 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Activation Patterns: A Weight-Based Out-of-Context Explanation of Sparse Autoencoder Features
Jan 30, 2026Sparse autoencoders (SAEs) have emerged as a powerful technique for decomposing language model representations into interpretable features. Current interpretation methods infer feature semantics from activation patterns, but overlook that features are trained to reconstruct activations that serve computational roles in the forward pass. We introduce a novel weight-based interpretation framework that measures functional effects through direct weight interactions, requiring no activation data. Through three experiments on Gemma-2 and Llama-3.1 models, we demonstrate that (1) 1/4 of features directly predict output tokens, (2) features actively participate in attention mechanisms with depth-dependent structure, and (3) semantic and non-semantic feature populations exhibit distinct distribution profiles in attention circuits. Our analysis provides the missing out-of-context half of SAE feature interpretability.
Efficient Thought Space Exploration through Strategic Intervention
Nov 13, 2025While large language models (LLMs) demonstrate emerging reasoning capabilities, current inference-time expansion methods incur prohibitive computational costs by exhaustive sampling. Through analyzing decoding trajectories, we observe that most next-token predictions align well with the golden output, except for a few critical tokens that lead to deviations. Inspired by this phenomenon, we propose a novel Hint-Practice Reasoning (HPR) framework that operationalizes this insight through two synergistic components: 1) a hinter (powerful LLM) that provides probabilistic guidance at critical decision points, and 2) a practitioner (efficient smaller model) that executes major reasoning steps. The framework's core innovation lies in Distributional Inconsistency Reduction (DIR), a theoretically-grounded metric that dynamically identifies intervention points by quantifying the divergence between practitioner's reasoning trajectory and hinter's expected distribution in a tree-structured probabilistic space. Through iterative tree updates guided by DIR, HPR reweights promising reasoning paths while deprioritizing low-probability branches. Experiments across arithmetic and commonsense reasoning benchmarks demonstrate HPR's state-of-the-art efficiency-accuracy tradeoffs: it achieves comparable performance to self-consistency and MCTS baselines while decoding only 1/5 tokens, and outperforms existing methods by at most 5.1% absolute accuracy while maintaining similar or lower FLOPs.
Staying in the Sweet Spot: Responsive Reasoning Evolution via Capability-Adaptive Hint Scaffolding
Sep 08, 2025Reinforcement learning with verifiable rewards (RLVR) has achieved remarkable success in enhancing the reasoning capabilities of large language models (LLMs). However, existing RLVR methods often suffer from exploration inefficiency due to mismatches between the training data's difficulty and the model's capability. LLMs fail to discover viable reasoning paths when problems are overly difficult, while learning little new capability when problems are too simple. In this work, we formalize the impact of problem difficulty by quantifying the relationship between loss descent speed and rollout accuracy. Building on this analysis, we propose SEELE, a novel supervision-aided RLVR framework that dynamically adjusts problem difficulty to stay within the high-efficiency region. SEELE augments each training sample by appending a hint (part of a full solution) after the original problem. Unlike previous hint-based approaches, SEELE deliberately and adaptively adjusts the hint length for each problem to achieve an optimal difficulty. To determine the optimal hint length, SEELE employs a multi-round rollout sampling strategy. In each round, it fits an item response theory model to the accuracy-hint pairs collected in preceding rounds to predict the required hint length for the next round. This instance-level, real-time difficulty adjustment aligns problem difficulty with the evolving model capability, thereby improving exploration efficiency. Experimental results show that SEELE outperforms Group Relative Policy Optimization (GRPO) and Supervised Fine-tuning (SFT) by +11.8 and +10.5 points, respectively, and surpasses the best previous supervision-aided approach by +3.6 points on average across six math reasoning benchmarks.
Keyword-Centric Prompting for One-Shot Event Detection with Self-Generated Rationale Enhancements
Aug 11, 2025Although the LLM-based in-context learning (ICL) paradigm has demonstrated considerable success across various natural language processing tasks, it encounters challenges in event detection. This is because LLMs lack an accurate understanding of event triggers and tend to make over-interpretation, which cannot be effectively corrected through in-context examples alone. In this paper, we focus on the most challenging one-shot setting and propose KeyCP++, a keyword-centric chain-of-thought prompting approach. KeyCP++ addresses the weaknesses of conventional ICL by automatically annotating the logical gaps between input text and detection results for the demonstrations. Specifically, to generate in-depth and meaningful rationale, KeyCP++ constructs a trigger discrimination prompting template. It incorporates the exemplary triggers (a.k.a keywords) into the prompt as the anchor to simply trigger profiling, let LLM propose candidate triggers, and justify each candidate. These propose-and-judge rationales help LLMs mitigate over-reliance on the keywords and promote detection rule learning. Extensive experiments demonstrate the effectiveness of our approach, showcasing significant advancements in one-shot event detection.
SpeCache: Speculative Key-Value Caching for Efficient Generation of LLMs
Mar 20, 2025



Transformer-based large language models (LLMs) have already achieved remarkable results on long-text tasks, but the limited GPU memory (VRAM) resources struggle to accommodate the linearly growing demand for key-value (KV) cache as the sequence length increases, which has become a bottleneck for the application of LLMs on long sequences. Existing KV cache compression methods include eviction, merging, or quantization of the KV cache to reduce its size. However, compression results in irreversible information forgetting, potentially affecting the accuracy of subsequent decoding. In this paper, we propose SpeCache, which takes full advantage of the large and easily expandable CPU memory to offload the complete KV cache, and dynamically fetches KV pairs back in each decoding step based on their importance measured by low-bit KV cache copy in VRAM. To avoid inference latency caused by CPU-GPU communication, SpeCache speculatively predicts the KV pairs that the next token might attend to, allowing us to prefetch them before the next decoding step which enables parallelization of prefetching and computation. Experiments on LongBench and Needle-in-a-Haystack benchmarks verify that SpeCache effectively reduces VRAM usage while avoiding information forgetting for long sequences without re-training, even with a 10x high KV cache compression ratio.
Mixture of Lookup Experts
Mar 20, 2025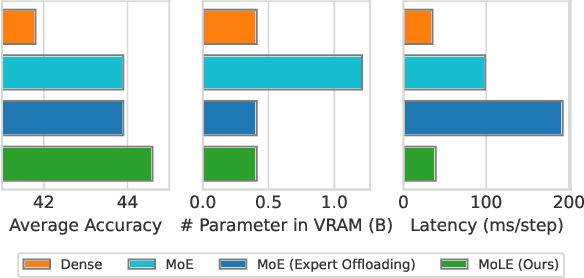

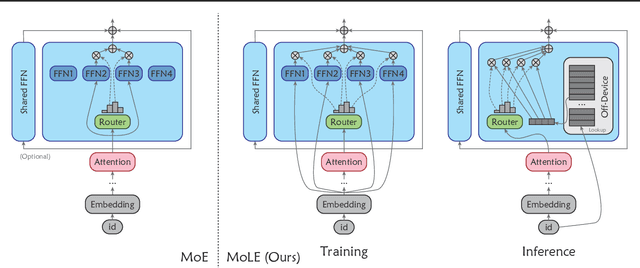
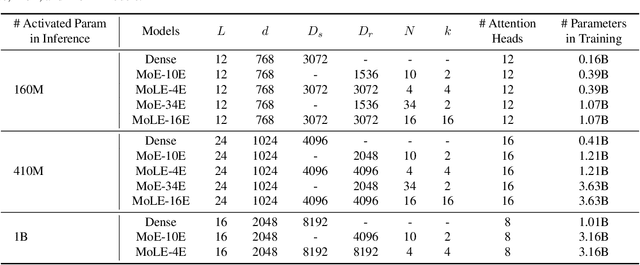
Mixture-of-Experts (MoE) activates only a subset of experts during inference, allowing the model to maintain low inference FLOPs and latency even as the parameter count scales up. However, since MoE dynamically selects the experts, all the experts need to be loaded into VRAM. Their large parameter size still limits deployment, and offloading, which load experts into VRAM only when needed, significantly increase inference latency. To address this, we propose Mixture of Lookup Experts (MoLE), a new MoE architecture that is efficient in both communication and VRAM usage. In MoLE, the experts are Feed-Forward Networks (FFNs) during training, taking the output of the embedding layer as input. Before inference, these experts can be re-parameterized as lookup tables (LUTs) that retrieves expert outputs based on input ids, and offloaded to storage devices. Therefore, we do not need to perform expert computations during inference. Instead, we directly retrieve the expert's computation results based on input ids and load them into VRAM, and thus the resulting communication overhead is negligible. Experiments show that, with the same FLOPs and VRAM usage, MoLE achieves inference speeds comparable to dense models and significantly faster than MoE with experts offloading, while maintaining performance on par with MoE.
BioMaze: Benchmarking and Enhancing Large Language Models for Biological Pathway Reasoning
Feb 23, 2025The applications of large language models (LLMs) in various biological domains have been explored recently, but their reasoning ability in complex biological systems, such as pathways, remains underexplored, which is crucial for predicting biological phenomena, formulating hypotheses, and designing experiments. This work explores the potential of LLMs in pathway reasoning. We introduce BioMaze, a dataset with 5.1K complex pathway problems derived from real research, covering various biological contexts including natural dynamic changes, disturbances, additional intervention conditions, and multi-scale research targets. Our evaluation of methods such as CoT and graph-augmented reasoning, shows that LLMs struggle with pathway reasoning, especially in perturbed systems. To address this, we propose PathSeeker, an LLM agent that enhances reasoning through interactive subgraph-based navigation, enabling a more effective approach to handling the complexities of biological systems in a scientifically aligned manner. The dataset and code are available at https://github.com/zhao-ht/BioMaze.
Instruction-Based Molecular Graph Generation with Unified Text-Graph Diffusion Model
Aug 19, 2024Recent advancements in computational chemistry have increasingly focused on synthesizing molecules based on textual instructions. Integrating graph generation with these instructions is complex, leading most current methods to use molecular sequences with pre-trained large language models. In response to this challenge, we propose a novel framework, named $\textbf{UTGDiff (Unified Text-Graph Diffusion Model)}$, which utilizes language models for discrete graph diffusion to generate molecular graphs from instructions. UTGDiff features a unified text-graph transformer as the denoising network, derived from pre-trained language models and minimally modified to process graph data through attention bias. Our experimental results demonstrate that UTGDiff consistently outperforms sequence-based baselines in tasks involving instruction-based molecule generation and editing, achieving superior performance with fewer parameters given an equivalent level of pretraining corpus. Our code is availble at https://github.com/ran1812/UTGDiff.
Token Compensator: Altering Inference Cost of Vision Transformer without Re-Tuning
Aug 13, 2024


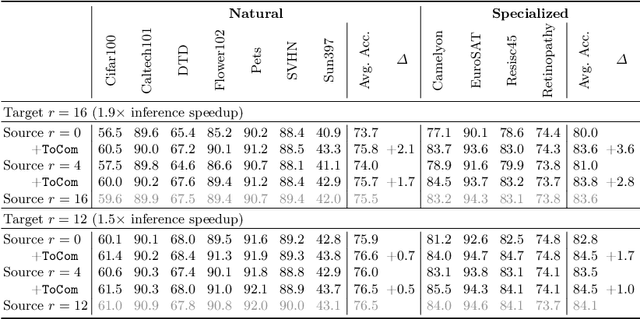
Token compression expedites the training and inference of Vision Transformers (ViTs) by reducing the number of the redundant tokens, e.g., pruning inattentive tokens or merging similar tokens. However, when applied to downstream tasks, these approaches suffer from significant performance drop when the compression degrees are mismatched between training and inference stages, which limits the application of token compression on off-the-shelf trained models. In this paper, we propose a model arithmetic framework to decouple the compression degrees between the two stages. In advance, we additionally perform a fast parameter-efficient self-distillation stage on the pre-trained models to obtain a small plugin, called Token Compensator (ToCom), which describes the gap between models across different compression degrees. During inference, ToCom can be directly inserted into any downstream off-the-shelf models with any mismatched training and inference compression degrees to acquire universal performance improvements without further training. Experiments on over 20 downstream tasks demonstrate the effectiveness of our framework. On CIFAR100, fine-grained visual classification, and VTAB-1k, ToCom can yield up to a maximum improvement of 2.3%, 1.5%, and 2.0% in the average performance of DeiT-B, respectively. Code: https://github.com/JieShibo/ToCom
Memory-Space Visual Prompting for Efficient Vision-Language Fine-Tuning
May 09, 2024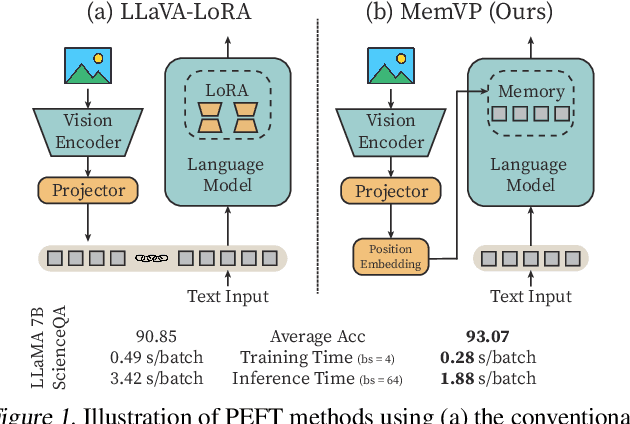
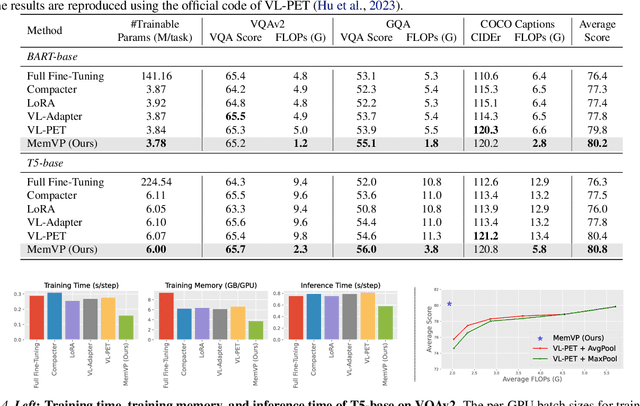
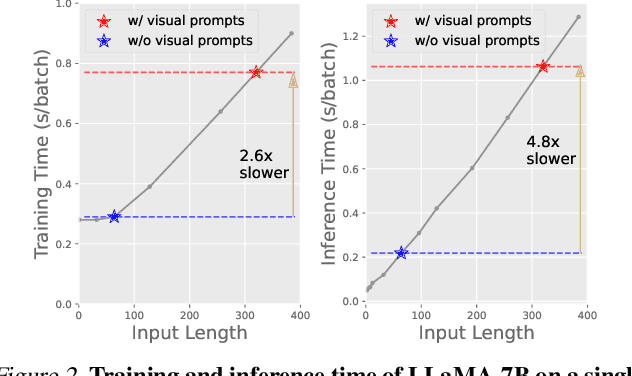
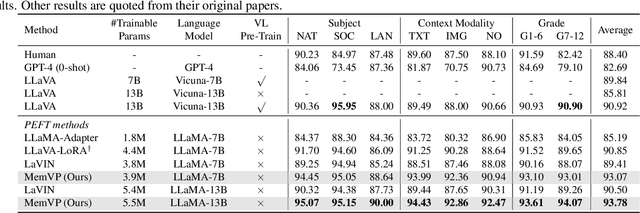
Current solutions for efficiently constructing large vision-language (VL) models follow a two-step paradigm: projecting the output of pre-trained vision encoders to the input space of pre-trained language models as visual prompts; and then transferring the models to downstream VL tasks via end-to-end parameter-efficient fine-tuning (PEFT). However, this paradigm still exhibits inefficiency since it significantly increases the input length of the language models. In this paper, in contrast to integrating visual prompts into inputs, we regard visual prompts as additional knowledge that facilitates language models in addressing tasks associated with visual information. Motivated by the finding that Feed-Forward Network (FFN) of language models acts as "key-value memory", we introduce a novel approach termed memory-space visual prompting (MemVP), wherein visual prompts are concatenated with the weights of FFN for visual knowledge injection. Experimental results across various VL tasks and language models reveal that MemVP significantly reduces the training time and inference latency of the finetuned VL models and surpasses the performance of previous PEFT methods. Code: https://github.com/JieShibo/MemVP