 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASCADE: Cumulative Agentic Skill Creation through Autonomous Development and Evolution
Dec 29, 2025Large language model (LLM) agents currently depend on predefined tools or brittle tool generation, constraining their capability and adaptability to complex scientific tasks. We introduce CASCADE, a self-evolving agentic framework representing an early instantiation of the transition from "LLM + tool use" to "LLM + skill acquisition". CASCADE enables agents to master complex external tools and codify knowledge through two meta-skills: continuous learning via web search and code extraction, and self-reflection via introspection and knowledge graph exploration, among others. We evaluate CASCADE on SciSkillBench, a benchmark of 116 materials science and chemistry research tasks. CASCADE achieves a 93.3% success rate using GPT-5, compared to 35.4% without evolution mechanisms. We further demonstrate real-world applications in computational analysis, autonomous laboratory experiments, and selective reproduction of published papers. Along with human-agent collaboration and memory consolidation, CASCADE accumulates executable skills that can be shared across agents and scientists, moving toward scalable AI-assisted scientific research.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Optimizing Speculative Decoding for Serving Large Language Models Using Goodput
Jun 20, 2024



Reducing the inference latency of large language models (LLMs) is crucial, and speculative decoding (SD) stands out as one of the most effective techniques. Rather than letting the LLM generate all tokens directly, speculative decoding employs effective proxies to predict potential outputs, which are then verified by the LLM without compromising the generation quality. Yet, deploying SD in real online LLM serving systems (with continuous batching) does not always yield improvement -- under higher request rates or low speculation accuracy, it paradoxically increases latency. Furthermore, there is no best speculation length work for all workloads under different system loads. Based on the observations, we develop a dynamic framework SmartSpec. SmartSpec dynamically determines the best speculation length for each request (from 0, i.e., no speculation, to many tokens) -- hence the associated speculative execution costs -- based on a new metric called goodput, which characterizes the current observed load of the entire system and the speculation accuracy. We show that SmartSpec consistently reduces average request latency by up to 3.2x compared to non-speculative decoding baselines across different sizes of target models, draft models, request rates, and datasets. Moreover, SmartSpec can be applied to different styles of speculative decoding, including traditional, model-based approaches as well as model-free methods like prompt lookup and tree-style decoding.
Overcoming systematic softening in universal machine learning interatomic potentials by fine-tuning
May 11, 2024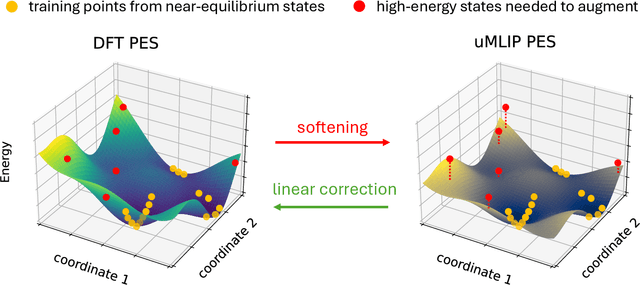
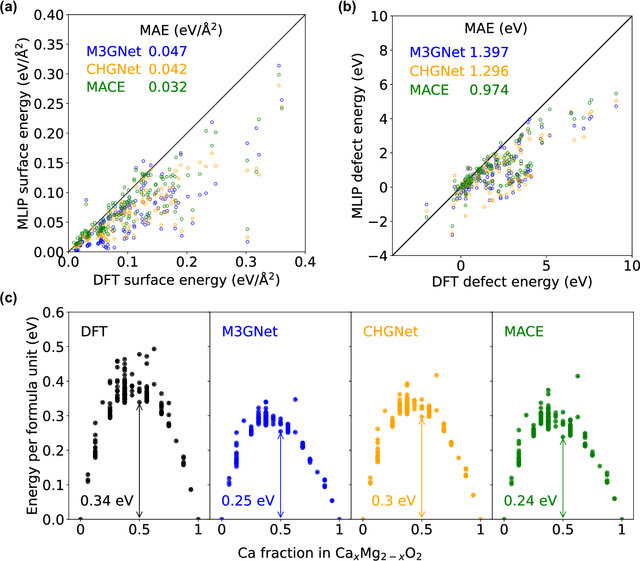
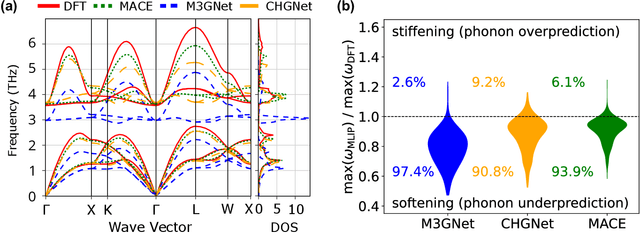
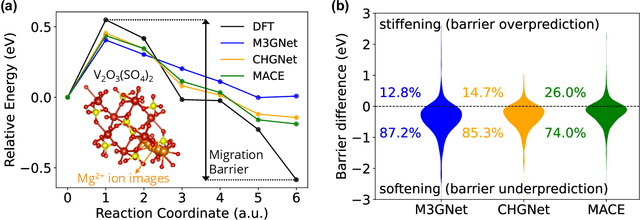
Machine learning interatomic potentials (MLIPs) have introduced a new paradigm for atomic simulations. Recent advancements have seen the emergence of universal MLIPs (uMLIPs) that are pre-trained on diverse materials datasets, providing opportunities for both ready-to-use universal force fields and robust foundations for downstream machine learning refinements. However, their performance in extrapolating to out-of-distribution complex atomic environments remains unclear. In this study, we highlight a consistent potential energy surface (PES) softening effect in three uMLIPs: M3GNet, CHGNet, and MACE-MP-0, which is characterized by energy and force under-prediction in a series of atomic-modeling benchmarks including surfaces, defects, solid-solution energetics, phonon vibration modes, ion migration barriers, and general high-energy states. We find that the PES softening behavior originates from a systematic underprediction error of the PES curvature, which derives from the biased sampling of near-equilibrium atomic arrangements in uMLIP pre-training datasets. We demonstrate that the PES softening issue can be effectively rectified by fine-tuning with a single additional data point. Our findings suggest that a considerable fraction of uMLIP errors are highly systematic, and can therefore be efficiently corrected. This result rationalizes the data-efficient fine-tuning performance boost commonly observed with foundational MLIPs. We argue for the importance of a comprehensive materials dataset with improved PES sampling for next-generation foundational MLIPs.
Fairness in Serving Large Language Models
Dec 31, 2023
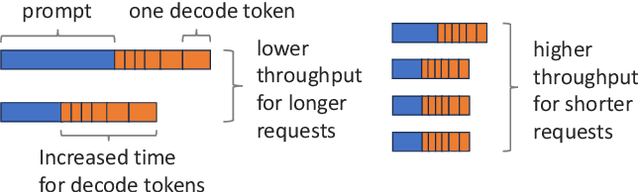
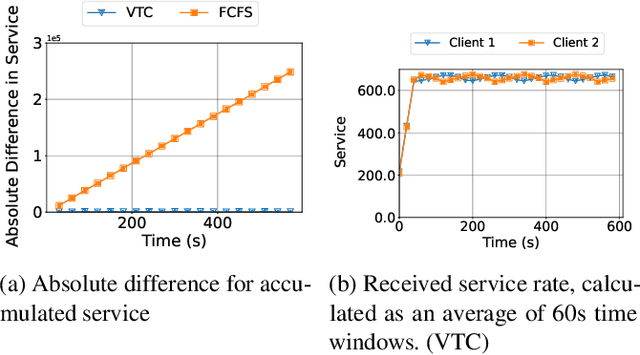
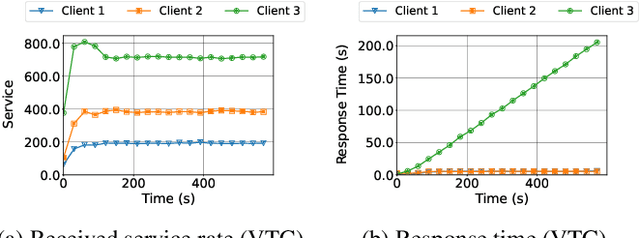
High-demand LLM inference services (e.g., ChatGPT and BARD) support a wide range of requests from short chat conversations to long document reading. To ensure that all client requests are processed fairly, most major LLM inference services have request rate limits, to ensure that no client can dominate the request queue. However, this rudimentary notion of fairness also results in under-utilization of the resources and poor client experience when there is spare capacity. While there is a rich literature on fair scheduling, serving LLMs presents new challenges due to their unpredictable request lengths and their unique batching characteristics on parallel accelerators. This paper introduces the definition of LLM serving fairness based on a cost function that accounts for the number of input and output tokens processed. To achieve fairness in serving, we propose a novel scheduling algorithm, the Virtual Token Counter (VTC), a fair scheduler based on the continuous batching mechanism. We prove a 2x tight upper bound on the service difference between two backlogged clients, adhering to the requirement of work-conserving. Through extensive experiments, we demonstrate the superior performance of VTC in ensuring fairness, especially in contrast to other baseline methods, which exhibit shortcomings under various conditions.
LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset
Sep 30, 2023



Studying how people interact with large language models (LLMs) in real-world scenarios is increasingly important due to their widespread use in various applications. In this paper, we introduce LMSYS-Chat-1M, a large-scale dataset containing one million real-world conversations with 25 state-of-the-art LLMs. This dataset is collected from 210K unique IP addresses in the wild on our Vicuna demo and Chatbot Arena website. We offer an overview of the dataset's content, including its curation process, basic statistics, and topic distribution, highlighting its diversity, originality, and scale. We demonstrate its versatility through four use cases: developing content moderation models that perform similarly to GPT-4, building a safety benchmark, training instruction-following models that perform similarly to Vicuna, and creating challenging benchmark questions. We believe that this dataset will serve as a valuable resource for understanding and advancing LLM capabilities. The dataset is publicly available at https://huggingface.co/datasets/lmsys/lmsys-chat-1m.
Efficient Memory Management for Large Language Model Serving with PagedAttention
Sep 12, 2023High throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time. However, existing systems struggle because the key-value cache (KV cache) memory for each request is huge and grows and shrinks dynamically. When managed inefficiently, this memory can be significantly wasted by fragmentation and redundant duplication, limiting the batch size. To address this problem, we propose PagedAttention, an attention algorithm inspired by the classical virtual memory and paging techniques in operating systems. On top of it, we build vLLM, an LLM serving system that achieves (1) near-zero waste in KV cache memory and (2) flexible sharing of KV cache within and across requests to further reduce memory usage. Our evaluations show that vLLM improves the throughput of popular LLMs by 2-4$\times$ with the same level of latency compared to the state-of-the-art systems, such as FasterTransformer and Orca. The improvement is more pronounced with longer sequences, larger models, and more complex decoding algorithms. vLLM's source code is publicly available at https://github.com/vllm-project/vllm
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena
Jun 09, 2023



Evaluating large language model (LLM) based chat assistants is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences. To address this, we explore using strong LLMs as judges to evaluate these models on more open-ended questions. We examine the usage and limitations of LLM-as-a-judge, such as position and verbosity biases and limited reasoning ability, and propose solutions to migrate some of them. We then verify the agreement between LLM judges and human preferences by introducing two benchmarks: MT-bench, a multi-turn question set; and Chatbot Arena, a crowdsourced battle platform. Our results reveal that strong LLM judges like GPT-4 can match both controlled and crowdsourced human preferences well, achieving over 80\% agreement, the same level of agreement between humans. Hence, LLM-as-a-judge is a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain. Additionally, we show our benchmark and traditional benchmarks complement each other by evaluating several variants of LLaMA/Vicuna. We will publicly release 80 MT-bench questions, 3K expert votes, and 30K conversations with human preferences from Chatbot Arena.
What is the State of Memory Saving for Model Training?
Mar 26, 2023Large neural networks can improve the accuracy and generalization on tasks across many domains. However, this trend cannot continue indefinitely due to limited hardware memory. As a result, researchers have devised a number of memory optimization methods (MOMs) to alleviate the memory bottleneck, such as gradient checkpointing, quantization, and swapping. In this work, we study memory optimization methods and show that, although these strategies indeed lower peak memory usage, they can actually decrease training throughput by up to 9.3x. To provide practical guidelines for practitioners, we propose a simple but effective performance model PAPAYA to quantitatively explain the memory and training time trade-off. PAPAYA can be used to determine when to apply the various memory optimization methods in training different models. We outline the circumstances in which memory optimization techniques are more advantageous based on derived implications from PAPAYA. We assess the accuracy of PAPAYA and the derived implications on a variety of machine models, showing that it achieves over 0.97 R score on predicting the peak memory/throughput, and accurately predicts the effectiveness of MOMs across five evaluated models on vision and NLP tasks.
High-throughput Generative Inference of Large Language Models with a Single GPU
Mar 13, 2023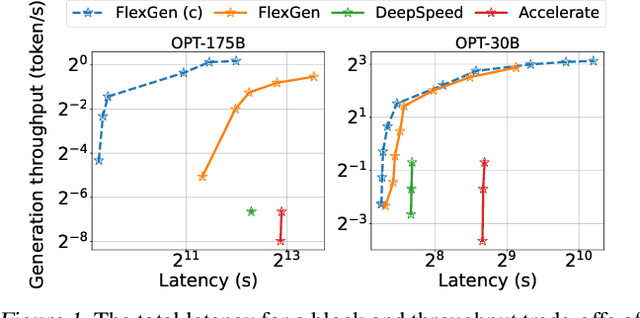

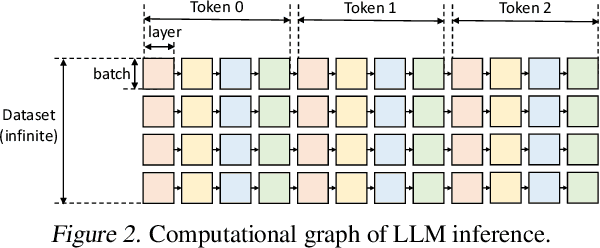
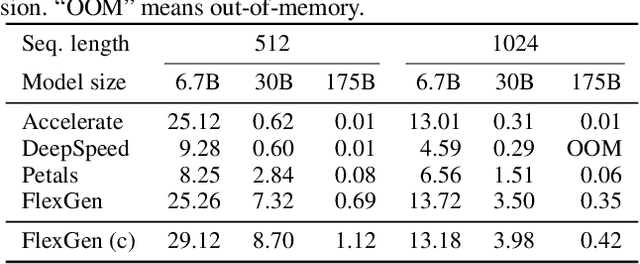
The high computational and memory requirements of large language model (LLM) inference traditionally make it feasible only with multiple high-end accelerators. Motivated by the emerging demand for latency-insensitive tasks with batched processing, this paper initiates the study of high-throughput LLM inference using limited resources, such as a single commodity GPU. We present FlexGen, a high-throughput generation engine for running LLMs with limited GPU memory. FlexGen can be flexibly configured under various hardware resource constraints by aggregating memory and computation from the GPU, CPU, and disk. Through a linear programming optimizer, it searches for efficient patterns to store and access tensors. FlexGen further compresses these weights and the attention cache to 4 bits with negligible accuracy loss. These techniques enable FlexGen to have a larger space of batch size choices and thus significantly increase maximum throughput. As a result, when running OPT-175B on a single 16GB GPU, FlexGen achieves significantly higher throughput compared to state-of-the-art offloading systems, reaching a generation throughput of 1 token/s for the first time with an effective batch size of 144. On the HELM benchmark, FlexGen can benchmark a 30B model with a 16GB GPU on 7 representative sub-scenarios in 21 hours. The code is available at https://github.com/FMInference/FlexGen