 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoding Agent Trajectories as Representations with Sequence Transformers
Oct 11, 2024Spatiotemporal data faces many analogous challenges to natural language text including the ordering of locations (words) in a sequence, long range dependencies between locations, and locations having multiple meanings. In this work, we propose a novel model for representing high dimensional spatiotemporal trajectories as sequences of discrete locations and encoding them with a Transformer-based neural network architecture. Similar to language models, our Sequence Transformer for Agent Representation Encodings (STARE) model can learn representations and structure in trajectory data through both supervisory tasks (e.g., classification), and self-supervisory tasks (e.g., masked modelling). We present experimental results on various synthetic and real trajectory datasets and show that our proposed model can learn meaningful encodings that are useful for many downstream tasks including discriminating between labels and indicating similarity between locations. Using these encodings, we also learn relationships between agents and locations present in spatiotemporal data.
Machine Learning Models for Improved Tracking from Range-Doppler Map Images
Jul 03, 2024Statistical tracking filters depend on accurate target measurements and uncertainty estimates for good tracking performance. In this work, we propose novel machine learning models for target detection and uncertainty estimation in range-Doppler map (RDM) images for Ground Moving Target Indicator (GMTI) radars. We show that by using the outputs of these models, we can significantly improve the performance of a multiple hypothesis tracker for complex multi-target air-to-ground tracking scenarios.
Sequential Maximum Margin Classifiers for Partially Labeled Data
Mar 07, 2018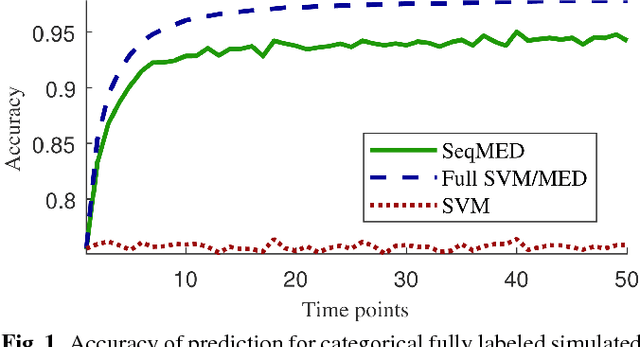
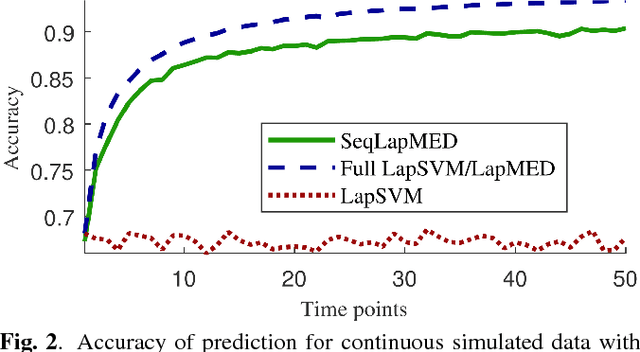
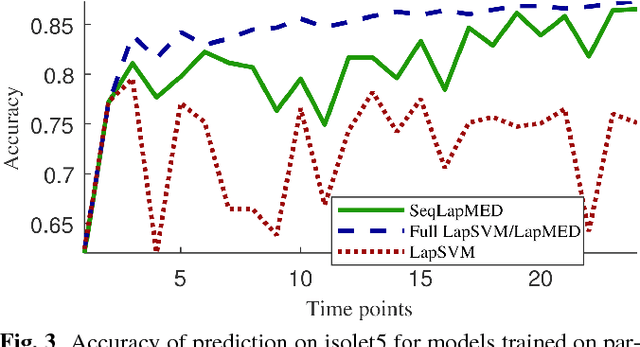
In many real-world applications, data is not collected as one batch, but sequentially over time, and often it is not possible or desirable to wait until the data is completely gathered before analyzing it. Thus, we propose a framework to sequentially update a maximum margin classifier by taking advantage of the Maximum Entropy Discrimination principle. Our maximum margin classifier allows for a kernel representation to represent large numbers of features and can also be regularized with respect to a smooth sub-manifold, allowing it to incorporate unlabeled observations. We compare the performance of our classifier to its non-sequential equivalents in both simulated and real datasets.
Latent Laplacian Maximum Entropy Discrimination for Detection of High-Utility Anomalies
Dec 14, 2017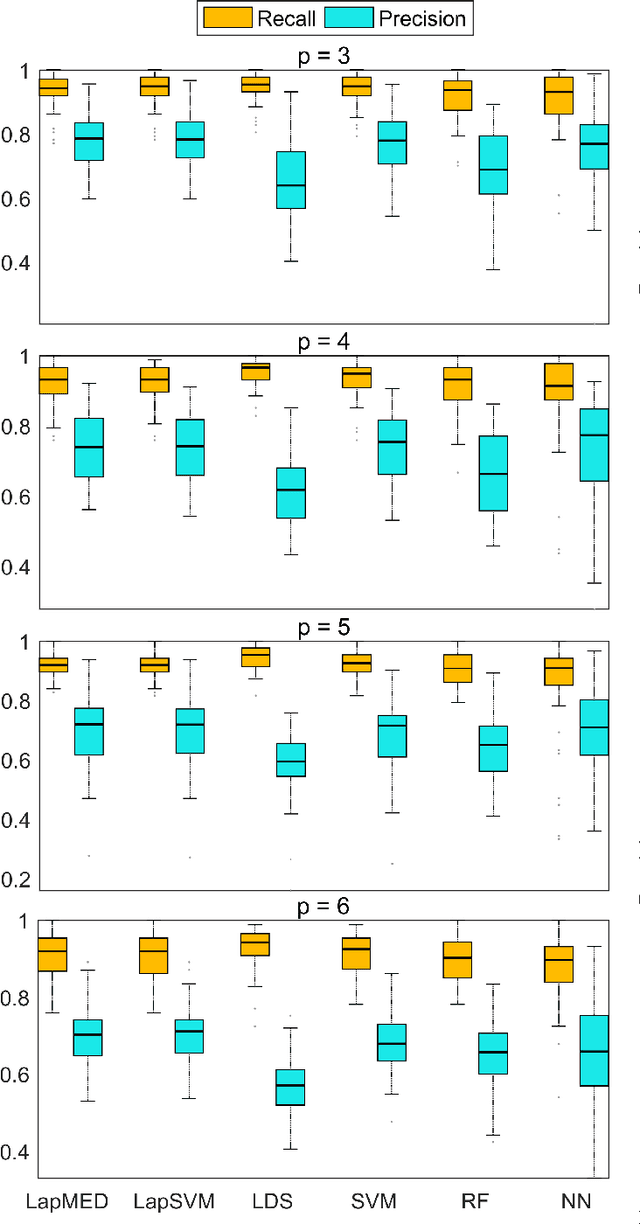
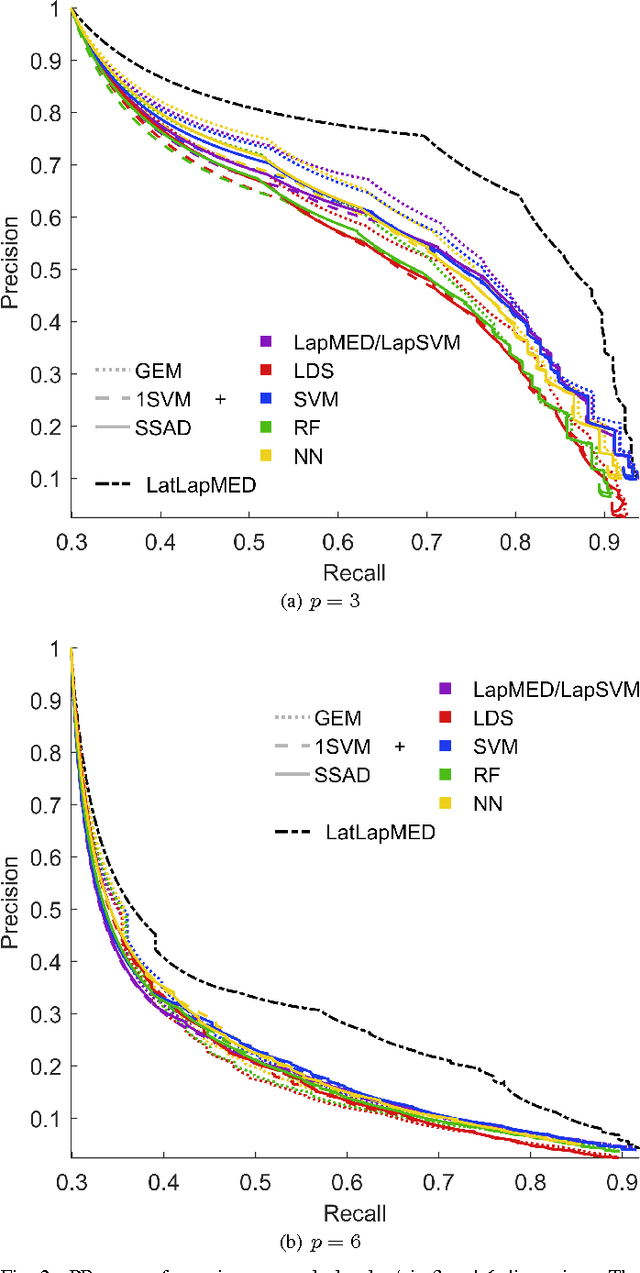
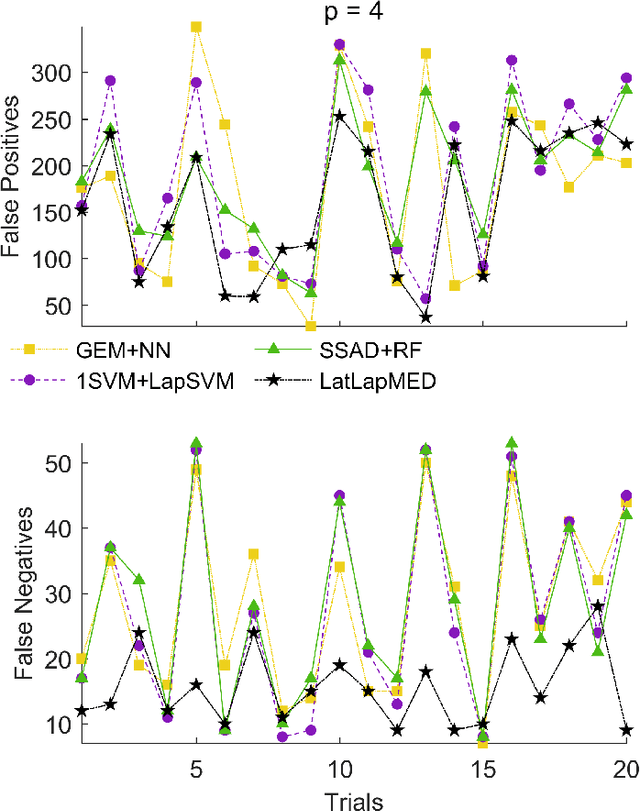
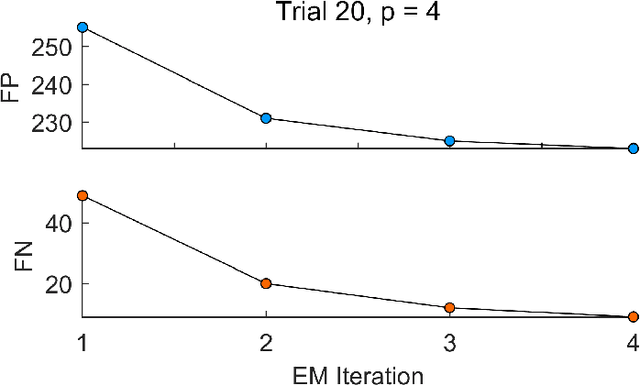
Data-driven anomaly detection methods suffer from the drawback of detecting all instances that are statistically rare, irrespective of whether the detected instances have real-world significance or not. In this paper, we are interested in the problem of specifically detecting anomalous instances that are known to have high real-world utility, while ignoring the low-utility statistically anomalous instances. To this end, we propose a novel method called Latent Laplacian Maximum Entropy Discrimination (LatLapMED) as a potential solution. This method uses the EM algorithm to simultaneously incorporate the Geometric Entropy Minimization principle for identifying statistical anomalies, and the Maximum Entropy Discrimination principle to incorporate utility labels, in order to detect high-utility anomalies. We apply our method in both simulated and real datasets to demonstrate that it has superior performance over existing alternatives that independently pre-process with unsupervised anomaly detection algorithms before classifying.
Efficient Distributed Estimation of Inverse Covariance Matrices
May 03, 2016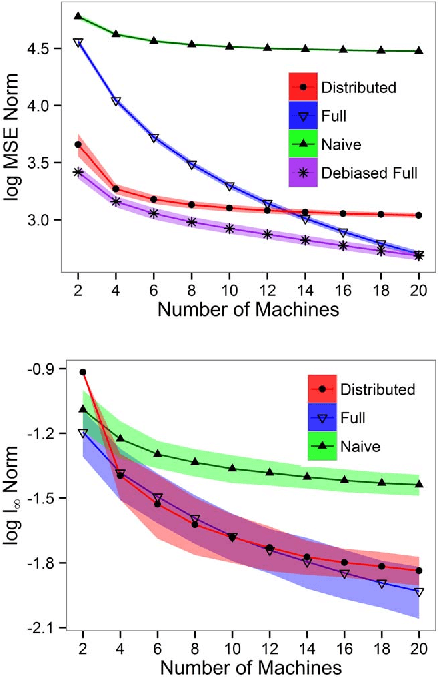

In distributed systems, communication is a major concern due to issues such as its vulnerability or efficiency. In this paper, we are interested in estimating sparse inverse covariance matrices when samples are distributed into different machines. We address communication efficiency by proposing a method where, in a single round of communication, each machine transfers a small subset of the entries of the inverse covariance matrix. We show that, with this efficient distributed method, the error rates can be comparable with estimation in a non-distributed setting, and correct model selection is still possible. Practical performance is shown through simulations.