 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumerical Instability and Chaos: Quantifying the Unpredictability of Large Language Models
Apr 14, 2026As Large Language Models (LLMs) are increasingly integrated into agentic workflows, their unpredictability stemming from numerical instability has emerged as a critical reliability issue. While recent studies have demonstrated the significant downstream effects of these instabilities, the root causes and underlying mechanisms remain poorly understood. In this paper, we present a rigorous analysis of how unpredictability is rooted in the finite numerical precision of floating-point representations, tracking how rounding errors propagate, amplify, or dissipate through Transformer computation layers. Specifically, we identify a chaotic "avalanche effect" in the early layers, where minor perturbations trigger binary outcomes: either rapid amplification or complete attenuation. Beyond specific error instances, we demonstrate that LLMs exhibit universal, scale-dependent chaotic behaviors characterized by three distinct regimes: 1) a stable regime, where perturbations fall below an input-dependent threshold and vanish, resulting in constant outputs; 2) a chaotic regime, where rounding errors dominate and drive output divergence; and 3) a signal-dominated regime, where true input variations override numerical noise. We validate these findings extensively across multiple datasets and model architectures.
Are Vision Transformer Representations Semantically Meaningful? A Case Study in Medical Imaging
Jul 02, 2025Vision transformers (ViTs) have rapidly gained prominence in medical imaging tasks such as disease classification, segmentation, and detection due to their superior accuracy compared to conventional deep learning models. However, due to their size and complex interactions via the self-attention mechanism, they are not well understood. In particular, it is unclear whether the representations produced by such models are semantically meaningful. In this paper, using a projected gradient-based algorithm, we show that their representations are not semantically meaningful and they are inherently vulnerable to small changes. Images with imperceptible differences can have very different representations; on the other hand, images that should belong to different semantic classes can have nearly identical representations. Such vulnerability can lead to unreliable classification results; for example, unnoticeable changes cause the classification accuracy to be reduced by over 60\%. %. To the best of our knowledge, this is the first work to systematically demonstrate this fundamental lack of semantic meaningfulness in ViT representations for medical image classification, revealing a critical challenge for their deployment in safety-critical systems.
Malicious Path Manipulations via Exploitation of Representation Vulnerabilities of Vision-Language Navigation Systems
Jul 10, 2024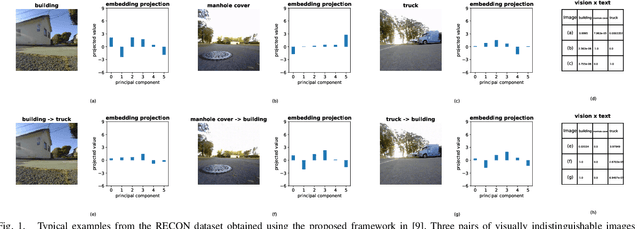

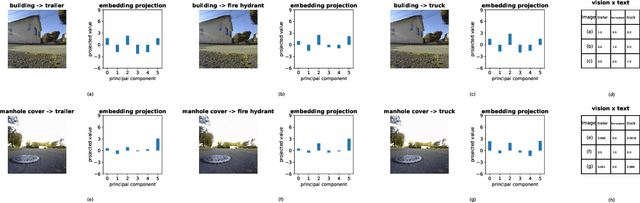
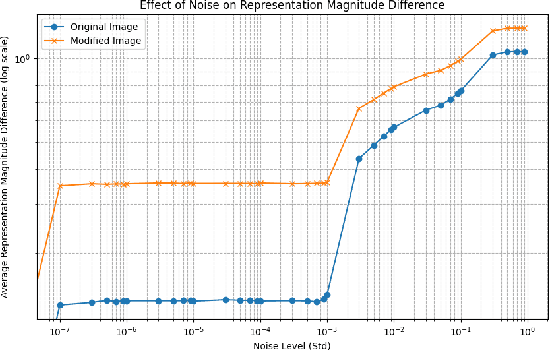
Building on the unprecedented capabilities of large language models for command understanding and zero-shot recognition of multi-modal vision-language transformers, visual language navigation (VLN) has emerged as an effective way to address multiple fundamental challenges toward a natural language interface to robot navigation. However, such vision-language models are inherently vulnerable due to the lack of semantic meaning of the underlying embedding space. Using a recently developed gradient based optimization procedure, we demonstrate that images can be modified imperceptibly to match the representation of totally different images and unrelated texts for a vision-language model. Building on this, we develop algorithms that can adversarially modify a minimal number of images so that the robot will follow a route of choice for commands that require a number of landmarks. We demonstrate that experimentally using a recently proposed VLN system; for a given navigation command, a robot can be made to follow drastically different routes. We also develop an efficient algorithm to detect such malicious modifications reliably based on the fact that the adversarially modified images have much higher sensitivity to added Gaussian noise than the original images.
Unaligning Everything: Or Aligning Any Text to Any Image in Multimodal Models
Jul 01, 2024Utilizing a shared embedding space, emerging multimodal models exhibit unprecedented zero-shot capabilities. However, the shared embedding space could lead to new vulnerabilities if different modalities can be misaligned. In this paper, we extend and utilize a recently developed effective gradient-based procedure that allows us to match the embedding of a given text by minimally modifying an image. Using the procedure, we show that we can align the embeddings of distinguishable texts to any image through unnoticeable adversarial attacks in joint image-text models, revealing that semantically unrelated images can have embeddings of identical texts and at the same time visually indistinguishable images can be matched to the embeddings of very different texts. Our technique achieves 100\% success rate when it is applied to text datasets and images from multiple sources. Without overcoming the vulnerability, multimodal models cannot robustly align inputs from different modalities in a semantically meaningful way. \textbf{Warning: the text data used in this paper are toxic in nature and may be offensive to some readers.}
Intriguing Differences Between Zero-Shot and Systematic Evaluations of Vision-Language Transformer Models
Feb 13, 2024



Transformer-based models have dominated natural language processing and other areas in the last few years due to their superior (zero-shot) performance on benchmark datasets. However, these models are poorly understood due to their complexity and size. While probing-based methods are widely used to understand specific properties, the structures of the representation space are not systematically characterized; consequently, it is unclear how such models generalize and overgeneralize to new inputs beyond datasets. In this paper, based on a new gradient descent optimization method, we are able to explore the embedding space of a commonly used vision-language model. Using the Imagenette dataset, we show that while the model achieves over 99\% zero-shot classification performance, it fails systematic evaluations completely. Using a linear approximation, we provide a framework to explain the striking differences. We have also obtained similar results using a different model to support that our results are applicable to other transformer models with continuous inputs. We also propose a robust way to detect the modified images.
Intriguing Equivalence Structures of the Embedding Space of Vision Transformers
Jan 28, 2024Pre-trained large foundation models play a central role in the recent surge of artificial intelligence, resulting in fine-tuned models with remarkable abilities when measured on benchmark datasets, standard exams, and applications. Due to their inherent complexity, these models are not well understood. While small adversarial inputs to such models are well known, the structures of the representation space are not well characterized despite their fundamental importance. In this paper, using the vision transformers as an example due to the continuous nature of their input space, we show via analyses and systematic experiments that the representation space consists of large piecewise linear subspaces where there exist very different inputs sharing the same representations, and at the same time, local normal spaces where there are visually indistinguishable inputs having very different representations. The empirical results are further verified using the local directional estimations of the Lipschitz constants of the underlying models. Consequently, the resulting representations change the results of downstream models, and such models are subject to overgeneralization and with limited semantically meaningful generalization capability.
Improved Stock Price Movement Classification Using News Articles Based on Embeddings and Label Smoothing
Jan 25, 2023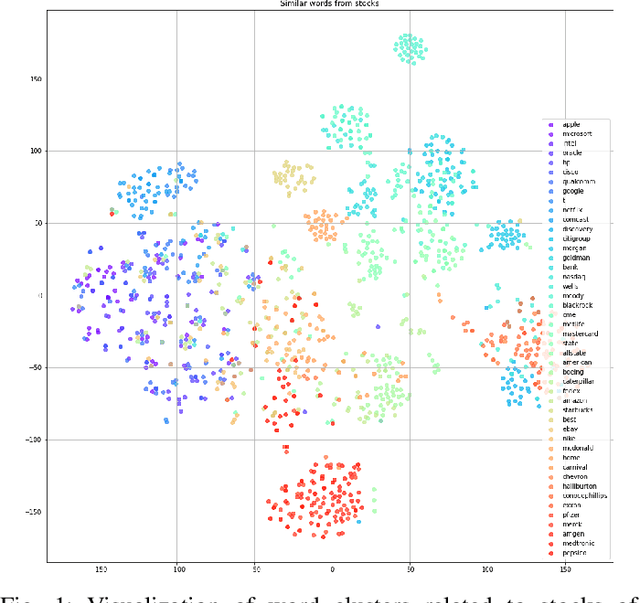


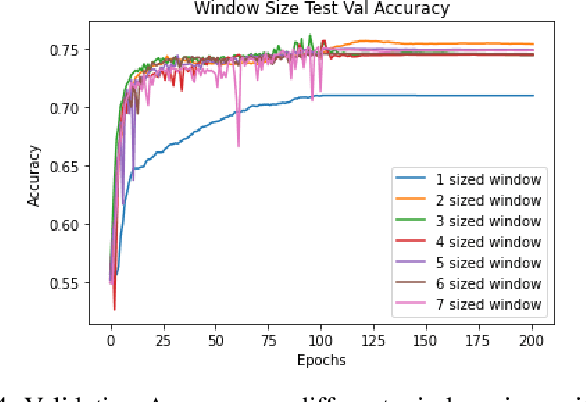
Stock price movement prediction is a challenging and essential problem in finance. While it is well established in modern behavioral finance that the share prices of related stocks often move after the release of news via reactions and overreactions of investors, how to capture the relationships between price movements and news articles via quantitative models is an active area research; existing models have achieved success with variable degrees. In this paper, we propose to improve stock price movement classification using news articles by incorporating regularization and optimization techniques from deep learning. More specifically, we capture the dependencies between news articles and stocks through embeddings and bidirectional recurrent neural networks as in recent models. We further incorporate weight decay, batch normalization, dropout, and label smoothing to improve the generalization of the trained models. To handle high fluctuations of validation accuracy of batch normalization, we propose dual-phase training to realize the improvements reliably. Our experimental results on a commonly used dataset show significant improvements, achieving average accuracy of 80.7% on the test set, which is more than 10.0% absolute improvement over existing models. Our ablation studies show batch normalization and label smoothing are most effective, leading to 6.0% and 3.4% absolute improvement, respectively on average.
Towards Quantifying Intrinsic Generalization of Deep ReLU Networks
Oct 18, 2019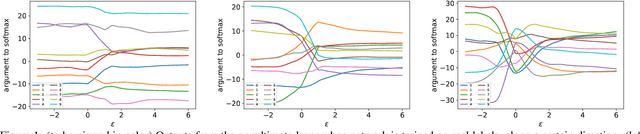
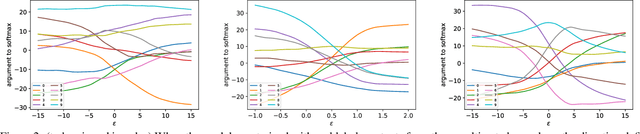
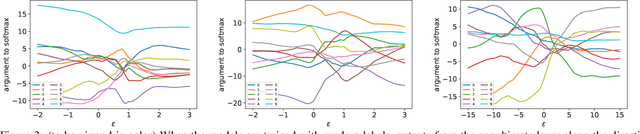
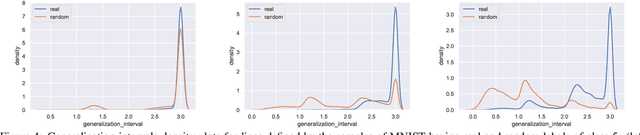
Understanding the underlying mechanisms that enable the empirical successes of deep neural networks is essential for further improving their performance and explaining such networks. Towards this goal, a specific question is how to explain the "surprising" behavior of the same over-parametrized deep neural networks that can generalize well on real datasets and at the same time "memorize" training samples when the labels are randomized. In this paper, we demonstrate that deep ReLU networks generalize from training samples to new points via piece-wise linear interpolation. We provide a quantified analysis on the generalization ability of a deep ReLU network: Given a fixed point $\mathbf{x}$ and a fixed direction in the input space $\mathcal{S}$, there is always a segment such that any point on the segment will be classified the same as the fixed point $\mathbf{x}$. We call this segment the $generalization \ interval$. We show that the generalization intervals of a ReLU network behave similarly along pairwise directions between samples of the same label in both real and random cases on the MNIST and CIFAR-10 datasets. This result suggests that the same interpolation mechanism is used in both cases. Additionally, for datasets using real labels, such networks provide a good approximation of the underlying manifold in the data, where the changes are much smaller along tangent directions than along normal directions. On the other hand, however, for datasets with random labels, generalization intervals along mid-lines of triangles with the same label are much smaller than those on the datasets with real labels, suggesting different behaviors along other directions. Our systematic experiments demonstrate for the first time that such deep neural networks generalize through the same interpolation and explain the differences between their performance on datasets with real and random labels.
Interpretable Deep Neural Networks for Patient Mortality Prediction: A Consensus-based Approach
May 14, 2019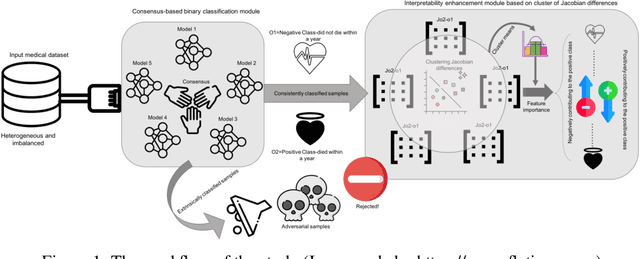


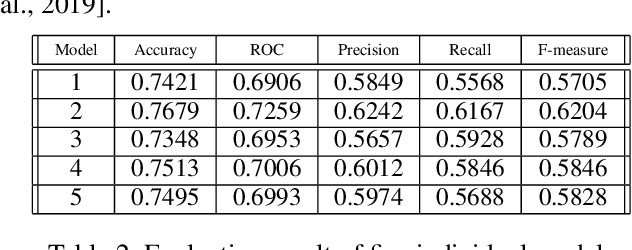
Deep neural networks have achieved remarkable success in challenging tasks. However, the black-box approach of training and testing of such networks is not acceptable to critical applications. In particular, the existence of adversarial examples and their overgeneralization to irrelevant inputs makes it difficult, if not impossible, to explain decisions by commonly used neural networks. In this paper, we analyze the underlying mechanism of generalization of deep neural networks and propose an ($n$, $k$) consensus algorithm to be insensitive to adversarial examples and at the same time be able to reject irrelevant samples. Furthermore, the consensus algorithm is able to improve classification accuracy by using multiple trained deep neural networks. To handle the complexity of deep neural networks, we cluster linear approximations and use cluster means to capture feature importance. Due to weight symmetry, a small number of clusters are sufficient to produce a robust interpretation. Experimental results on a health dataset show the effectiveness of our algorithm in enhancing the prediction accuracy and interpretability of deep neural network models on one-year patient mortality prediction.
Overfitting Mechanism and Avoidance in Deep Neural Networks
Jan 19, 2019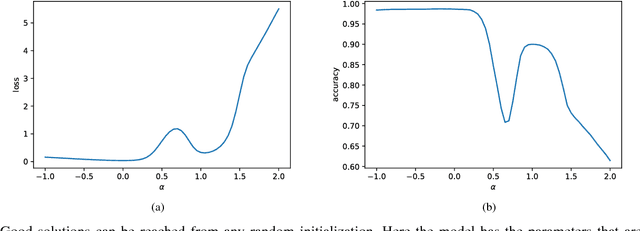
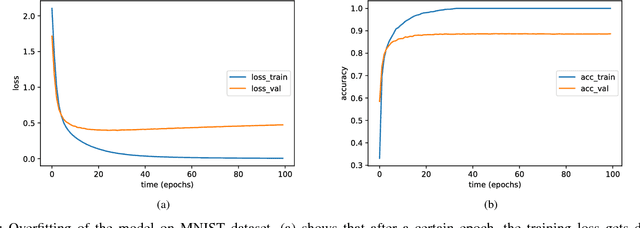
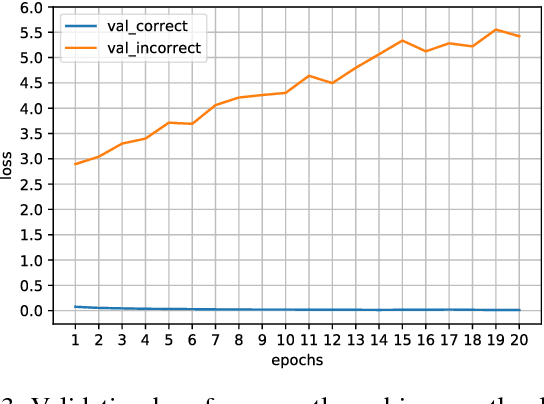
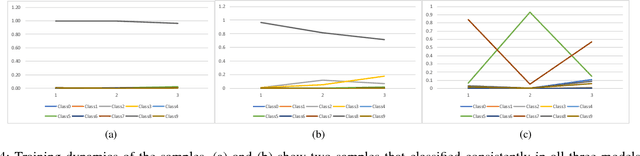
Assisted by the availability of data and high performance computing, deep learning techniques have achieved breakthroughs and surpassed human performance empirically in difficult tasks, including object recognition, speech recognition, and natural language processing. As they are being used in critical applications, understanding underlying mechanisms for their successes and limitations is imperative. In this paper, we show that overfitting, one of the fundamental issues in deep neural networks, is due to continuous gradient updating and scale sensitiveness of cross entropy loss. By separating samples into correctly and incorrectly classified ones, we show that they behave very differently, where the loss decreases in the correct ones and increases in the incorrect ones. Furthermore, by analyzing dynamics during training, we propose a consensus-based classification algorithm that enables us to avoid overfitting and significantly improve the classification accuracy especially when the number of training samples is limited. As each trained neural network depends on extrinsic factors such as initial values as well as training data, requiring consensus among multiple models reduces extrinsic factors substantially; for statistically independent models, the reduction is exponential. Compared to ensemble algorithms, the proposed algorithm avoids overgeneralization by not classifying ambiguous inputs. Systematic experimental results demonstrate the effectiveness of the proposed algorithm. For example, using only 1000 training samples from MNIST dataset, the proposed algorithm achieves 95% accuracy, significantly higher than any of the individual models, with 90% of the test samples classified.