 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior-Fitted Functional Flow: In-Context Generative Models for Pharmacokinetics
Apr 19, 2026We introduce Prior-Fitted Functional Flows, a generative foundation model for pharmacokinetics that enables zero-shot population synthesis and individual forecasting without manual parameter tuning. We learn functional vector fields, explicitly conditioned on the sparse, irregular data of an entire study population. This enables the generation of coherent virtual cohorts as well as forecasting of partially observed patient trajectories with calibrated uncertainty. We construct a new open-access literature corpus to inform our priors, and demonstrate state-of-the-art predictive accuracy on extensive real-world datasets.
A Diffusion-Driven Fine-Grained Nodule Synthesis Framework for Enhanced Lung Nodule Detection from Chest Radiographs
Mar 02, 2026Early detection of lung cancer in chest radiographs (CXRs) is crucial for improving patient outcomes, yet nodule detection remains challenging due to their subtle appearance and variability in radiological characteristics like size, texture, and boundary. For robust analysis, this diversity must be well represented in training datasets for deep learning based Computer-Assisted Diagnosis (CAD) systems. However, assembling such datasets is costly and often impractical, motivating the need for realistic synthetic data generation. Existing methods lack fine-grained control over synthetic nodule generation, limiting their utility in addressing data scarcity. This paper proposes a novel diffusion-based framework with low-rank adaptation (LoRA) adapters for characteristic controlled nodule synthesis on CXRs. We begin by addressing size and shape control through nodule mask conditioned training of the base diffusion model. To achieve individual characteristic control, we train separate LoRA modules, each dedicated to a specific radiological feature. However, since nodules rarely exhibit isolated characteristics, effective multi-characteristic control requires a balanced integration of features. We address this by leveraging the dynamic composability of LoRAs and revisiting existing merging strategies. Building on this, we identify two key issues, overlapping attention regions and non-orthogonal parameter spaces. To overcome these limitations, we introduce a novel orthogonality loss term during LoRA composition training. Extensive experiments on both in-house and public datasets demonstrate improved downstream nodule detection. Radiologist evaluations confirm the fine-grained controllability of our generated nodules, and across multiple quantitative metrics, our method surpasses existing nodule generation approaches for CXRs.
Partition of Unity Physics-Informed Neural Networks (POU-PINNs): An Unsupervised Framework for Physics-Informed Domain Decomposition and Mixtures of Experts
Dec 07, 2024
Physics-informed neural networks (PINNs) commonly address ill-posed inverse problems by uncovering unknown physics. This study presents a novel unsupervised learning framework that identifies spatial subdomains with specific governing physics. It uses the partition of unity networks (POUs) to divide the space into subdomains, assigning unique nonlinear model parameters to each, which are integrated into the physics model. A vital feature of this method is a physics residual-based loss function that detects variations in physical properties without requiring labeled data. This approach enables the discovery of spatial decompositions and nonlinear parameters in partial differential equations (PDEs), optimizing the solution space by dividing it into subdomains and improving accuracy. Its effectiveness is demonstrated through applications in porous media thermal ablation and ice-sheet modeling, showcasing its potential for tackling real-world physics challenges.
ShieldGemma: Generative AI Content Moderation Based on Gemma
Jul 31, 2024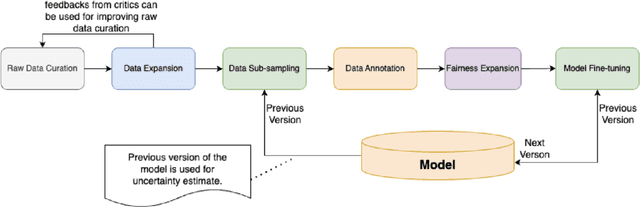
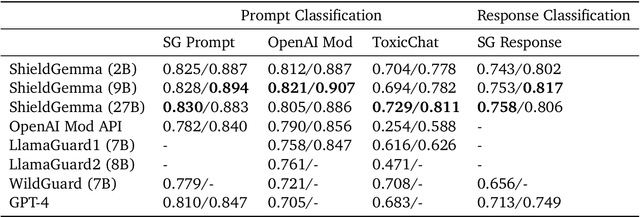

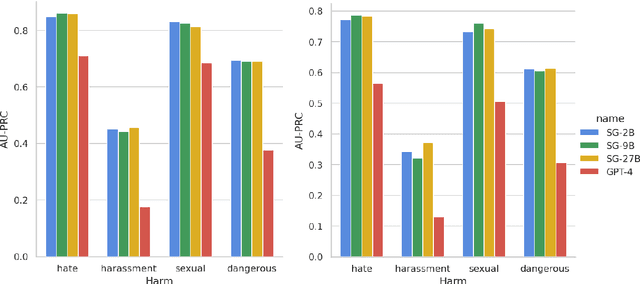
We present ShieldGemma, a comprehensive suite of LLM-based safety content moderation models built upon Gemma2. These models provide robust, state-of-the-art predictions of safety risks across key harm types (sexually explicit, dangerous content, harassment, hate speech) in both user input and LLM-generated output. By evaluating on both public and internal benchmarks, we demonstrate superior performance compared to existing models, such as Llama Guard (+10.8\% AU-PRC on public benchmarks) and WildCard (+4.3\%). Additionally, we present a novel LLM-based data curation pipeline, adaptable to a variety of safety-related tasks and beyond. We have shown strong generalization performance for model trained mainly on synthetic data. By releasing ShieldGemma, we provide a valuable resource to the research community, advancing LLM safety and enabling the creation of more effective content moderation solutions for developers.
Malicious Path Manipulations via Exploitation of Representation Vulnerabilities of Vision-Language Navigation Systems
Jul 10, 2024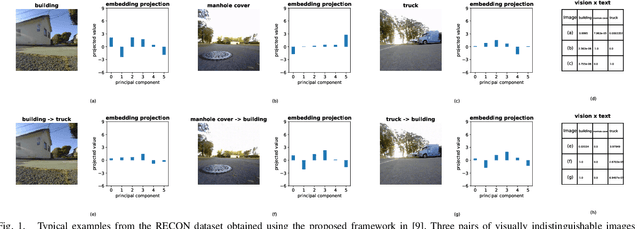

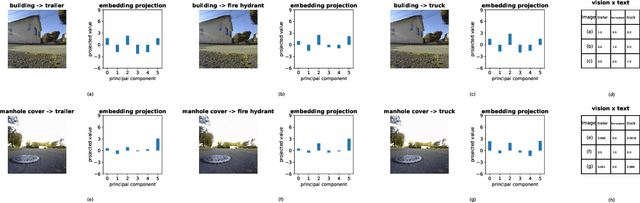
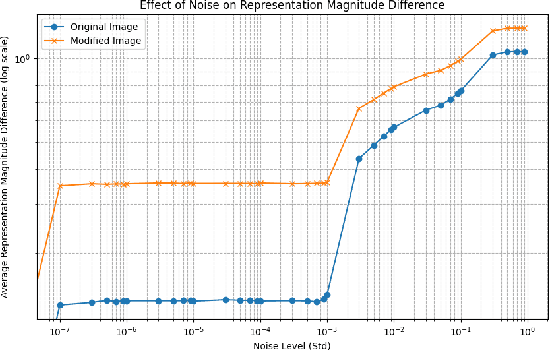
Building on the unprecedented capabilities of large language models for command understanding and zero-shot recognition of multi-modal vision-language transformers, visual language navigation (VLN) has emerged as an effective way to address multiple fundamental challenges toward a natural language interface to robot navigation. However, such vision-language models are inherently vulnerable due to the lack of semantic meaning of the underlying embedding space. Using a recently developed gradient based optimization procedure, we demonstrate that images can be modified imperceptibly to match the representation of totally different images and unrelated texts for a vision-language model. Building on this, we develop algorithms that can adversarially modify a minimal number of images so that the robot will follow a route of choice for commands that require a number of landmarks. We demonstrate that experimentally using a recently proposed VLN system; for a given navigation command, a robot can be made to follow drastically different routes. We also develop an efficient algorithm to detect such malicious modifications reliably based on the fact that the adversarially modified images have much higher sensitivity to added Gaussian noise than the original images.
Machine Learning Models for Improved Tracking from Range-Doppler Map Images
Jul 03, 2024Statistical tracking filters depend on accurate target measurements and uncertainty estimates for good tracking performance. In this work, we propose novel machine learning models for target detection and uncertainty estimation in range-Doppler map (RDM) images for Ground Moving Target Indicator (GMTI) radars. We show that by using the outputs of these models, we can significantly improve the performance of a multiple hypothesis tracker for complex multi-target air-to-ground tracking scenarios.
On Regularization and Inference with Label Constraints
Jul 08, 2023

Prior knowledge and symbolic rules in machine learning are often expressed in the form of label constraints, especially in structured prediction problems. In this work, we compare two common strategies for encoding label constraints in a machine learning pipeline, regularization with constraints and constrained inference, by quantifying their impact on model performance. For regularization, we show that it narrows the generalization gap by precluding models that are inconsistent with the constraints. However, its preference for small violations introduces a bias toward a suboptimal model. For constrained inference, we show that it reduces the population risk by correcting a model's violation, and hence turns the violation into an advantage. Given these differences, we further explore the use of two approaches together and propose conditions for constrained inference to compensate for the bias introduced by regularization, aiming to improve both the model complexity and optimal risk.
Safety and Fairness for Content Moderation in Generative Models
Jun 09, 2023



With significant advances in generative AI, new technologies are rapidly being deployed with generative components. Generative models are typically trained on large datasets, resulting in model behaviors that can mimic the worst of the content in the training data. Responsible deployment of generative technologies requires content moderation strategies, such as safety input and output filters. Here, we provide a theoretical framework for conceptualizing responsible content moderation of text-to-image generative technologies, including a demonstration of how to empirically measure the constructs we enumerate. We define and distinguish the concepts of safety, fairness, and metric equity, and enumerate example harms that can come in each domain. We then provide a demonstration of how the defined harms can be quantified. We conclude with a summary of how the style of harms quantification we demonstrate enables data-driven content moderation decisions.
Salient Conditional Diffusion for Defending Against Backdoor Attacks
Jan 31, 2023
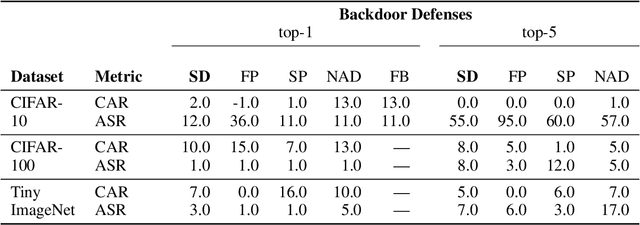
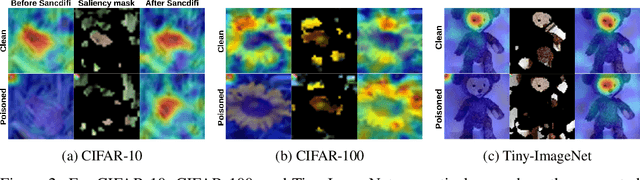
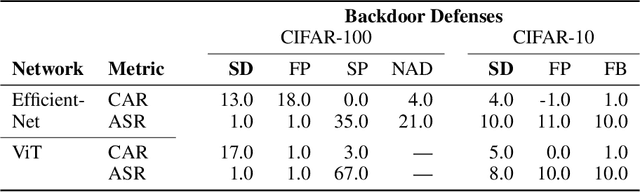
We propose a novel algorithm, Salient Conditional Diffusion (Sancdifi), a state-of-the-art defense against backdoor attacks. Sancdifi uses a denoising diffusion probabilistic model (DDPM) to degrade an image with noise and then recover said image using the learned reverse diffusion. Critically, we compute saliency map-based masks to condition our diffusion, allowing for stronger diffusion on the most salient pixels by the DDPM. As a result, Sancdifi is highly effective at diffusing out triggers in data poisoned by backdoor attacks. At the same time, it reliably recovers salient features when applied to clean data. This performance is achieved without requiring access to the model parameters of the Trojan network, meaning Sancdifi operates as a black-box defense.
Risk Bounds for Learning via Hilbert Coresets
Mar 29, 2021
We develop a formalism for constructing stochastic upper bounds on the expected full sample risk for supervised classification tasks via the Hilbert coresets approach within a transductive framework. We explicitly compute tight and meaningful bounds for complex datasets and complex hypothesis classes such as state-of-the-art deep neural network architectures. The bounds we develop exhibit nice properties: i) the bounds are non-uniform in the hypothesis space, ii) in many practical examples, the bounds become effectively deterministic by appropriate choice of prior and training data-dependent posterior distributions on the hypothesis space, and iii) the bounds become significantly better with increase in the size of the training set. We also lay out some ideas to explore for future research.