 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemTrain: Self-Supervised Context Memory Training
Jun 02, 2026Memory is an indispensable capability for long-horizon LLM agents, enabling them to preserve and utilize information accumulated across extended interactions. Existing memory-agent approaches are typically trained end-to-end with reinforcement learning on downstream tasks. However, collecting high-quality annotated problems for memory-intensive scenarios is costly, and the resulting training data often lack sufficient diversity to cover general memory behaviors. In this work, we propose MemTrain, a self-supervised training framework for generally enhancing the context-memory capability of LLM agents for more effective downstream post-training. MemTrain introduces two coupled proxy tasks over unlabeled Wikipedia corpora: (1) an end-to-end masked reconstruction objective, which requires the model to recover masked entities after multiple rounds of memory updates, thereby encouraging memory maintenance from the final outcome perspective; and (2) an intermediate memory recall objective, which requires the model to reconstruct masked historical information using intermediate memory states, encouraging faithful compression and memory completeness throughout the interaction process. The two objectives are jointly optimized using GRPO. Extensive experiments on long-text QA and search-based QA benchmarks demonstrate that MemTrain consistently improves downstream memory-intensive reasoning performance across different models, achieving gains of up to 17.67 points over direct task-specific post-training.
Trust Region On-Policy Distillation
May 31, 2026On-Policy Distillation (OPD) is a fundamental technique for efficient post-training of large language models (LLMs), with broad applications in agent learning, multi-task enhancement, and model compression. However, OPD training becomes unstable when the teacher and student distributions differ substantially, as teacher supervision on student-generated tokens may yield unreliable policy gradients and even cause optimization failure. This work addresses reliable on-policy token-level supervision through credit assignment strategies, and proposes Trust Region On-Policy Distillation, TrOPD. It features the following characteristics: 1) Trust-Region On-Policy Learning: TrOPD performs OPD only in regions where the teacher provides reliable supervision, mitigating the optimization difficulty of the K1 reverse-KL estimator under distribution mismatch. 2) Outlier Estimation: For outlier regions, we explore gradient clipping, masking, and forward-KL estimation to reduce the adverse effects of unreliable supervision. 3) Off-Policy Guidance: The student continues generation from teacher prefixes and uses forward KL to imitate off-policy guidance, encouraging on-policy exploration toward reliable regions. Experiments show that TrOPD consistently outperforms SoTA OPD baselines, including OPD, EOPD, and REOPOLD, across mathematical reasoning, code generation, and general-domain benchmarks.
To Mix or To Merge: Toward Multi-Domain Reinforcement Learning for Large Language Models
Feb 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) plays a key role in stimulating the explicit reasoning capability of Large Language Models (LLMs). We can achieve expert-level performance in some specific domains via RLVR, such as coding or math. When a general multi-domain expert-level model is required, we need to carefully consider the collaboration of RLVR across different domains. The current state-of-the-art models mainly employ two different training paradigms for multi-domain RLVR: mixed multi-task RLVR and separate RLVR followed by model merging. However, most of the works did not provide a detailed comparison and analysis about these paradigms. To this end, we choose multiple commonly used high-level tasks (e.g., math, coding, science, and instruction following) as our target domains and design extensive qualitative and quantitative experiments using open-source datasets. We find the RLVR across domains exhibits few mutual interferences, and reasoning-intensive domains demonstrate mutually synergistic effects. Furthermore, we analyze the internal mechanisms of mutual gains from the perspectives of weight space geometry, model prediction behavior, and information constraints. This project is named as M2RL that means Mixed multi-task training or separate training followed by model Merging for Reinforcement Learning, and the homepage is at https://github.com/mosAI25/M2RL
Revisiting the Parameter Efficiency of Adapters from the Perspective of Precision Redundancy
Jul 31, 2023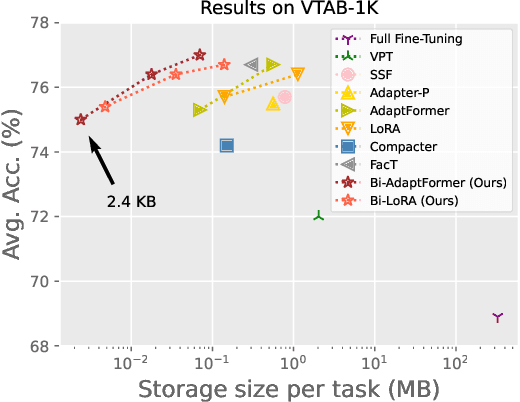
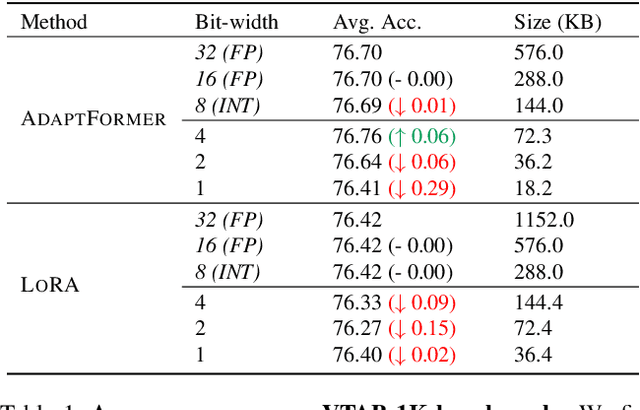
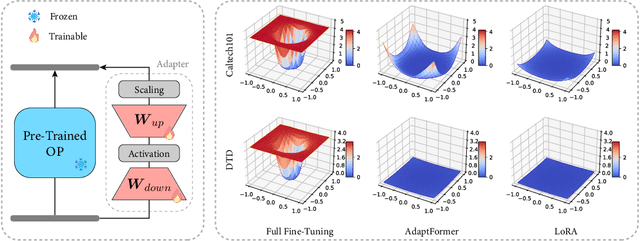
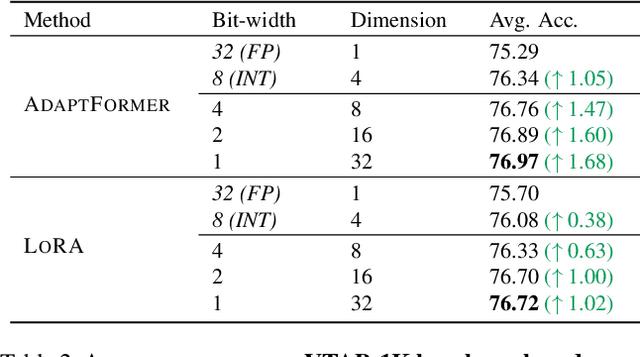
Current state-of-the-art results in computer vision depend in part on fine-tuning large pre-trained vision models. However, with the exponential growth of model sizes, the conventional full fine-tuning, which needs to store a individual network copy for each tasks, leads to increasingly huge storage and transmission overhead. Adapter-based Parameter-Efficient Tuning (PET) methods address this challenge by tuning lightweight adapters inserted into the frozen pre-trained models. In this paper, we investigate how to make adapters even more efficient, reaching a new minimum size required to store a task-specific fine-tuned network. Inspired by the observation that the parameters of adapters converge at flat local minima, we find that adapters are resistant to noise in parameter space, which means they are also resistant to low numerical precision. To train low-precision adapters, we propose a computational-efficient quantization method which minimizes the quantization error. Through extensive experiments, we find that low-precision adapters exhibit minimal performance degradation, and even 1-bit precision is sufficient for adapters. The experimental results demonstrate that 1-bit adapters outperform all other PET methods on both the VTAB-1K benchmark and few-shot FGVC tasks, while requiring the smallest storage size. Our findings show, for the first time, the significant potential of quantization techniques in PET, providing a general solution to enhance the parameter efficiency of adapter-based PET methods. Code: https://github.com/JieShibo/PETL-ViT
Masked Image Modeling with Local Multi-Scale Reconstruction
Mar 09, 2023Masked Image Modeling (MIM) achieves outstanding success in self-supervised representation learning. Unfortunately, MIM models typically have huge computational burden and slow learning process, which is an inevitable obstacle for their industrial applications. Although the lower layers play the key role in MIM, existing MIM models conduct reconstruction task only at the top layer of encoder. The lower layers are not explicitly guided and the interaction among their patches is only used for calculating new activations. Considering the reconstruction task requires non-trivial inter-patch interactions to reason target signals, we apply it to multiple local layers including lower and upper layers. Further, since the multiple layers expect to learn the information of different scales, we design local multi-scale reconstruction, where the lower and upper layers reconstruct fine-scale and coarse-scale supervision signals respectively. This design not only accelerates the representation learning process by explicitly guiding multiple layers, but also facilitates multi-scale semantical understanding to the input. Extensive experiments show that with significantly less pre-training burden, our model achieves comparable or better performance on classification, detection and segmentation tasks than existing MIM models.
Rethinking Minimal Sufficient Representation in Contrastive Learning
Apr 02, 2022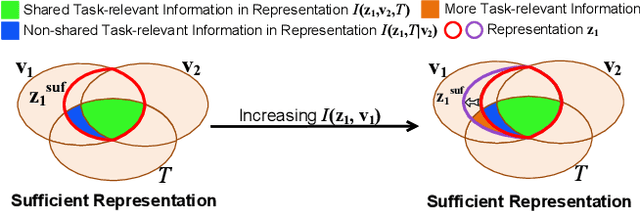
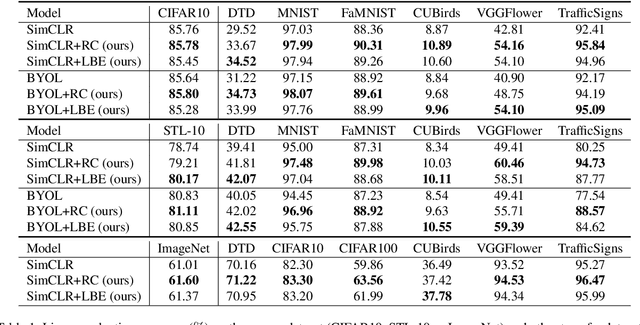
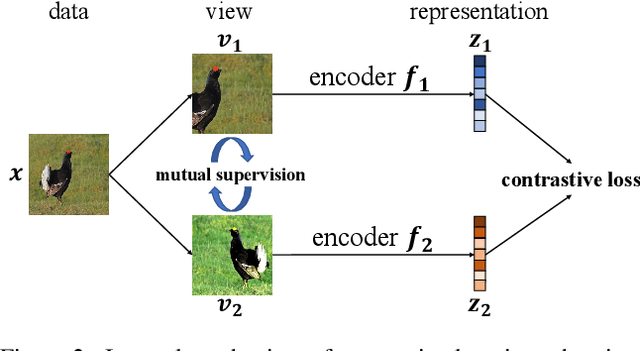
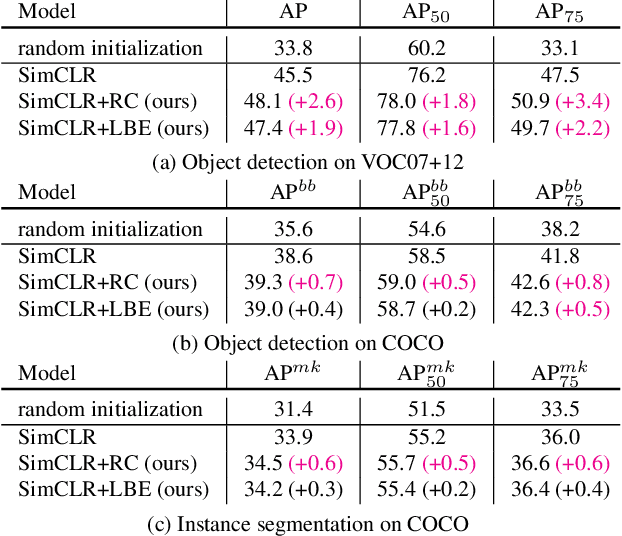
Contrastive learning between different views of the data achieves outstanding success in the field of self-supervised representation learning and the learned representations are useful in broad downstream tasks. Since all supervision information for one view comes from the other view, contrastive learning approximately obtains the minimal sufficient representation which contains the shared information and eliminates the non-shared information between views. Considering the diversity of the downstream tasks, it cannot be guaranteed that all task-relevant information is shared between views. Therefore, we assume the non-shared task-relevant information cannot be ignored and theoretically prove that the minimal sufficient representation in contrastive learning is not sufficient for the downstream tasks, which causes performance degradation. This reveals a new problem that the contrastive learning models have the risk of over-fitting to the shared information between views. To alleviate this problem, we propose to increase the mutual information between the representation and input as regularization to approximately introduce more task-relevant information, since we cannot utilize any downstream task information during training. Extensive experiments verify the rationality of our analysis and the effectiveness of our method. It significantly improves the performance of several classic contrastive learning models in downstream tasks. Our code is available at https://github.com/Haoqing-Wang/InfoCL.
Cross-Domain Few-Shot Classification via Adversarial Task Augmentation
May 02, 2021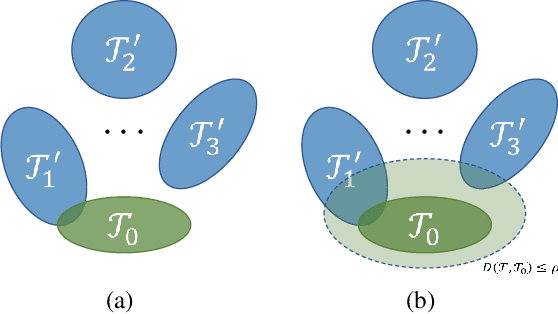
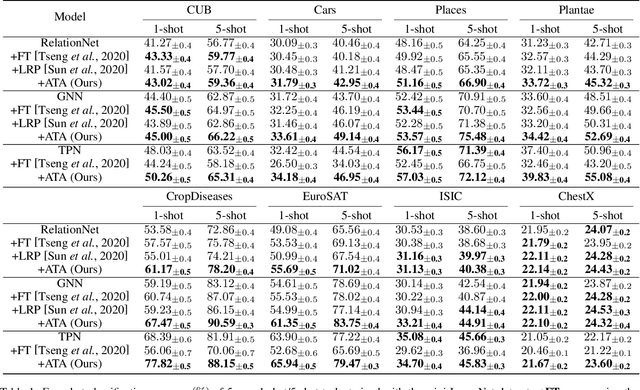
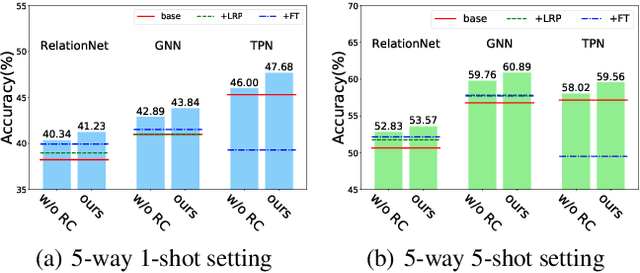
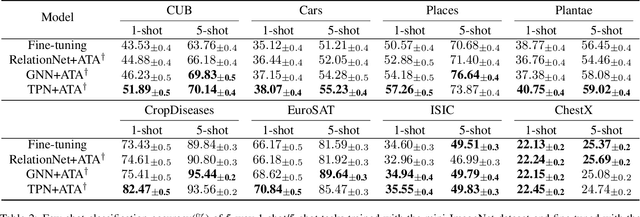
Few-shot classification aims to recognize unseen classes with few labeled samples from each class. Many meta-learning models for few-shot classification elaborately design various task-shared inductive bias (meta-knowledge) to solve such tasks, and achieve impressive performance. However, when there exists the domain shift between the training tasks and the test tasks, the obtained inductive bias fails to generalize across domains, which degrades the performance of the meta-learning models. In this work, we aim to improve the robustness of the inductive bias through task augmentation. Concretely, we consider the worst-case problem around the source task distribution, and propose the adversarial task augmentation method which can generate the inductive bias-adaptive 'challenging' tasks. Our method can be used as a simple plug-and-play module for various meta-learning models, and improve their cross-domain generalization capability. We conduct extensive experiments under the cross-domain setting, using nine few-shot classification datasets: mini-ImageNet, CUB, Cars, Places, Plantae, CropDiseases, EuroSAT, ISIC and ChestX. Experimental results show that our method can effectively improve the few-shot classification performance of the meta-learning models under domain shift, and outperforms the existing works. Our code is available at https://github.com/Haoqing-Wang/CDFSL-ATA.
Few-shot Learning with LSSVM Base Learner and Transductive Modules
Sep 12, 2020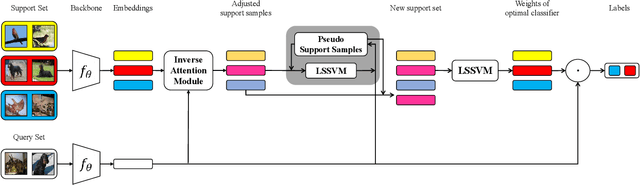
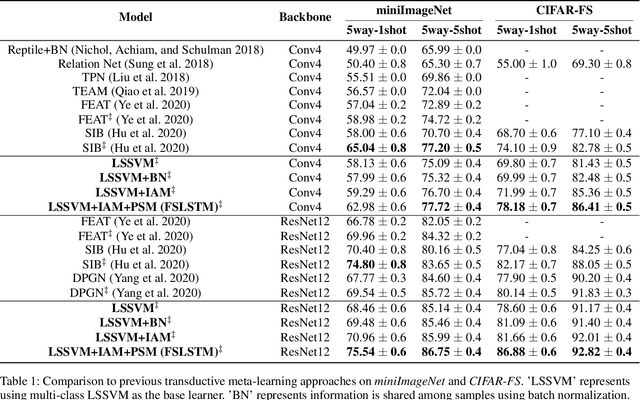
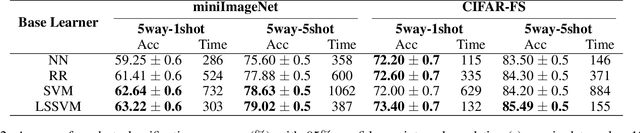
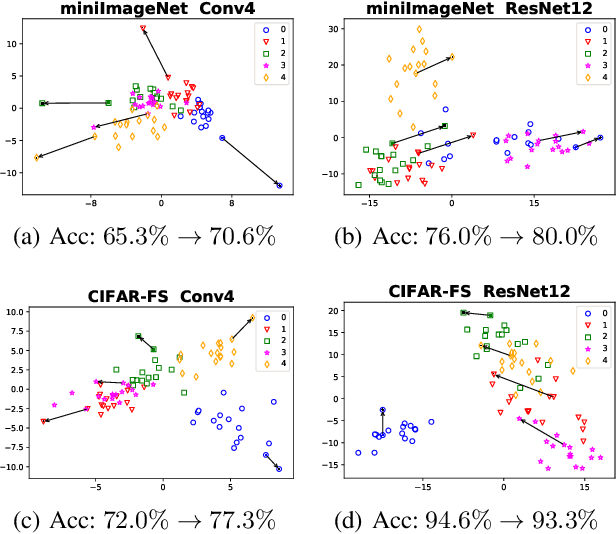
The performance of meta-learning approaches for few-shot learning generally depends on three aspects: features suitable for comparison, the classifier ( base learner ) suitable for low-data scenarios, and valuable information from the samples to classify. In this work, we make improvements for the last two aspects: 1) although there are many effective base learners, there is a trade-off between generalization performance and computational overhead, so we introduce multi-class least squares support vector machine as our base learner which obtains better generation than existing ones with less computational overhead; 2) further, in order to utilize the information from the query samples, we propose two simple and effective transductive modules which modify the support set using the query samples, i.e., adjusting the support samples basing on the attention mechanism and adding the prototypes of the query set with pseudo labels to the support set as the pseudo support samples. These two modules significantly improve the few-shot classification accuracy, especially for the difficult 1-shot setting. Our model, denoted as FSLSTM (Few-Shot learning with LSsvm base learner and Transductive Modules), achieves state-of-the-art performance on miniImageNet and CIFAR-FS few-shot learning benchmarks.
Fast Structured Decoding for Sequence Models
Oct 25, 2019
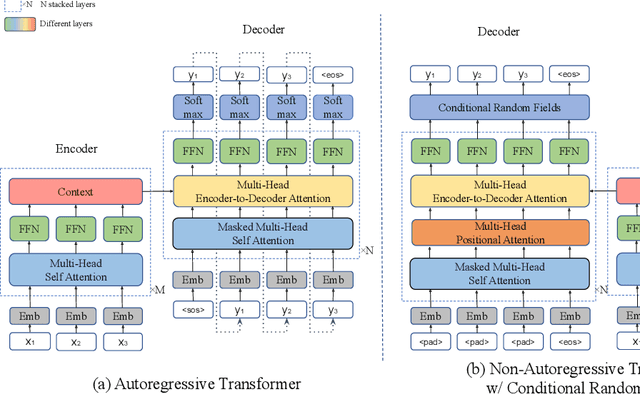
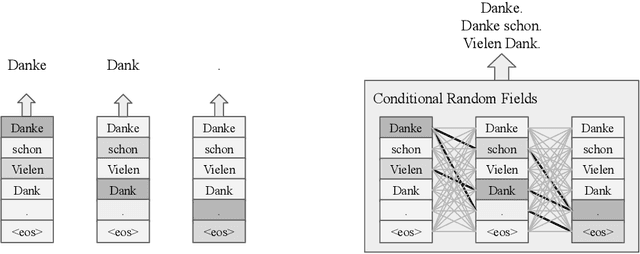
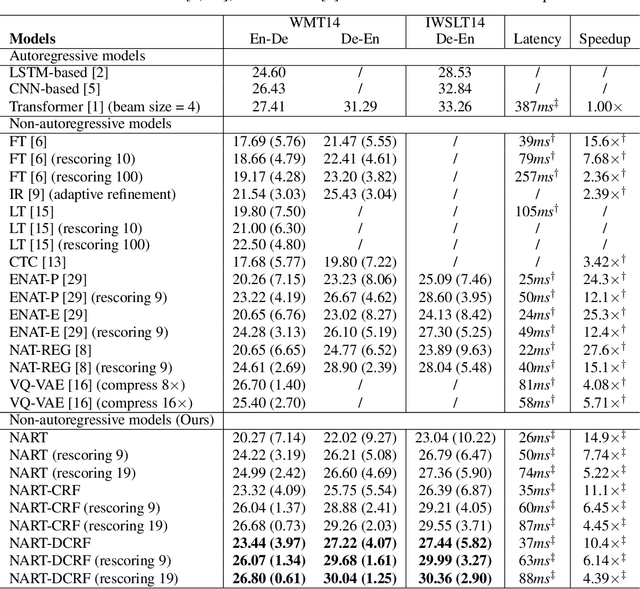
Autoregressive sequence models achieve state-of-the-art performance in domains like machine translation. However, due to the autoregressive factorization nature, these models suffer from heavy latency during inference. Recently, non-autoregressive sequence models were proposed to speed up the inference time. However, these models assume that the decoding process of each token is conditionally independent of others. Such a generation process sometimes makes the output sentence inconsistent, and thus the learned non-autoregressive models could only achieve inferior accuracy compared to their autoregressive counterparts. To improve then decoding consistency and reduce the inference cost at the same time, we propose to incorporate a structured inference module into the non-autoregressive models. Specifically, we design an efficient approximation for Conditional Random Fields (CRF) for non-autoregressive sequence models, and further propose a dynamic transition technique to model positional contexts in the CRF. Experiments in machine translation show that while increasing little latency (8~14ms), our model could achieve significantly better translation performance than previous non-autoregressive models on different translation datasets. In particular, for the WMT14 En-De dataset, our model obtains a BLEU score of 26.80, which largely outperforms the previous non-autoregressive baselines and is only 0.61 lower in BLEU than purely autoregressive models.