factual consistency of LLM-generated responses. SMART comprises four specialized agents, each performing a specific sub-trajectory action to navigate complex knowledge-intensive tasks. We propose a multi-agent co-training paradigm, Long- and Short-Trajectory Learning, which ensures synergistic collaboration among agents while maintaining fine-grained execution by each agent. Extensive experiments on 5 tasks demonstrate SMART's superior performance compared to previous widely adopted methods.
HAF-RM: A Hybrid Alignment Framework for Reward Model Training
Jul 04, 2024The reward model has become increasingly important in alignment, assessment, and data construction for large language models (LLMs). Most existing researchers focus on enhancing reward models through data improvements, following the conventional training framework for reward models that directly optimizes the predicted rewards. In this paper, we propose a hybrid alignment framework HaF-RM for reward model training by introducing an additional constraint on token-level policy probabilities in addition to the reward score. It can simultaneously supervise the internal preference model at the token level and optimize the mapping layer of the reward model at the sequence level. Theoretical justifications and experiment results on five datasets show the validity and effectiveness of our proposed hybrid framework for training a high-quality reward model. By decoupling the reward modeling procedure and incorporating hybrid supervision, our HaF-RM framework offers a principled and effective approach to enhancing the performance and alignment of reward models, a critical component in the responsible development of powerful language models. We release our code at https://haf-rm.github.io.
DISC-LawLLM: Fine-tuning Large Language Models for Intelligent Legal Services
Sep 23, 2023We propose DISC-LawLLM, an intelligent legal system utilizing large language models (LLMs) to provide a wide range of legal services. We adopt legal syllogism prompting strategies to construct supervised fine-tuning datasets in the Chinese Judicial domain and fine-tune LLMs with legal reasoning capability. We augment LLMs with a retrieval module to enhance models' ability to access and utilize external legal knowledge. A comprehensive legal benchmark, DISC-Law-Eval, is presented to evaluate intelligent legal systems from both objective and subjective dimensions. Quantitative and qualitative results on DISC-Law-Eval demonstrate the effectiveness of our system in serving various users across diverse legal scenarios. The detailed resources are available at https://github.com/FudanDISC/DISC-LawLLM.