 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrism: Unleashing GPU Sharing for Cost-Efficient Multi-LLM Serving
May 06, 2025



Serving large language models (LLMs) is expensive, especially for providers hosting many models, making cost reduction essential. The unique workload patterns of serving multiple LLMs (i.e., multi-LLM serving) create new opportunities and challenges for this task. The long-tail popularity of models and their long idle periods present opportunities to improve utilization through GPU sharing. However, existing GPU sharing systems lack the ability to adjust their resource allocation and sharing policies at runtime, making them ineffective at meeting latency service-level objectives (SLOs) under rapidly fluctuating workloads. This paper presents Prism, a multi-LLM serving system that unleashes the full potential of GPU sharing to achieve both cost efficiency and SLO attainment. At its core, Prism tackles a key limitation of existing systems$\unicode{x2014}$the lack of $\textit{cross-model memory coordination}$, which is essential for flexibly sharing GPU memory across models under dynamic workloads. Prism achieves this with two key designs. First, it supports on-demand memory allocation by dynamically mapping physical to virtual memory pages, allowing flexible memory redistribution among models that space- and time-share a GPU. Second, it improves memory efficiency through a two-level scheduling policy that dynamically adjusts sharing strategies based on models' runtime demands. Evaluations on real-world traces show that Prism achieves more than $2\times$ cost savings and $3.3\times$ SLO attainment compared to state-of-the-art systems.
WorldModelBench: Judging Video Generation Models As World Models
Feb 28, 2025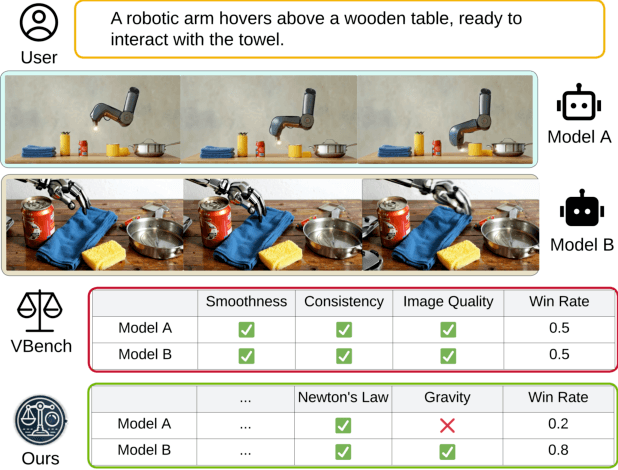
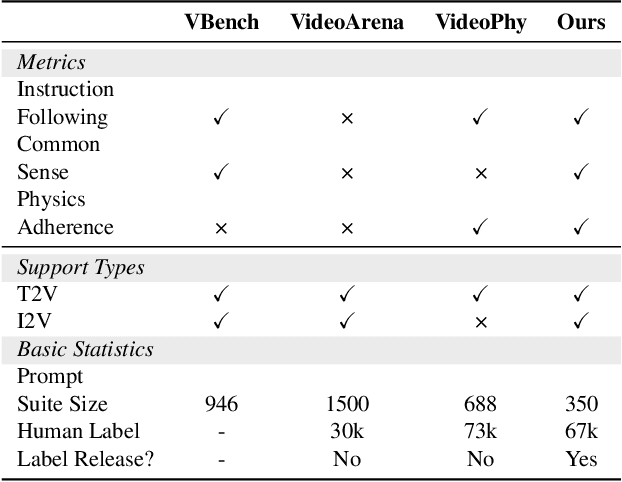
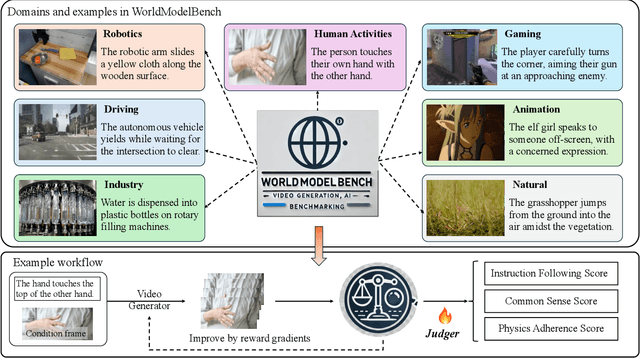
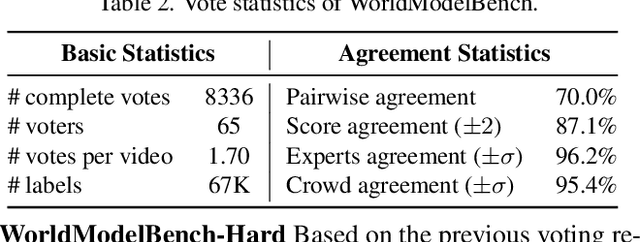
Video generation models have rapidly progressed, positioning themselves as video world models capable of supporting decision-making applications like robotics and autonomous driving. However, current benchmarks fail to rigorously evaluate these claims, focusing only on general video quality, ignoring important factors to world models such as physics adherence. To bridge this gap, we propose WorldModelBench, a benchmark designed to evaluate the world modeling capabilities of video generation models in application-driven domains. WorldModelBench offers two key advantages: (1) Against to nuanced world modeling violations: By incorporating instruction-following and physics-adherence dimensions, WorldModelBench detects subtle violations, such as irregular changes in object size that breach the mass conservation law - issues overlooked by prior benchmarks. (2) Aligned with large-scale human preferences: We crowd-source 67K human labels to accurately measure 14 frontier models. Using our high-quality human labels, we further fine-tune an accurate judger to automate the evaluation procedure, achieving 8.6% higher average accuracy in predicting world modeling violations than GPT-4o with 2B parameters. In addition, we demonstrate that training to align human annotations by maximizing the rewards from the judger noticeably improve the world modeling capability. The website is available at https://worldmodelbench-team.github.io.
S*: Test Time Scaling for Code Generation
Feb 20, 2025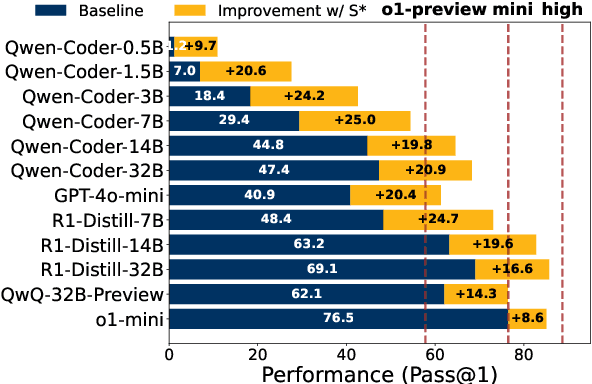
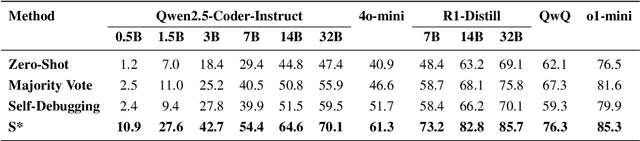
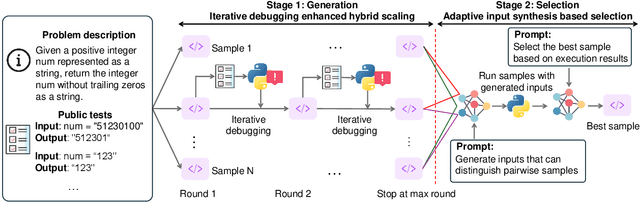
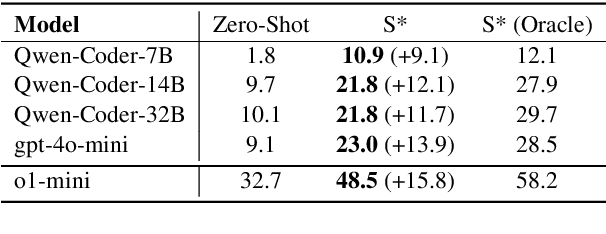
Increasing test-time compute for LLMs shows promise across domains but remains underexplored in code generation, despite extensive study in math. In this paper, we propose S*, the first hybrid test-time scaling framework that substantially improves the coverage and selection accuracy of generated code. S* extends the existing parallel scaling paradigm with sequential scaling to push performance boundaries. It further leverages a novel selection mechanism that adaptively generates distinguishing inputs for pairwise comparison, combined with execution-grounded information to robustly identify correct solutions. We evaluate across 12 Large Language Models and Large Reasoning Model and show: (1) S* consistently improves performance across model families and sizes, enabling a 3B model to outperform GPT-4o-mini; (2) S* enables non-reasoning models to surpass reasoning models - GPT-4o-mini with S* outperforms o1-preview by 3.7% on LiveCodeBench; (3) S* further boosts state-of-the-art reasoning models - DeepSeek-R1-Distill-Qwen-32B with S* achieves 85.7% on LiveCodeBench, approaching o1 (high) at 88.5%. Code will be available under https://github.com/NovaSky-AI/SkyThought.
LLMs Can Easily Learn to Reason from Demonstrations Structure, not content, is what matters!
Feb 11, 2025Large reasoning models (LRMs) tackle complex reasoning problems by following long chain-of-thoughts (Long CoT) that incorporate reflection, backtracking, and self-validation. However, the training techniques and data requirements to elicit Long CoT remain poorly understood. In this work, we find that a Large Language model (LLM) can effectively learn Long CoT reasoning through data-efficient supervised fine-tuning (SFT) and parameter-efficient low-rank adaptation (LoRA). With just 17k long CoT training samples, the Qwen2.5-32B-Instruct model achieves significant improvements on a wide range of math and coding benchmarks, including 56.7% (+40.0%) on AIME 2024 and 57.0% (+8.1%) on LiveCodeBench, competitive to the proprietary o1-preview model's score of 44.6% and 59.1%. More importantly, we find that the structure of Long CoT is critical to the learning process, whereas the content of individual reasoning steps has minimal impact. Perturbations affecting content, such as training on incorrect samples or removing reasoning keywords, have little impact on performance. In contrast, structural modifications that disrupt logical consistency in the Long CoT, such as shuffling or deleting reasoning steps, significantly degrade accuracy. For example, a model trained on Long CoT samples with incorrect answers still achieves only 3.2% lower accuracy compared to training with fully correct samples. These insights deepen our understanding of how to elicit reasoning capabilities in LLMs and highlight key considerations for efficiently training the next generation of reasoning models. This is the academic paper of our previous released Sky-T1-32B-Preview model. Codes are available at https://github.com/NovaSky-AI/SkyThought.
Locality-aware Fair Scheduling in LLM Serving
Jan 24, 2025

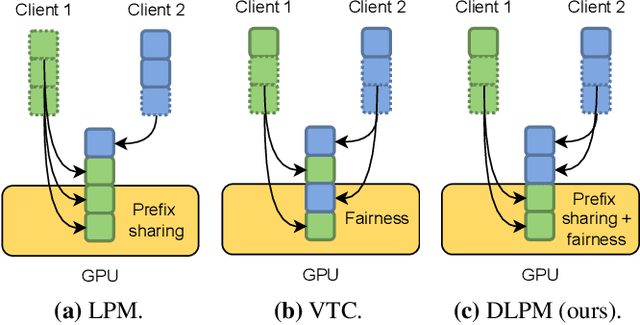
Large language model (LLM) inference workload dominates a wide variety of modern AI applications, ranging from multi-turn conversation to document analysis. Balancing fairness and efficiency is critical for managing diverse client workloads with varying prefix patterns. Unfortunately, existing fair scheduling algorithms for LLM serving, such as Virtual Token Counter (VTC), fail to take prefix locality into consideration and thus suffer from poor performance. On the other hand, locality-aware scheduling algorithms in existing LLM serving frameworks tend to maximize the prefix cache hit rate without considering fair sharing among clients. This paper introduces the first locality-aware fair scheduling algorithm, Deficit Longest Prefix Match (DLPM), which can maintain a high degree of prefix locality with a fairness guarantee. We also introduce a novel algorithm, Double Deficit LPM (D$^2$LPM), extending DLPM for the distributed setup that can find a balance point among fairness, locality, and load-balancing. Our extensive evaluation demonstrates the superior performance of DLPM and D$^2$LPM in ensuring fairness while maintaining high throughput (up to 2.87$\times$ higher than VTC) and low per-client (up to 7.18$\times$ lower than state-of-the-art distributed LLM serving system) latency.
NVILA: Efficient Frontier Visual Language Models
Dec 05, 2024
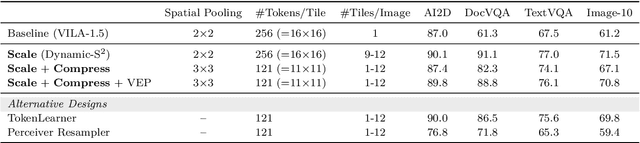

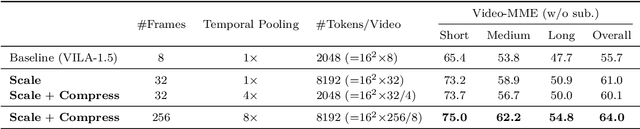
Visual language models (VLMs) have made significant advances in accuracy in recent years. However, their efficiency has received much less attention. This paper introduces NVILA, a family of open VLMs designed to optimize both efficiency and accuracy. Building on top of VILA, we improve its model architecture by first scaling up the spatial and temporal resolutions, and then compressing visual tokens. This "scale-then-compress" approach enables NVILA to efficiently process high-resolution images and long videos. We also conduct a systematic investigation to enhance the efficiency of NVILA throughout its entire lifecycle, from training and fine-tuning to deployment. NVILA matches or surpasses the accuracy of many leading open and proprietary VLMs across a wide range of image and video benchmarks. At the same time, it reduces training costs by 4.5X, fine-tuning memory usage by 3.4X, pre-filling latency by 1.6-2.2X, and decoding latency by 1.2-2.8X. We will soon make our code and models available to facilitate reproducibility.
MoE-Lightning: High-Throughput MoE Inference on Memory-constrained GPUs
Nov 18, 2024



Efficient deployment of large language models, particularly Mixture of Experts (MoE), on resource-constrained platforms presents significant challenges, especially in terms of computational efficiency and memory utilization. The MoE architecture, renowned for its ability to increase model capacity without a proportional increase in inference cost, greatly reduces the token generation latency compared with dense models. However, the large model size makes MoE models inaccessible to individuals without high-end GPUs. In this paper, we propose a high-throughput MoE batch inference system, that significantly outperforms past work. MoE-Lightning introduces a novel CPU-GPU-I/O pipelining schedule, CGOPipe, with paged weights to achieve high resource utilization, and a performance model, HRM, based on a Hierarchical Roofline Model we introduce to help find policies with higher throughput than existing systems. MoE-Lightning can achieve up to 10.3x higher throughput than state-of-the-art offloading-enabled LLM inference systems for Mixtral 8x7B on a single T4 GPU (16GB). When the theoretical system throughput is bounded by the GPU memory, MoE-Lightning can reach the throughput upper bound with 2-3x less CPU memory, significantly increasing resource utilization. MoE-Lightning also supports efficient batch inference for much larger MoEs (e.g., Mixtral 8x22B and DBRX) on multiple low-cost GPUs (e.g., 2-4 T4).
NEO: Saving GPU Memory Crisis with CPU Offloading for Online LLM Inference
Nov 02, 2024


Online LLM inference powers many exciting applications such as intelligent chatbots and autonomous agents. Modern LLM inference engines widely rely on request batching to improve inference throughput, aiming to make it cost-efficient when running on expensive GPU accelerators. However, the limited GPU memory has largely limited the batch size achieved in practice, leaving significant GPU compute resources wasted. We present NEO, an online LLM inference system that offloads part of attention compute and KV cache states from the GPU to the local host CPU, effectively increasing the GPU batch size and thus inference throughput. To this end, NEO proposes asymmetric GPU-CPU pipelining and load-aware scheduling to balance GPU and CPU loads and fully utilize their compute and memory resources. We evaluate NEO on a wide range of workloads (i.e., code generation, text summarization), GPUs (i.e., T4, A10G, H100), and LLM models (i.e., 7B, 8B, 70B). NEO achieves up to 7.5$\times$, 26%, and 14% higher throughput compared to GPU-only approach on T4, A10G, and H100 GPUs, respectively, while maintaining the same latency; with more powerful CPUs, NEO achieves up to 79.3% throughput gain on A10G GPU.
GraphPipe: Improving Performance and Scalability of DNN Training with Graph Pipeline Parallelism
Jun 24, 2024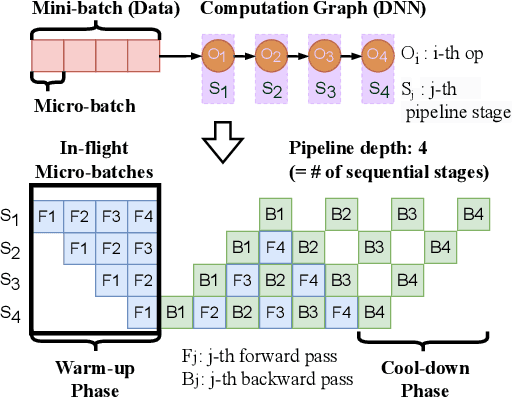

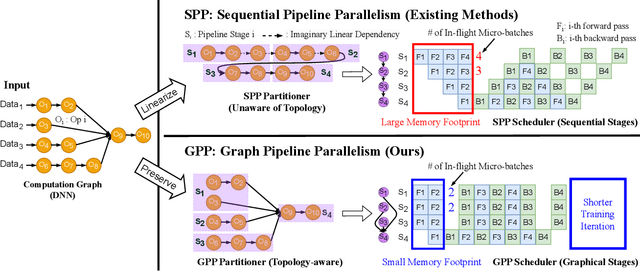
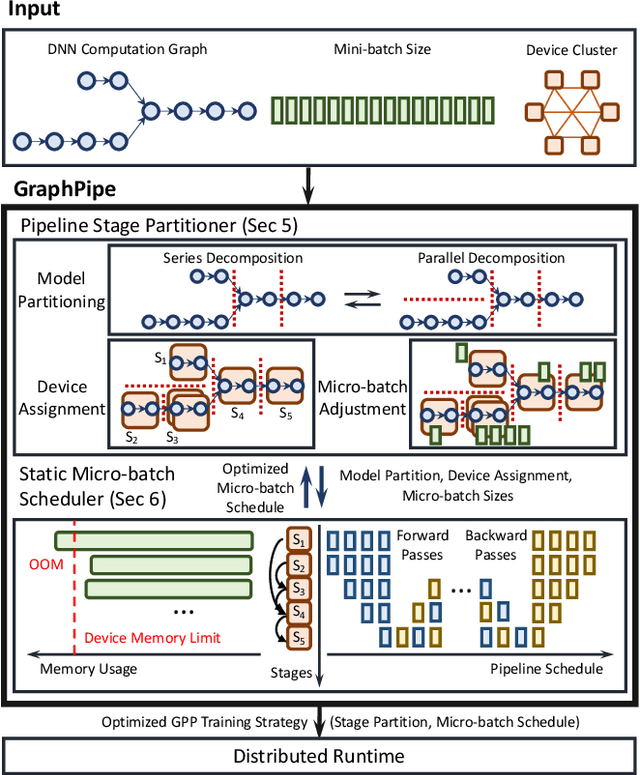
Deep neural networks (DNNs) continue to grow rapidly in size, making them infeasible to train on a single device. Pipeline parallelism is commonly used in existing DNN systems to support large-scale DNN training by partitioning a DNN into multiple stages, which concurrently perform DNN training for different micro-batches in a pipeline fashion. However, existing pipeline-parallel approaches only consider sequential pipeline stages and thus ignore the topology of a DNN, resulting in missed model-parallel opportunities. This paper presents graph pipeline parallelism (GPP), a new pipeline-parallel scheme that partitions a DNN into pipeline stages whose dependencies are identified by a directed acyclic graph. GPP generalizes existing sequential pipeline parallelism and preserves the inherent topology of a DNN to enable concurrent execution of computationally-independent operators, resulting in reduced memory requirement and improved GPU performance. In addition, we develop GraphPipe, a distributed system that exploits GPP strategies to enable performant and scalable DNN training. GraphPipe partitions a DNN into a graph of stages, optimizes micro-batch schedules for these stages, and parallelizes DNN training using the discovered GPP strategies. Evaluation on a variety of DNNs shows that GraphPipe outperforms existing pipeline-parallel systems such as PipeDream and Piper by up to 1.6X. GraphPipe also reduces the search time by 9-21X compared to PipeDream and Piper.
Buffer of Thoughts: Thought-Augmented Reasoning with Large Language Models
Jun 06, 2024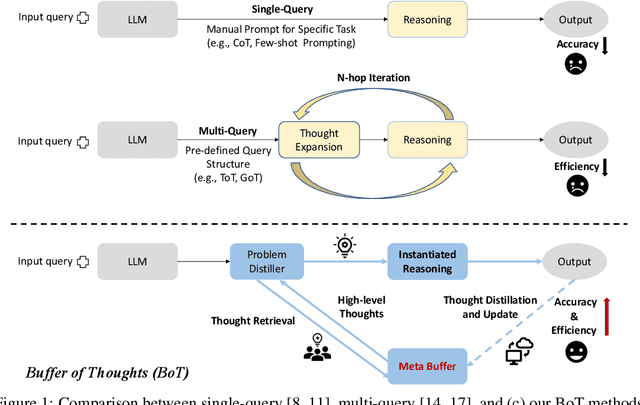
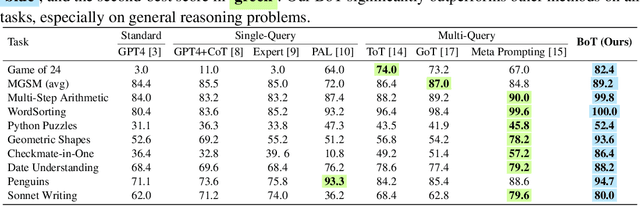
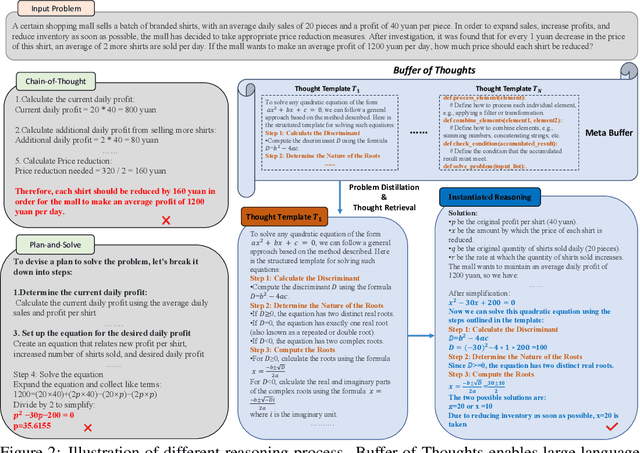
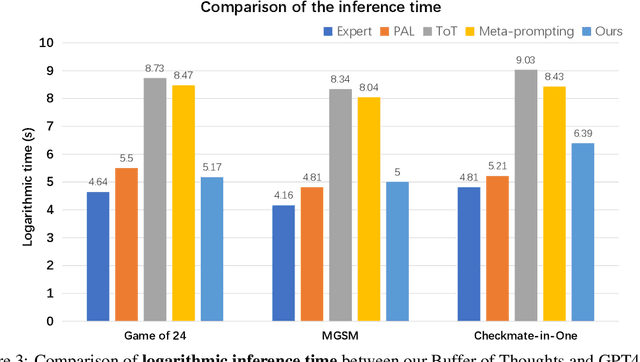
We introduce Buffer of Thoughts (BoT), a novel and versatile thought-augmented reasoning approach for enhancing accuracy, efficiency and robustness of large language models (LLMs). Specifically, we propose meta-buffer to store a series of informative high-level thoughts, namely thought-template, distilled from the problem-solving processes across various tasks. Then for each problem, we retrieve a relevant thought-template and adaptively instantiate it with specific reasoning structures to conduct efficient reasoning. To guarantee the scalability and stability, we further propose buffer-manager to dynamically update the meta-buffer, thus enhancing the capacity of meta-buffer as more tasks are solved. We conduct extensive experiments on 10 challenging reasoning-intensive tasks, and achieve significant performance improvements over previous SOTA methods: 11% on Game of 24, 20% on Geometric Shapes and 51% on Checkmate-in-One. Further analysis demonstrate the superior generalization ability and model robustness of our BoT, while requiring only 12% of the cost of multi-query prompting methods (e.g., tree/graph of thoughts) on average. Notably, we find that our Llama3-8B+BoT has the potential to surpass Llama3-70B model. Our project is available at: https://github.com/YangLing0818/buffer-of-thought-llm