 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Deep Neural Networks for Patient Mortality Prediction: A Consensus-based Approach
May 14, 2019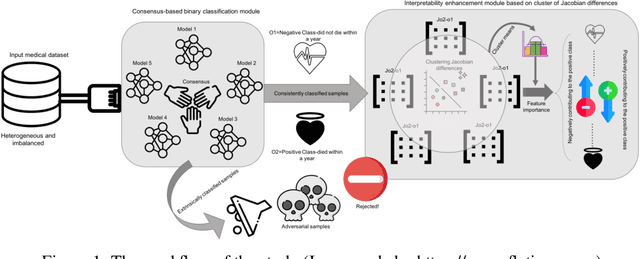


Deep neural networks have achieved remarkable success in challenging tasks. However, the black-box approach of training and testing of such networks is not acceptable to critical applications. In particular, the existence of adversarial examples and their overgeneralization to irrelevant inputs makes it difficult, if not impossible, to explain decisions by commonly used neural networks. In this paper, we analyze the underlying mechanism of generalization of deep neural networks and propose an ($n$, $k$) consensus algorithm to be insensitive to adversarial examples and at the same time be able to reject irrelevant samples. Furthermore, the consensus algorithm is able to improve classification accuracy by using multiple trained deep neural networks. To handle the complexity of deep neural networks, we cluster linear approximations and use cluster means to capture feature importance. Due to weight symmetry, a small number of clusters are sufficient to produce a robust interpretation. Experimental results on a health dataset show the effectiveness of our algorithm in enhancing the prediction accuracy and interpretability of deep neural network models on one-year patient mortality prediction.
Enhancing Prediction Models for One-Year Mortality in Patients with Acute Myocardial Infarction and Post Myocardial Infarction Syndrome
Apr 28, 2019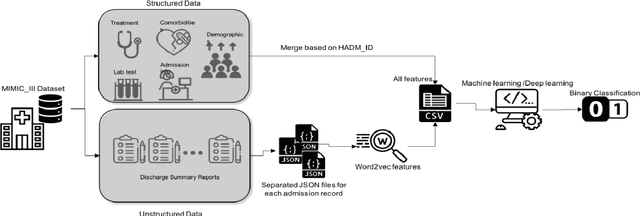

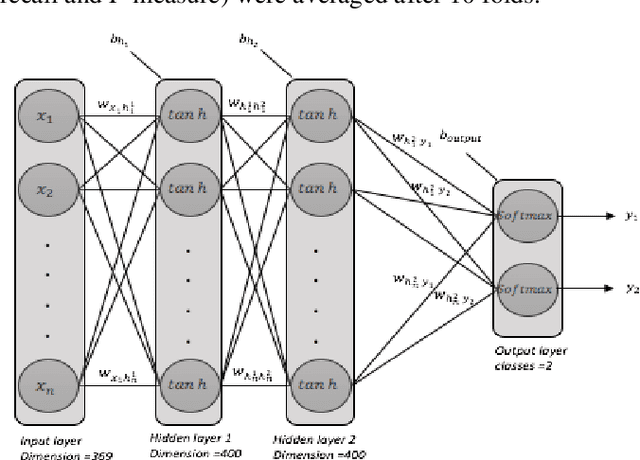
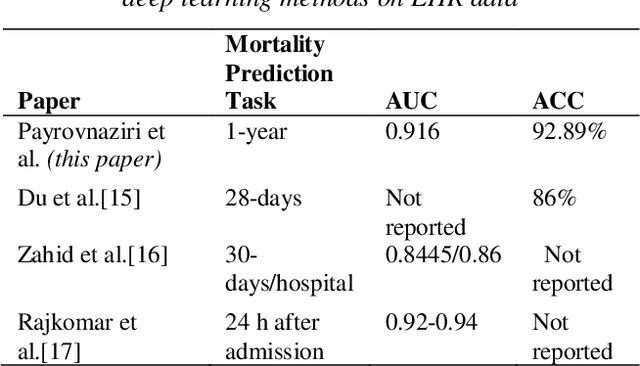
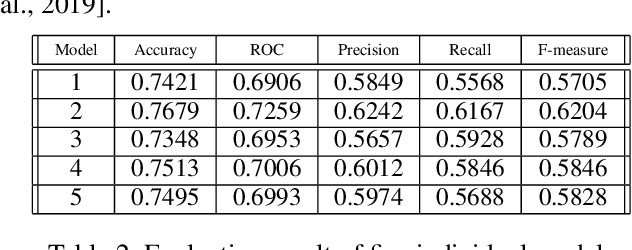
Predicting the risk of mortality for patients with acute myocardial infarction (AMI) using electronic health records (EHRs) data can help identify risky patients who might need more tailored care. In our previous work, we built computational models to predict one-year mortality of patients admitted to an intensive care unit (ICU) with AMI or post myocardial infarction syndrome. Our prior work only used the structured clinical data from MIMIC-III, a publicly available ICU clinical database. In this study, we enhanced our work by adding the word embedding features from free-text discharge summaries. Using a richer set of features resulted in significant improvement in the performance of our deep learning models. The average accuracy of our deep learning models was 92.89% and the average F-measure was 0.928. We further reported the impact of different combinations of features extracted from structured and/or unstructured data on the performance of the deep learning models.
Building Computational Models to Predict One-Year Mortality in ICU Patients with Acute Myocardial Infarction and Post Myocardial Infarction Syndrome
Dec 12, 2018
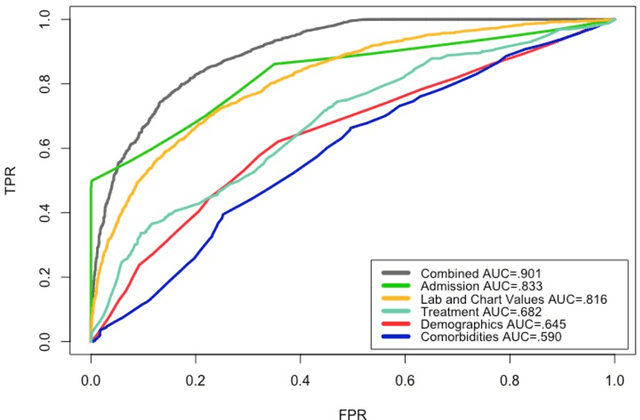
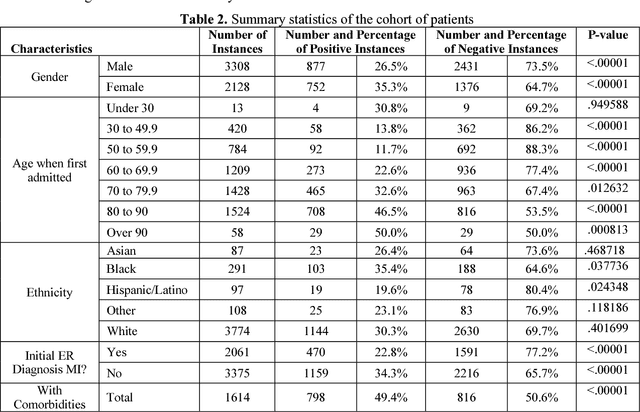
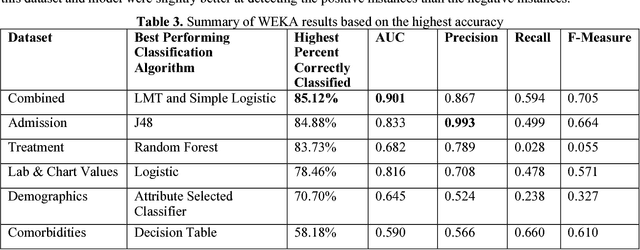
Heart disease remains the leading cause of death in the United States. Compared with risk assessment guidelines that require manual calculation of scores, machine learning-based prediction for disease outcomes such as mortality can be utilized to save time and improve prediction accuracy. This study built and evaluated various machine learning models to predict one-year mortality in patients diagnosed with acute myocardial infarction or post myocardial infarction syndrome in the MIMIC-III database. The results of the best performing shallow prediction models were compared to a deep feedforward neural network (Deep FNN) with back propagation. We included a cohort of 5436 admissions. Six datasets were developed and compared. The models applying Logistic Model Trees (LMT) and Simple Logistic algorithms to the combined dataset resulted in the highest prediction accuracy at 85.12% and the highest AUC at .901. In addition, other factors were observed to have an impact on outcomes as well.