 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Speculative Decoding for Serving Large Language Models Using Goodput
Jun 20, 2024



Reducing the inference latency of large language models (LLMs) is crucial, and speculative decoding (SD) stands out as one of the most effective techniques. Rather than letting the LLM generate all tokens directly, speculative decoding employs effective proxies to predict potential outputs, which are then verified by the LLM without compromising the generation quality. Yet, deploying SD in real online LLM serving systems (with continuous batching) does not always yield improvement -- under higher request rates or low speculation accuracy, it paradoxically increases latency. Furthermore, there is no best speculation length work for all workloads under different system loads. Based on the observations, we develop a dynamic framework SmartSpec. SmartSpec dynamically determines the best speculation length for each request (from 0, i.e., no speculation, to many tokens) -- hence the associated speculative execution costs -- based on a new metric called goodput, which characterizes the current observed load of the entire system and the speculation accuracy. We show that SmartSpec consistently reduces average request latency by up to 3.2x compared to non-speculative decoding baselines across different sizes of target models, draft models, request rates, and datasets. Moreover, SmartSpec can be applied to different styles of speculative decoding, including traditional, model-based approaches as well as model-free methods like prompt lookup and tree-style decoding.
Amazon SageMaker Model Parallelism: A General and Flexible Framework for Large Model Training
Nov 10, 2021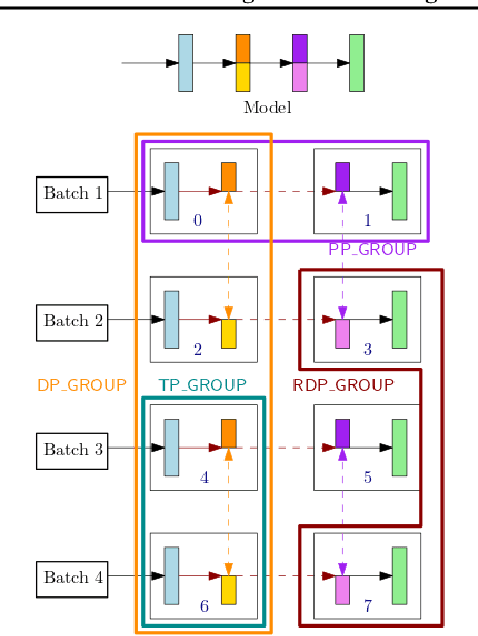
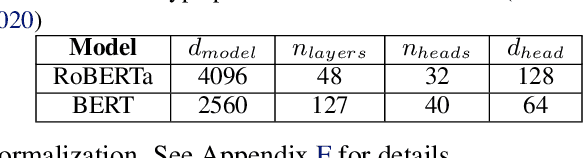
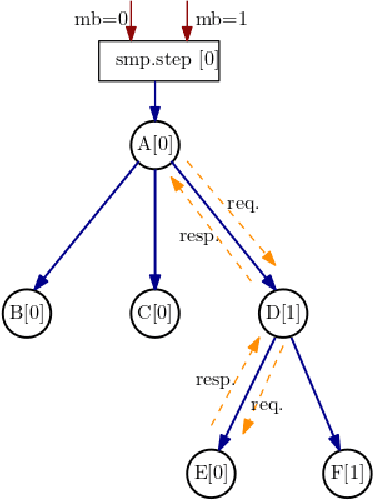

With deep learning models rapidly growing in size, systems-level solutions for large-model training are required. We present Amazon SageMaker model parallelism, a software library that integrates with PyTorch, and enables easy training of large models using model parallelism and other memory-saving features. In contrast to existing solutions, the implementation of the SageMaker library is much more generic and flexible, in that it can automatically partition and run pipeline parallelism over arbitrary model architectures with minimal code change, and also offers a general and extensible framework for tensor parallelism, which supports a wider range of use cases, and is modular enough to be easily applied to new training scripts. The library also preserves the native PyTorch user experience to a much larger degree, supporting module re-use and dynamic graphs, while giving the user full control over the details of the training step. We evaluate performance over GPT-3, RoBERTa, BERT, and neural collaborative filtering, and demonstrate competitive performance over existing solutions.