 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJet-RL: Enabling On-Policy FP8 Reinforcement Learning with Unified Training and Rollout Precision Flow
Jan 20, 2026Reinforcement learning (RL) is essential for enhancing the complex reasoning capabilities of large language models (LLMs). However, existing RL training pipelines are computationally inefficient and resource-intensive, with the rollout phase accounting for over 70% of total training time. Quantized RL training, particularly using FP8 precision, offers a promising approach to mitigating this bottleneck. A commonly adopted strategy applies FP8 precision during rollout while retaining BF16 precision for training. In this work, we present the first comprehensive study of FP8 RL training and demonstrate that the widely used BF16-training + FP8-rollout strategy suffers from severe training instability and catastrophic accuracy collapse under long-horizon rollouts and challenging tasks. Our analysis shows that these failures stem from the off-policy nature of the approach, which introduces substantial numerical mismatch between training and inference. Motivated by these observations, we propose Jet-RL, an FP8 RL training framework that enables robust and stable RL optimization. The key idea is to adopt a unified FP8 precision flow for both training and rollout, thereby minimizing numerical discrepancies and eliminating the need for inefficient inter-step calibration. Extensive experiments validate the effectiveness of Jet-RL: our method achieves up to 33% speedup in the rollout phase, up to 41% speedup in the training phase, and a 16% end-to-end speedup over BF16 training, while maintaining stable convergence across all settings and incurring negligible accuracy degradation.
GraphPipe: Improving Performance and Scalability of DNN Training with Graph Pipeline Parallelism
Jun 24, 2024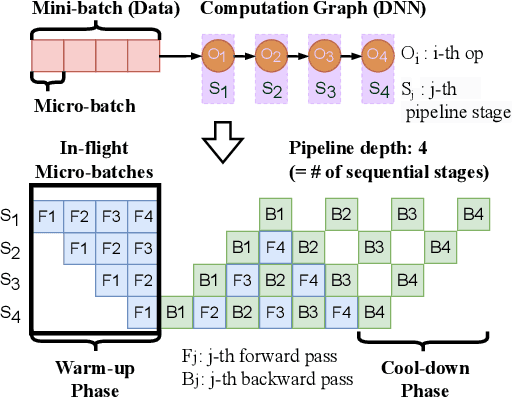

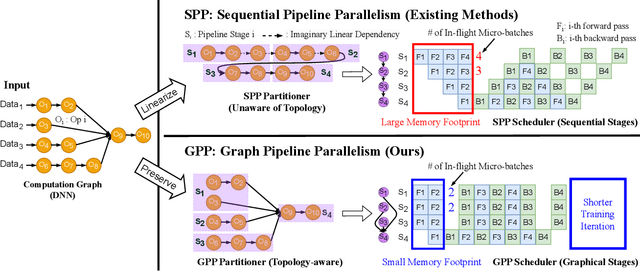
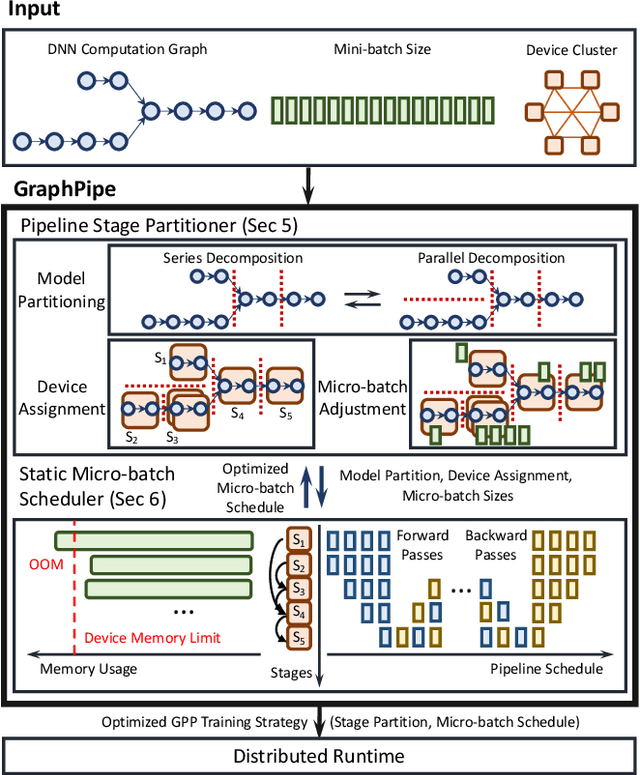
Deep neural networks (DNNs) continue to grow rapidly in size, making them infeasible to train on a single device. Pipeline parallelism is commonly used in existing DNN systems to support large-scale DNN training by partitioning a DNN into multiple stages, which concurrently perform DNN training for different micro-batches in a pipeline fashion. However, existing pipeline-parallel approaches only consider sequential pipeline stages and thus ignore the topology of a DNN, resulting in missed model-parallel opportunities. This paper presents graph pipeline parallelism (GPP), a new pipeline-parallel scheme that partitions a DNN into pipeline stages whose dependencies are identified by a directed acyclic graph. GPP generalizes existing sequential pipeline parallelism and preserves the inherent topology of a DNN to enable concurrent execution of computationally-independent operators, resulting in reduced memory requirement and improved GPU performance. In addition, we develop GraphPipe, a distributed system that exploits GPP strategies to enable performant and scalable DNN training. GraphPipe partitions a DNN into a graph of stages, optimizes micro-batch schedules for these stages, and parallelizes DNN training using the discovered GPP strategies. Evaluation on a variety of DNNs shows that GraphPipe outperforms existing pipeline-parallel systems such as PipeDream and Piper by up to 1.6X. GraphPipe also reduces the search time by 9-21X compared to PipeDream and Piper.
The ArtBench Dataset: Benchmarking Generative Models with Artworks
Jun 22, 2022
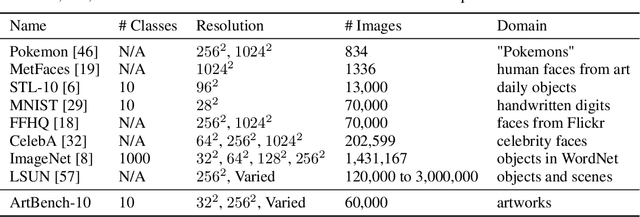
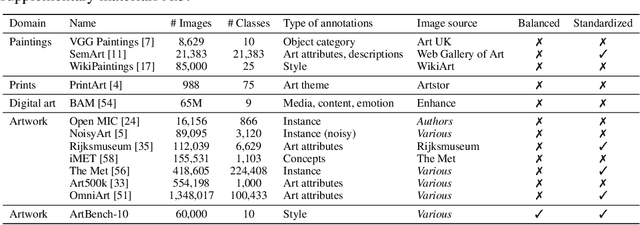
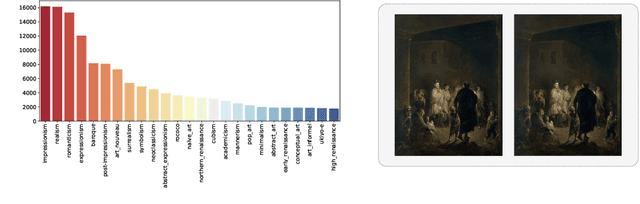
We introduce ArtBench-10, the first class-balanced, high-quality, cleanly annotated, and standardized dataset for benchmarking artwork generation. It comprises 60,000 images of artwork from 10 distinctive artistic styles, with 5,000 training images and 1,000 testing images per style. ArtBench-10 has several advantages over previous artwork datasets. Firstly, it is class-balanced while most previous artwork datasets suffer from the long tail class distributions. Secondly, the images are of high quality with clean annotations. Thirdly, ArtBench-10 is created with standardized data collection, annotation, filtering, and preprocessing procedures. We provide three versions of the dataset with different resolutions ($32\times32$, $256\times256$, and original image size), formatted in a way that is easy to be incorporated by popular machine learning frameworks. We also conduct extensive benchmarking experiments using representative image synthesis models with ArtBench-10 and present in-depth analysis. The dataset is available at https://github.com/liaopeiyuan/artbench under a Fair Use license.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Learning Weakly-Supervised Contrastive Representations
Feb 18, 2022
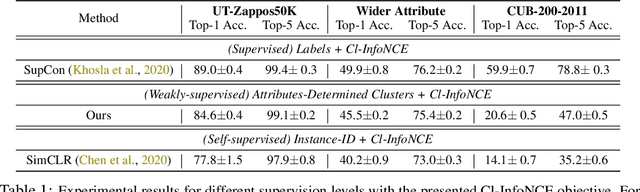

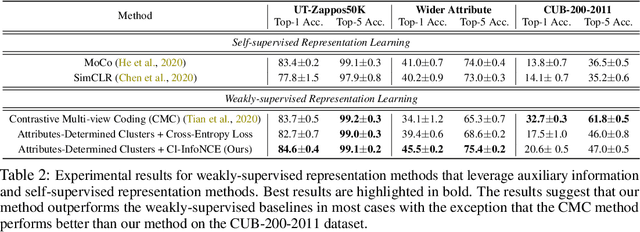
We argue that a form of the valuable information provided by the auxiliary information is its implied data clustering information. For instance, considering hashtags as auxiliary information, we can hypothesize that an Instagram image will be semantically more similar with the same hashtags. With this intuition, we present a two-stage weakly-supervised contrastive learning approach. The first stage is to cluster data according to its auxiliary information. The second stage is to learn similar representations within the same cluster and dissimilar representations for data from different clusters. Our empirical experiments suggest the following three contributions. First, compared to conventional self-supervised representations, the auxiliary-information-infused representations bring the performance closer to the supervised representations, which use direct downstream labels as supervision signals. Second, our approach performs the best in most cases, when comparing our approach with other baseline representation learning methods that also leverage auxiliary data information. Third, we show that our approach also works well with unsupervised constructed clusters (e.g., no auxiliary information), resulting in a strong unsupervised representation learning approach.
Collage: Automated Integration of Deep Learning Backends
Nov 01, 2021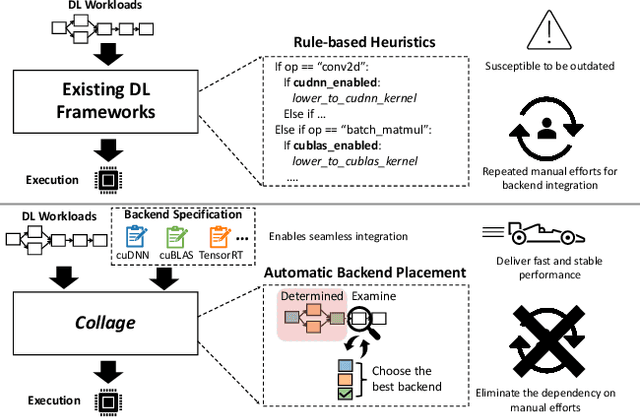
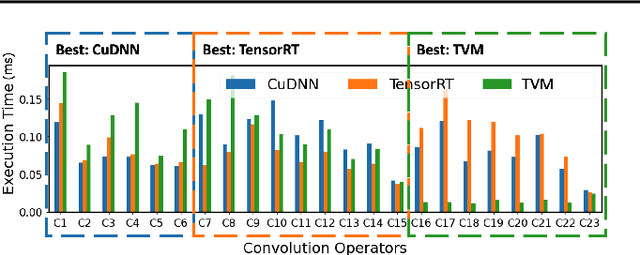
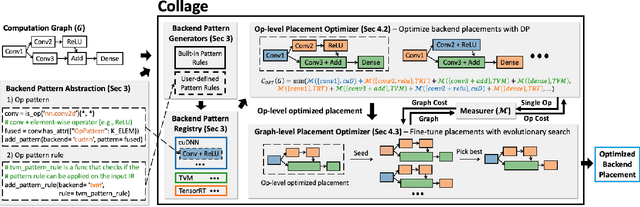
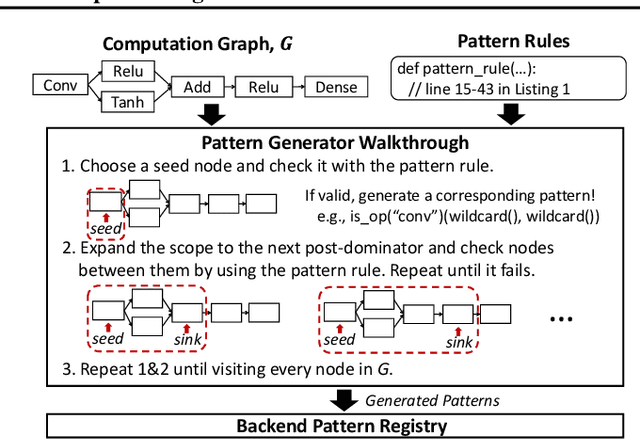
Strong demands for efficient deployment of Deep Learning (DL) applications prompt the rapid development of a rich DL ecosystem. To keep up with its fast advancement, it is crucial for DL frameworks to efficiently integrate a variety of optimized libraries and runtimes as their backends and generate the fastest possible executable by using them properly. However, current DL frameworks require significant manual effort to integrate diverse backends and often fail to deliver high performance. In this paper, we propose Collage, an automatic framework for integrating DL backends. Collage provides a backend registration interface that allows users to precisely specify the capability of various backends. By leveraging the specifications of available backends, Collage searches for an optimized backend placement for a given workload and execution environment. Our evaluation shows that Collage automatically integrates multiple backends together without manual intervention, and outperforms existing frameworks by 1.21x, 1.39x, 1.40x on two different NVIDIA GPUs and an Intel CPU respectively.
Integrating Auxiliary Information in Self-supervised Learning
Jun 05, 2021
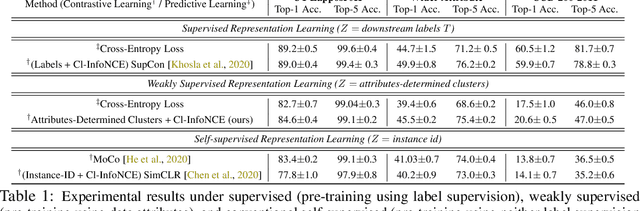
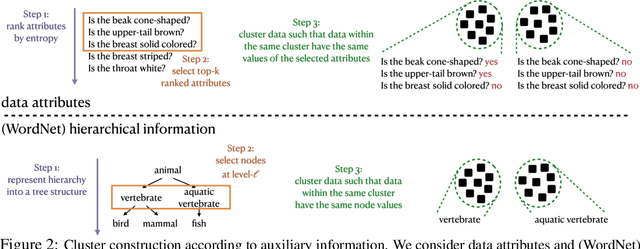
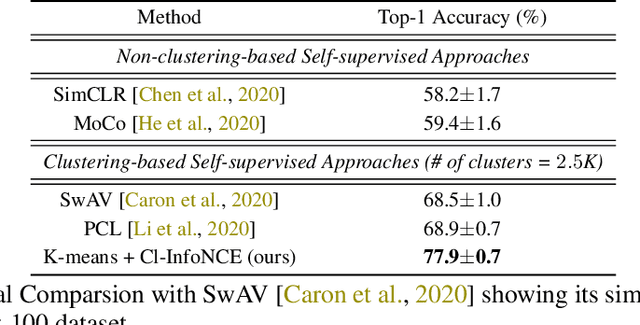
This paper presents to integrate the auxiliary information (e.g., additional attributes for data such as the hashtags for Instagram images) in the self-supervised learning process. We first observe that the auxiliary information may bring us useful information about data structures: for instance, the Instagram images with the same hashtags can be semantically similar. Hence, to leverage the structural information from the auxiliary information, we present to construct data clusters according to the auxiliary information. Then, we introduce the Clustering InfoNCE (Cl-InfoNCE) objective that learns similar representations for augmented variants of data from the same cluster and dissimilar representations for data from different clusters. Our approach contributes as follows: 1) Comparing to conventional self-supervised representations, the auxiliary-information-infused self-supervised representations bring the performance closer to the supervised representations; 2) The presented Cl-InfoNCE can also work with unsupervised constructed clusters (e.g., k-means clusters) and outperform strong clustering-based self-supervised learning approaches, such as the Prototypical Contrastive Learning (PCL) method; 3) We show that Cl-InfoNCE may be a better approach to leverage the data clustering information, by comparing it to the baseline approach - learning to predict the clustering assignments with cross-entropy loss. For analysis, we connect the goodness of the learned representations with the statistical relationships: i) the mutual information between the labels and the clusters and ii) the conditional entropy of the clusters given the labels.
Google Landmark Recognition 2020 Competition Third Place Solution
Oct 11, 2020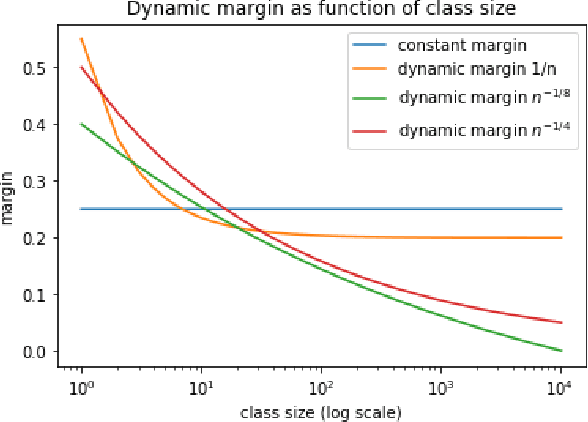

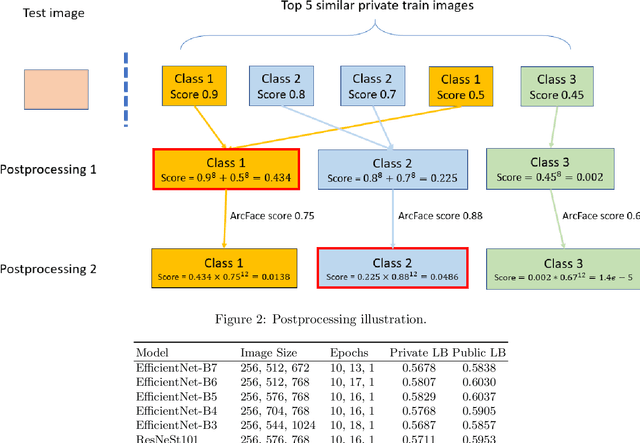
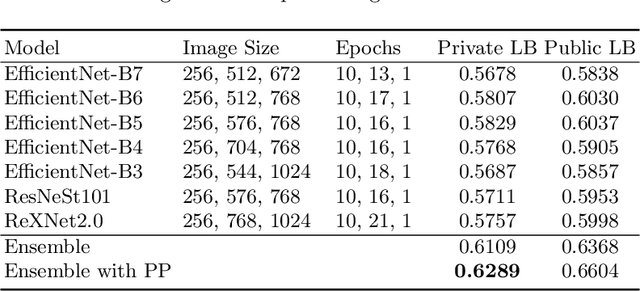
We present our third place solution to the Google Landmark Recognition 2020 competition. It is an ensemble of global features only Sub-center ArcFace models. We introduce dynamic margins for ArcFace loss, a family of tune-able margin functions of class size, designed to deal with the extreme imbalance in GLDv2 dataset. Progressive finetuning and careful postprocessing are also key to the solution. Our two submissions scored 0.6344 and 0.6289 on private leaderboard, both ranking third place out of 736 teams.
Graph Adversarial Networks: Protecting Information against Adversarial Attacks
Oct 07, 2020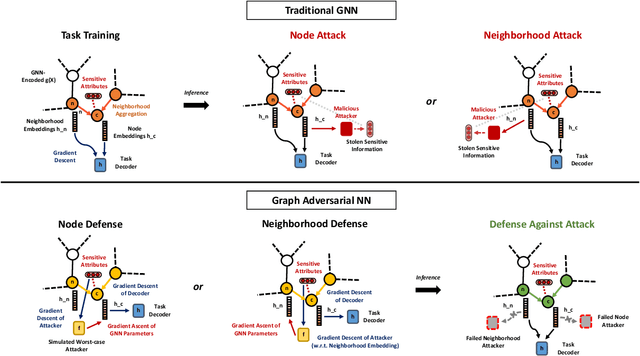
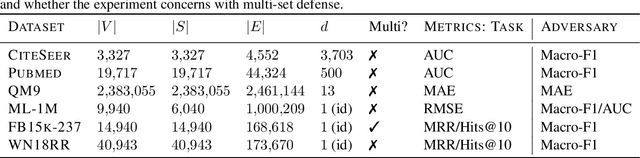
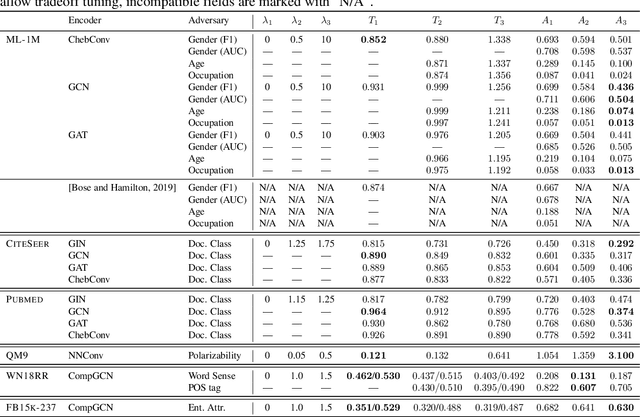
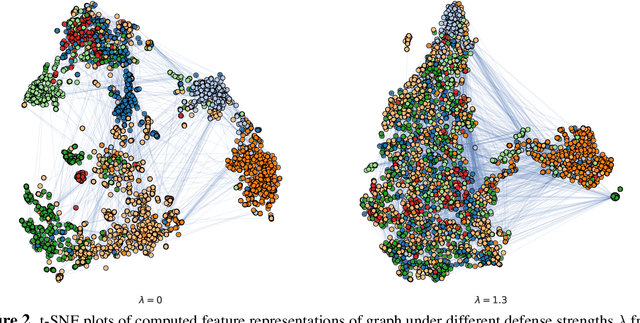
We study the problem of protecting information when learning with graph-structured data. While the advent of Graph Neural Networks (GNNs) has greatly improved node and graph representational learning in many applications, the neighborhood aggregation paradigm exposes additional vulnerabilities to attackers seeking to extract node-level information about sensitive attributes. To counter this, we propose a minimax game between the desired GNN encoder and the worst-case attacker. The resulting adversarial training creates a strong defense against inference attacks, while only suffering a small loss in task performance. We analyze the effectiveness of our framework against a worst-case adversary, and characterize the trade-off between predictive accuracy and adversarial defense. Experiments across multiple datasets from recommender systems, knowledge graphs and quantum chemistry demonstrate that the proposed approach provides a robust defense across various graph structures and tasks, while producing competitive GNN encoders. Our code is available at https://github.com/liaopeiyuan/GAL.
CAE-ADMM: Implicit Bitrate Optimization via ADMM-based Pruning in Compressive Autoencoders
Jan 30, 2019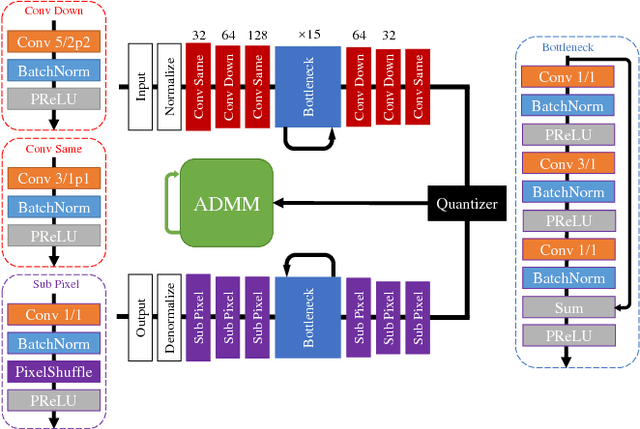

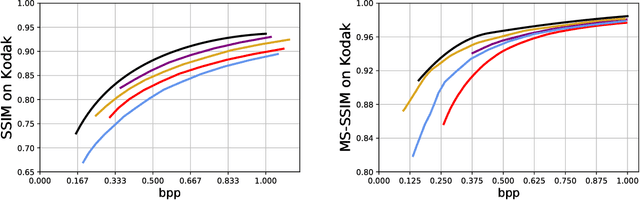

We introduce CAE-ADMM (ADMM-pruned compressive autoencoder), a lossy image compression model, inspired by researches in neural architecture search (NAS) and is capable of implicitly optimizing the bitrate without the use of an entropy estimator. Our experiments show that by introducing alternating direction method of multipliers (ADMM) to the model pipeline, the pruning paradigm yields more accurate results (SSIM/MS-SSIM-wise) when compared to entropy-based approaches and that of traditional codecs (JPEG, JPEG 2000, etc.) while maintaining acceptable inference speed. We further explore the effectiveness of the pruning method in CAE-ADMM by examining the generated latent codes.