 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Characterizing and Mitigating Imbalances in Multi-Instance Partial Label Learning
Jul 13, 2024Multi-Instance Partial Label Learning (MI-PLL) is a weakly-supervised learning setting encompassing partial label learning, latent structural learning, and neurosymbolic learning. Differently from supervised learning, in MI-PLL, the inputs to the classifiers at training-time are tuples of instances $\textbf{x}$, while the supervision signal is generated by a function $\sigma$ over the gold labels of $\textbf{x}$. The gold labels are hidden during training. In this paper, we focus on characterizing and mitigating learning imbalances, i.e., differences in the errors occurring when classifying instances of different classes (aka class-specific risks), under MI-PLL. The phenomenon of learning imbalances has been extensively studied in the context of long-tail learning; however, the nature of MI-PLL introduces new challenges. Our contributions are as follows. From a theoretical perspective, we characterize the learning imbalances by deriving class-specific risk bounds that depend upon the function $\sigma$. Our theory reveals that learning imbalances exist in MI-PLL even when the hidden labels are uniformly distributed. On the practical side, we introduce a technique for estimating the marginal of the hidden labels using only MI-PLL data. Then, we introduce algorithms that mitigate imbalances at training- and testing-time, by treating the marginal of the hidden labels as a constraint. The first algorithm relies on a novel linear programming formulation of MI-PLL for pseudo-labeling. The second one adjusts a model's scores based on robust optimal transport. We demonstrate the effectiveness of our techniques using strong neurosymbolic and long-tail learning baselines, discussing also open challenges.
On Regularization and Inference with Label Constraints
Jul 08, 2023

Prior knowledge and symbolic rules in machine learning are often expressed in the form of label constraints, especially in structured prediction problems. In this work, we compare two common strategies for encoding label constraints in a machine learning pipeline, regularization with constraints and constrained inference, by quantifying their impact on model performance. For regularization, we show that it narrows the generalization gap by precluding models that are inconsistent with the constraints. However, its preference for small violations introduces a bias toward a suboptimal model. For constrained inference, we show that it reduces the population risk by correcting a model's violation, and hence turns the violation into an advantage. Given these differences, we further explore the use of two approaches together and propose conditions for constrained inference to compensate for the bias introduced by regularization, aiming to improve both the model complexity and optimal risk.
On Learning Latent Models with Multi-Instance Weak Supervision
Jun 23, 2023


We consider a weakly supervised learning scenario where the supervision signal is generated by a transition function $\sigma$ of labels associated with multiple input instances. We formulate this problem as \emph{multi-instance Partial Label Learning (multi-instance PLL)}, which is an extension to the standard PLL problem. Our problem is met in different fields, including latent structural learning and neuro-symbolic integration. Despite the existence of many learning techniques, limited theoretical analysis has been dedicated to this problem. In this paper, we provide the first theoretical study of multi-instance PLL with possibly an unknown transition $\sigma$. Our main contributions are as follows. Firstly, we propose a necessary and sufficient condition for the learnability of the problem. This condition non-trivially generalizes and relaxes the existing small ambiguity degree in the PLL literature, since we allow the transition to be deterministic. Secondly, we derive Rademacher-style error bounds based on a top-$k$ surrogate loss that is widely used in the neuro-symbolic literature. Furthermore, we conclude with empirical experiments for learning under unknown transitions. The empirical results align with our theoretical findings; however, they also expose the issue of scalability in the weak supervision literature.
Learnability with Indirect Supervision Signals
Jun 15, 2020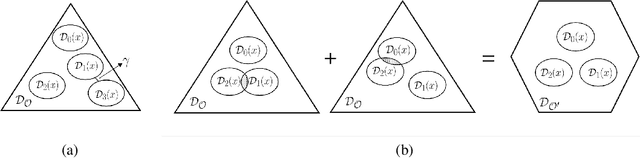
Learning from indirect supervision signals is important in real-world AI applications when, often, gold labels are missing or too costly. In this paper, we develop a unified theoretical framework for multi-class classification when the supervision is provided by a variable that contains nonzero mutual information with the gold label. The nature of this problem is determined by (i) the transition probability from the gold labels to the indirect supervision variables and (ii) the learner's prior knowledge about the transition. Our framework relaxes assumptions made in the literature, and supports learning with unknown, non-invertible and instance-dependent transitions. Our theory introduces a novel concept called \emph{separation}, which characterizes the learnability and generalization bounds. We also demonstrate the application of our framework via concrete novel results in a variety of learning scenarios such as learning with superset annotations and joint supervision signals.