 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepScholar-Bench: A Live Benchmark and Automated Evaluation for Generative Research Synthesis
Aug 27, 2025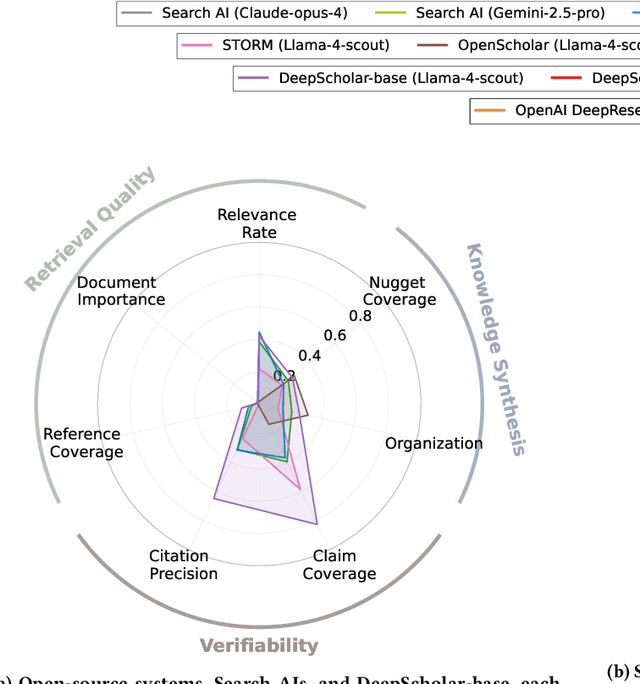
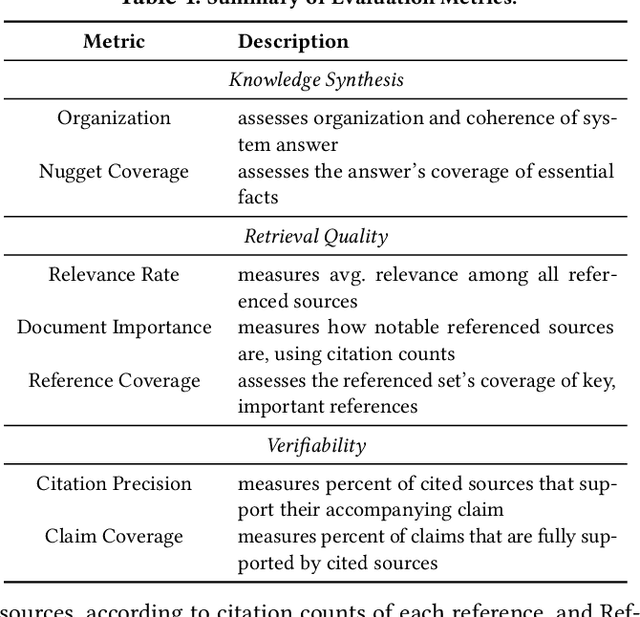
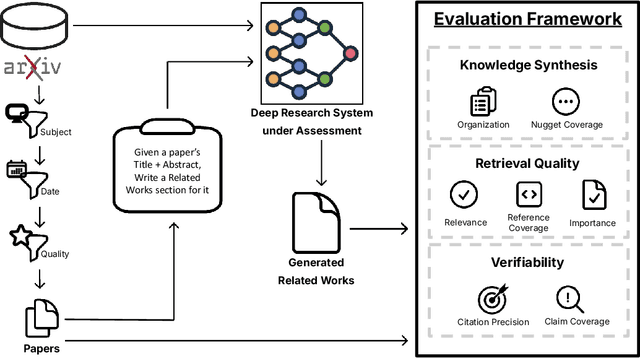
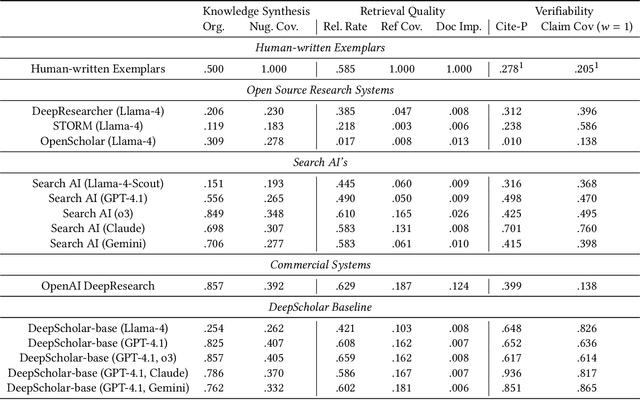
The ability to research and synthesize knowledge is central to human expertise and progress. An emerging class of systems promises these exciting capabilities through generative research synthesis, performing retrieval over the live web and synthesizing discovered sources into long-form, cited summaries. However, evaluating such systems remains an open challenge: existing question-answering benchmarks focus on short-form factual responses, while expert-curated datasets risk staleness and data contamination. Both fail to capture the complexity and evolving nature of real research synthesis tasks. In this work, we introduce DeepScholar-bench, a live benchmark and holistic, automated evaluation framework designed to evaluate generative research synthesis. DeepScholar-bench draws queries from recent, high-quality ArXiv papers and focuses on a real research synthesis task: generating the related work sections of a paper by retrieving, synthesizing, and citing prior research. Our evaluation framework holistically assesses performance across three key dimensions, knowledge synthesis, retrieval quality, and verifiability. We also develop DeepScholar-base, a reference pipeline implemented efficiently using the LOTUS API. Using the DeepScholar-bench framework, we perform a systematic evaluation of prior open-source systems, search AI's, OpenAI's DeepResearch, and DeepScholar-base. We find that DeepScholar-base establishes a strong baseline, attaining competitive or higher performance than each other method. We also find that DeepScholar-bench remains far from saturated, with no system exceeding a score of $19\%$ across all metrics. These results underscore the difficulty of DeepScholar-bench, as well as its importance for progress towards AI systems capable of generative research synthesis. We make our code available at https://github.com/guestrin-lab/deepscholar-bench.
Text2SQL is Not Enough: Unifying AI and Databases with TAG
Aug 27, 2024



AI systems that serve natural language questions over databases promise to unlock tremendous value. Such systems would allow users to leverage the powerful reasoning and knowledge capabilities of language models (LMs) alongside the scalable computational power of data management systems. These combined capabilities would empower users to ask arbitrary natural language questions over custom data sources. However, existing methods and benchmarks insufficiently explore this setting. Text2SQL methods focus solely on natural language questions that can be expressed in relational algebra, representing a small subset of the questions real users wish to ask. Likewise, Retrieval-Augmented Generation (RAG) considers the limited subset of queries that can be answered with point lookups to one or a few data records within the database. We propose Table-Augmented Generation (TAG), a unified and general-purpose paradigm for answering natural language questions over databases. The TAG model represents a wide range of interactions between the LM and database that have been previously unexplored and creates exciting research opportunities for leveraging the world knowledge and reasoning capabilities of LMs over data. We systematically develop benchmarks to study the TAG problem and find that standard methods answer no more than 20% of queries correctly, confirming the need for further research in this area. We release code for the benchmark at https://github.com/TAG-Research/TAG-Bench.
LOTUS: Enabling Semantic Queries with LLMs Over Tables of Unstructured and Structured Data
Jul 16, 2024



The semantic capabilities of language models (LMs) have the potential to enable rich analytics and reasoning over vast knowledge corpora. Unfortunately, existing systems lack high-level abstractions to perform semantic queries at scale. We introduce semantic operators, a declarative programming interface that extends the relational model with composable AI-based operations for semantic queries over datasets (e.g., sorting or aggregating records using natural language criteria). Each operator can be implemented and optimized in multiple ways, opening a rich space for execution plans similar to relational operators. We implement our operators and several optimizations for them in LOTUS, an open-source query engine with a Pandas-like API. We demonstrate LOTUS' effectiveness across a series of real applications, including fact-checking, extreme multi-label classification, and search. We find that LOTUS' programming model is highly expressive, capturing state-of-the-art query pipelines with low development overhead. Specifically, on the FEVER dataset, LOTUS' programs can reproduce FacTool, a recent state-of-the-art fact-checking pipeline, in few lines of code, and implement a new pipeline that improves accuracy by $9.5\%$, while offering $7-34\times$ lower execution time. In the extreme multi-label classification task on the BioDEX dataset, LOTUS reproduces state-of-the art result quality with its join operator, while providing an efficient algorithm that runs $800\times$ faster than a naive join. In the search and ranking application, LOTUS allows a simple composition of operators to achieve $5.9 - 49.4\%$ higher nDCG@10 than the vanilla retriever and re-ranker, while also providing query efficiency, with $1.67 - 10\times$ lower execution time than LM-based ranking methods used by prior works. LOTUS is publicly available at https://github.com/stanford-futuredata/lotus.
ACORN: Performant and Predicate-Agnostic Search Over Vector Embeddings and Structured Data
Mar 07, 2024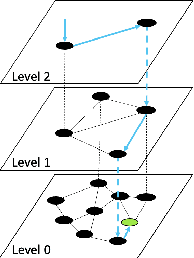

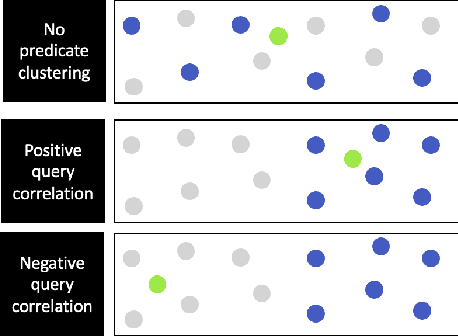
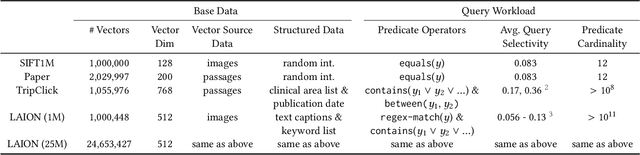
Applications increasingly leverage mixed-modality data, and must jointly search over vector data, such as embedded images, text and video, as well as structured data, such as attributes and keywords. Proposed methods for this hybrid search setting either suffer from poor performance or support a severely restricted set of search predicates (e.g., only small sets of equality predicates), making them impractical for many applications. To address this, we present ACORN, an approach for performant and predicate-agnostic hybrid search. ACORN builds on Hierarchical Navigable Small Worlds (HNSW), a state-of-the-art graph-based approximate nearest neighbor index, and can be implemented efficiently by extending existing HNSW libraries. ACORN introduces the idea of predicate subgraph traversal to emulate a theoretically ideal, but impractical, hybrid search strategy. ACORN's predicate-agnostic construction algorithm is designed to enable this effective search strategy, while supporting a wide array of predicate sets and query semantics. We systematically evaluate ACORN on both prior benchmark datasets, with simple, low-cardinality predicate sets, and complex multi-modal datasets not supported by prior methods. We show that ACORN achieves state-of-the-art performance on all datasets, outperforming prior methods with 2-1,000x higher throughput at a fixed recall.