 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Scalable Estimation of Tool Representations in Vector Space
Sep 02, 2024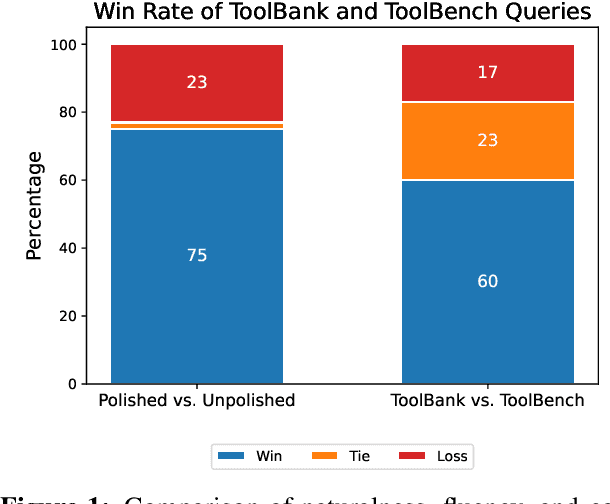
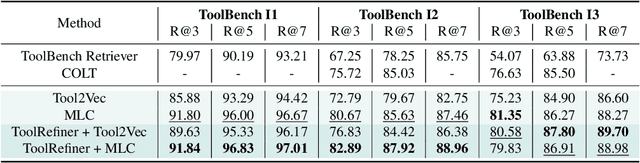
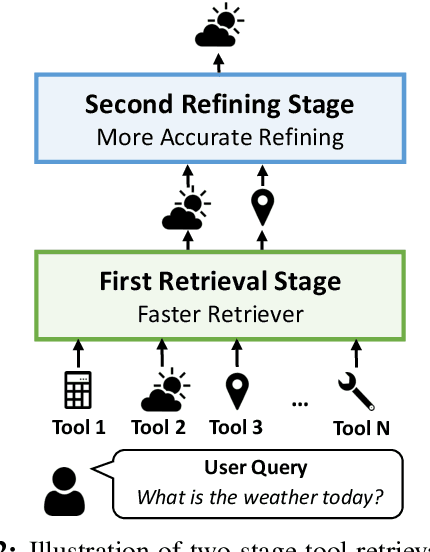
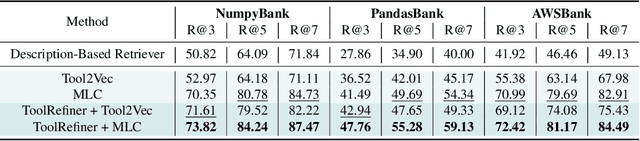
Recent advancements in function calling and tool use have significantly enhanced the capabilities of large language models (LLMs) by enabling them to interact with external information sources and execute complex tasks. However, the limited context window of LLMs presents challenges when a large number of tools are available, necessitating efficient methods to manage prompt length and maintain accuracy. Existing approaches, such as fine-tuning LLMs or leveraging their reasoning capabilities, either require frequent retraining or incur significant latency overhead. A more efficient solution involves training smaller models to retrieve the most relevant tools for a given query, although this requires high quality, domain-specific data. To address those challenges, we present a novel framework for generating synthetic data for tool retrieval applications and an efficient data-driven tool retrieval strategy using small encoder models. Empowered by LLMs, we create ToolBank, a new tool retrieval dataset that reflects real human user usages. For tool retrieval methodologies, we propose novel approaches: (1) Tool2Vec: usage-driven tool embedding generation for tool retrieval, (2) ToolRefiner: a staged retrieval method that iteratively improves the quality of retrieved tools, and (3) MLC: framing tool retrieval as a multi-label classification problem. With these new methods, we achieve improvements of up to 27.28 in Recall@K on the ToolBench dataset and 30.5 in Recall@K on ToolBank. Additionally, we present further experimental results to rigorously validate our methods. Our code is available at \url{https://github.com/SqueezeAILab/Tool2Vec}
TinyAgent: Function Calling at the Edge
Sep 01, 2024



Recent large language models (LLMs) have enabled the development of advanced agentic systems that can integrate various tools and APIs to fulfill user queries through function calling. However, the deployment of these LLMs on the edge has not been explored since they typically require cloud-based infrastructure due to their substantial model size and computational demands. To this end, we present TinyAgent, an end-to-end framework for training and deploying task-specific small language model agents capable of function calling for driving agentic systems at the edge. We first show how to enable accurate function calling for open-source models via the LLMCompiler framework. We then systematically curate a high-quality dataset for function calling, which we use to fine-tune two small language models, TinyAgent-1.1B and 7B. For efficient inference, we introduce a novel tool retrieval method to reduce the input prompt length and utilize quantization to further accelerate the inference speed. As a driving application, we demonstrate a local Siri-like system for Apple's MacBook that can execute user commands through text or voice input. Our results show that our models can achieve, and even surpass, the function-calling capabilities of larger models like GPT-4-Turbo, while being fully deployed at the edge. We open-source our dataset, models, and installable package and provide a demo video for our MacBook assistant agent.
LOTUS: Enabling Semantic Queries with LLMs Over Tables of Unstructured and Structured Data
Jul 16, 2024



The semantic capabilities of language models (LMs) have the potential to enable rich analytics and reasoning over vast knowledge corpora. Unfortunately, existing systems lack high-level abstractions to perform semantic queries at scale. We introduce semantic operators, a declarative programming interface that extends the relational model with composable AI-based operations for semantic queries over datasets (e.g., sorting or aggregating records using natural language criteria). Each operator can be implemented and optimized in multiple ways, opening a rich space for execution plans similar to relational operators. We implement our operators and several optimizations for them in LOTUS, an open-source query engine with a Pandas-like API. We demonstrate LOTUS' effectiveness across a series of real applications, including fact-checking, extreme multi-label classification, and search. We find that LOTUS' programming model is highly expressive, capturing state-of-the-art query pipelines with low development overhead. Specifically, on the FEVER dataset, LOTUS' programs can reproduce FacTool, a recent state-of-the-art fact-checking pipeline, in few lines of code, and implement a new pipeline that improves accuracy by $9.5\%$, while offering $7-34\times$ lower execution time. In the extreme multi-label classification task on the BioDEX dataset, LOTUS reproduces state-of-the art result quality with its join operator, while providing an efficient algorithm that runs $800\times$ faster than a naive join. In the search and ranking application, LOTUS allows a simple composition of operators to achieve $5.9 - 49.4\%$ higher nDCG@10 than the vanilla retriever and re-ranker, while also providing query efficiency, with $1.67 - 10\times$ lower execution time than LM-based ranking methods used by prior works. LOTUS is publicly available at https://github.com/stanford-futuredata/lotus.
Characterizing Prompt Compression Methods for Long Context Inference
Jul 11, 2024
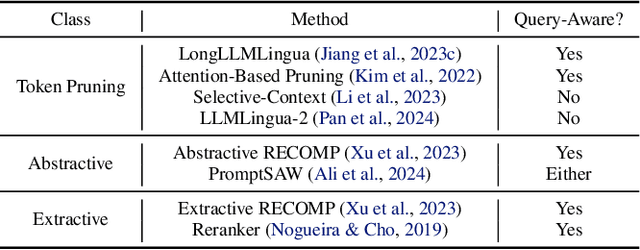
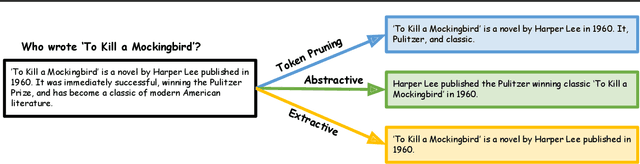

Long context inference presents challenges at the system level with increased compute and memory requirements, as well as from an accuracy perspective in being able to reason over long contexts. Recently, several methods have been proposed to compress the prompt to reduce the context length. However, there has been little work on comparing the different proposed methods across different tasks through a standardized analysis. This has led to conflicting results. To address this, here we perform a comprehensive characterization and evaluation of different prompt compression methods. In particular, we analyze extractive compression, summarization-based abstractive compression, and token pruning methods. Surprisingly, we find that extractive compression often outperforms all the other approaches, and enables up to 10x compression with minimal accuracy degradation. Interestingly, we also find that despite several recent claims, token pruning methods often lag behind extractive compression. We only found marginal improvements on summarization tasks.
Learned Best-Effort LLM Serving
Jan 15, 2024



Many applications must provide low-latency LLM service to users or risk unacceptable user experience. However, over-provisioning resources to serve fluctuating request patterns is often prohibitively expensive. In this work, we present a best-effort serving system that employs deep reinforcement learning to adjust service quality based on the task distribution and system load. Our best-effort system can maintain availability with over 10x higher client request rates, serves above 96% of peak performance 4.1x more often, and serves above 98% of peak performance 2.3x more often than static serving on unpredictable workloads. Our learned router is robust to shifts in both the arrival and task distribution. Compared to static serving, learned best-effort serving allows for cost-efficient serving through increased hardware utility. Additionally, we argue that learned best-effort LLM serving is applicable in wide variety of settings and provides application developers great flexibility to meet their specific needs.
What is the State of Memory Saving for Model Training?
Mar 26, 2023


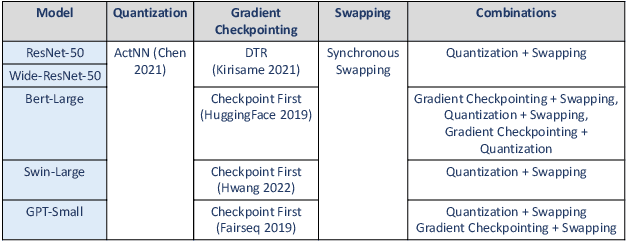
Large neural networks can improve the accuracy and generalization on tasks across many domains. However, this trend cannot continue indefinitely due to limited hardware memory. As a result, researchers have devised a number of memory optimization methods (MOMs) to alleviate the memory bottleneck, such as gradient checkpointing, quantization, and swapping. In this work, we study memory optimization methods and show that, although these strategies indeed lower peak memory usage, they can actually decrease training throughput by up to 9.3x. To provide practical guidelines for practitioners, we propose a simple but effective performance model PAPAYA to quantitatively explain the memory and training time trade-off. PAPAYA can be used to determine when to apply the various memory optimization methods in training different models. We outline the circumstances in which memory optimization techniques are more advantageous based on derived implications from PAPAYA. We assess the accuracy of PAPAYA and the derived implications on a variety of machine models, showing that it achieves over 0.97 R score on predicting the peak memory/throughput, and accurately predicts the effectiveness of MOMs across five evaluated models on vision and NLP tasks.
Linear features segmentation from aerial images
Dec 23, 2022The rapid development of remote sensing technologies have gained significant attention due to their ability to accurately localize, classify, and segment objects from aerial images. These technologies are commonly used in unmanned aerial vehicles (UAVs) equipped with high-resolution cameras or sensors to capture data over large areas. This data is useful for various applications, such as monitoring and inspecting cities, towns, and terrains. In this paper, we presented a method for classifying and segmenting city road traffic dashed lines from aerial images using deep learning models such as U-Net and SegNet. The annotated data is used to train these models, which are then used to classify and segment the aerial image into two classes: dashed lines and non-dashed lines. However, the deep learning model may not be able to identify all dashed lines due to poor painting or occlusion by trees or shadows. To address this issue, we proposed a method to add missed lines to the segmentation output. We also extracted the x and y coordinates of each dashed line from the segmentation output, which can be used by city planners to construct a CAD file for digital visualization of the roads.
Design, Analysis & Prototyping of a Semi-Automated Staircase-Climbing Rehabilitation Robot
Sep 21, 2018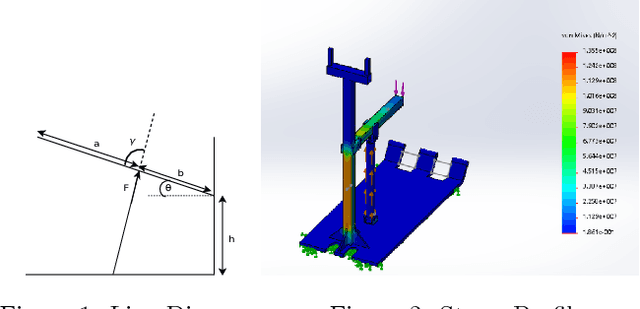
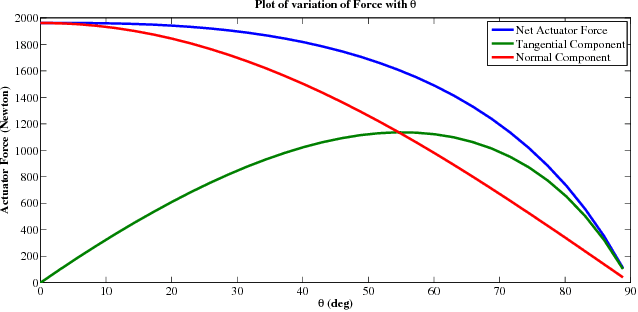
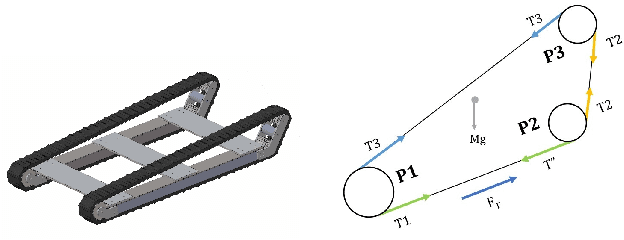
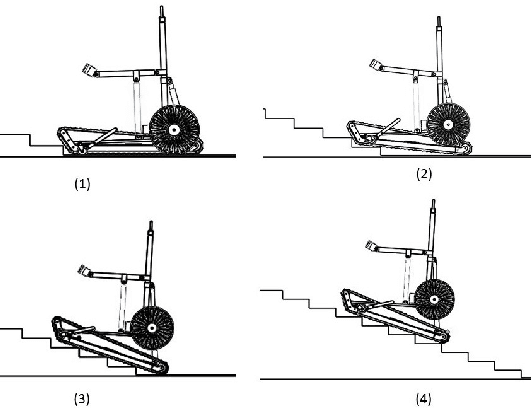
In this paper, we describe the mechanical design, system overview, integration and control techniques associated with SKALA, a unique large-sized robot for carrying a person with physical disabilities, up and down staircases. As a regular wheelchair is unable to perform such a maneuver, the system functions as a non-conventional wheelchair with several intelligent features. We describe the unique mechanical design and the design choices associated with it. We showcase the embedded control architecture that allows for several different modes of teleoperation, all of which have been described in detail. We further investigate the architecture associated with the autonomous operation of the system.
Modeling and Control of an Autonomous Three Wheeled Mobile Robot with Front Steer
Dec 05, 2016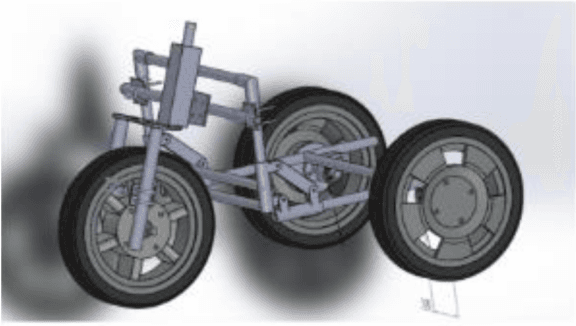
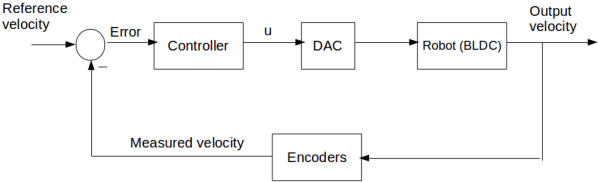
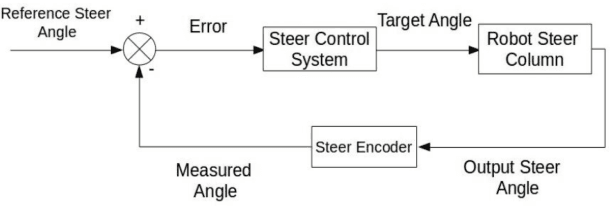
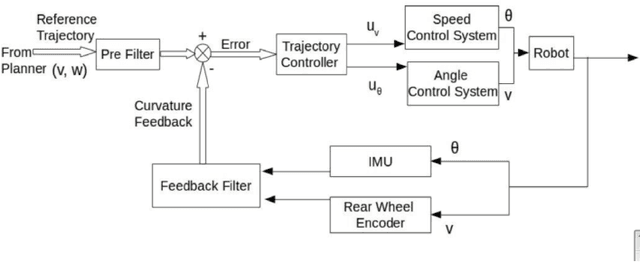
Modeling and control strategies for a design of an autonomous three wheeled mobile robot with front wheel steer is presented. Although, the three-wheel vehicle design with front wheel steer is common in automotive vehicles used often in public transport, but its advantages in navigation and localization of autonomous vehicles is seldom utilized. We present the system model for such a robotic vehicle. A PID controller for speed control is designed for the model obtained and has been implemented in a digital control framework. The trajectory control framework, which is a challenging task for such a three-wheeled robot has also been presented in the paper. The derived system model has been verified using experimental results obtained for the robot vehicle design. Controller performance and robustness issues have also been discussed briefly.
Low Cost Autonomous Navigation and Control of a Mechanically Balanced Bicycle with Dual Locomotion Mode
Nov 01, 2016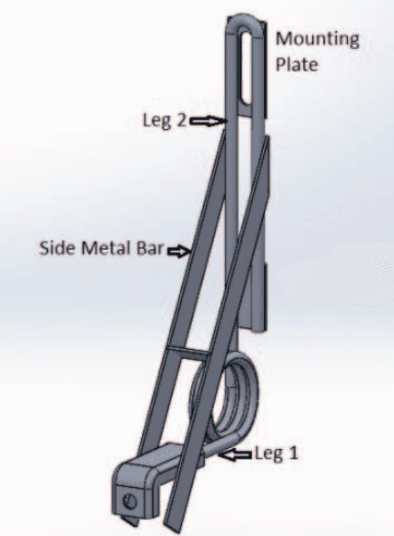
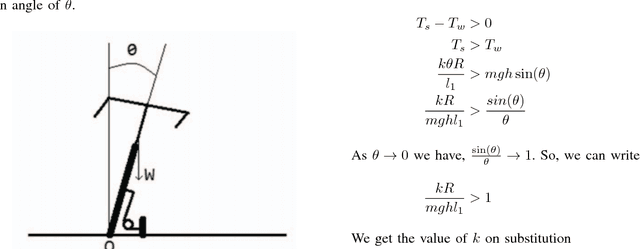
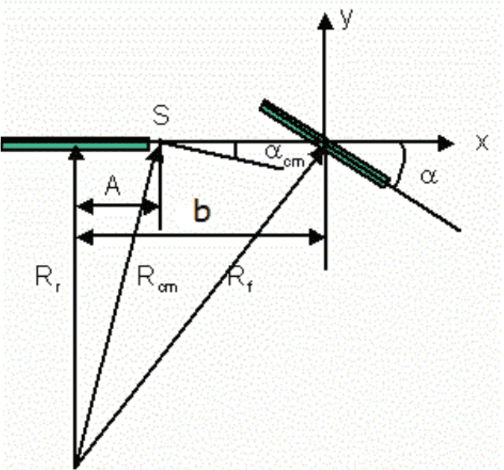
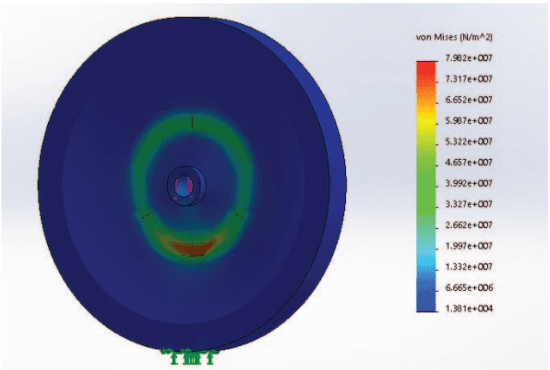
On the lines of the huge and varied efforts in the field of automation with respect to technology development and innovation of vehicles to make them run autonomously, this paper presents an innovation to a bicycle. A normal daily use bicycle was modified at low cost such that it runs autonomously, while maintaining its original form i.e. the manual drive. Hence, a bicycle which could be normally driven by any human and with a press of switch could run autonomously according to the needs of the user has been developed.
* Published in the International Transportation Electrification Conference (ITEC) in 2015 organized by IEEE Industrial Application Society (IAS) and SAE India in Chennai, India