 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$PA^3$: $\textbf{P}$olicy-$\textbf{A}$ware $\textbf{A}$gent $\textbf{A}$lignment through Chain-of-Thought
Mar 15, 2026Conversational assistants powered by large language models (LLMs) excel at tool-use tasks but struggle with adhering to complex, business-specific rules. While models can reason over business rules provided in context, including all policies for every query introduces high latency and wastes compute. Furthermore, these lengthy prompts lead to long contexts, harming overall performance due to the "needle-in-the-haystack" problem. To address these challenges, we propose a multi-stage alignment method that teaches models to recall and apply relevant business policies during chain-of-thought reasoning at inference time, without including the full business policy in-context. Furthermore, we introduce a novel PolicyRecall reward based on the Jaccard score and a Hallucination Penalty for GRPO training. Altogether, our best model outperforms the baseline by 16 points and surpasses comparable in-context baselines of similar model size by 3 points, while using 40% fewer words.
An Analysis on the Learning Rules of the Skip-Gram Model
Mar 18, 2020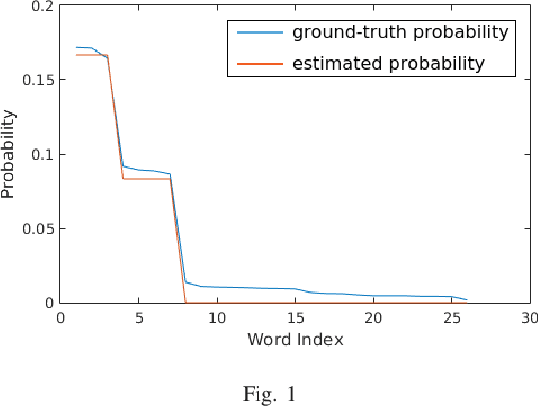
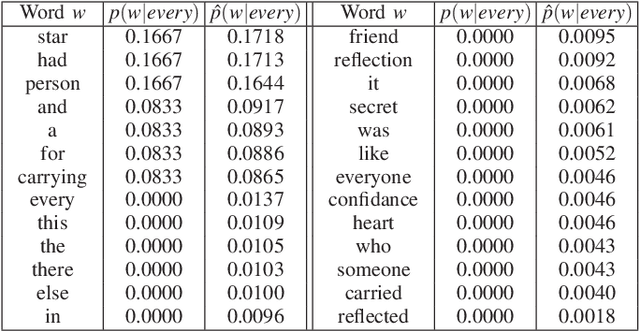
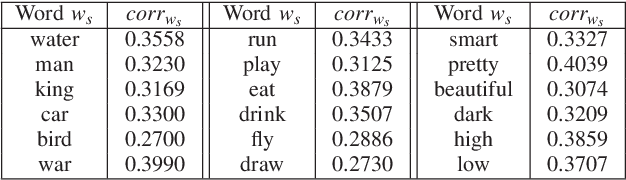
To improve the generalization of the representations for natural language processing tasks, words are commonly represented using vectors, where distances among the vectors are related to the similarity of the words. While word2vec, the state-of-the-art implementation of the skip-gram model, is widely used and improves the performance of many natural language processing tasks, its mechanism is not yet well understood. In this work, we derive the learning rules for the skip-gram model and establish their close relationship to competitive learning. In addition, we provide the global optimal solution constraints for the skip-gram model and validate them by experimental results.
* Published on the 2019 International Joint Conference on Neural Networks
Enhancing Prediction Models for One-Year Mortality in Patients with Acute Myocardial Infarction and Post Myocardial Infarction Syndrome
Apr 28, 2019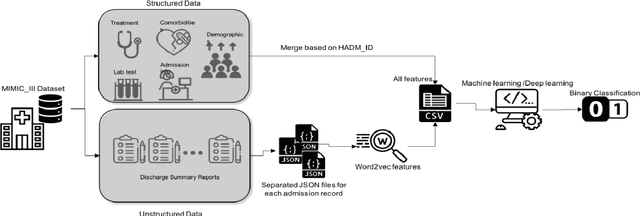

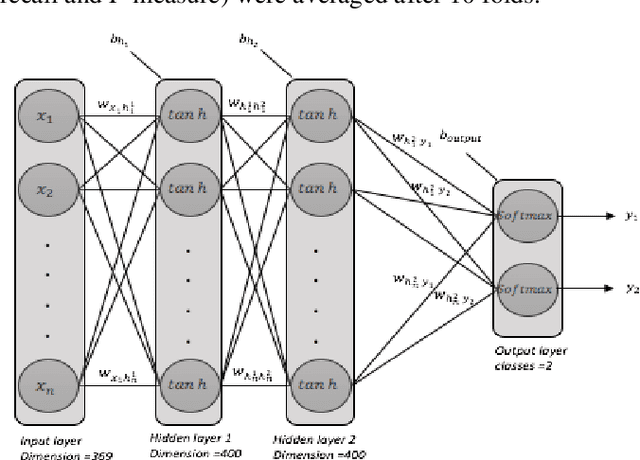
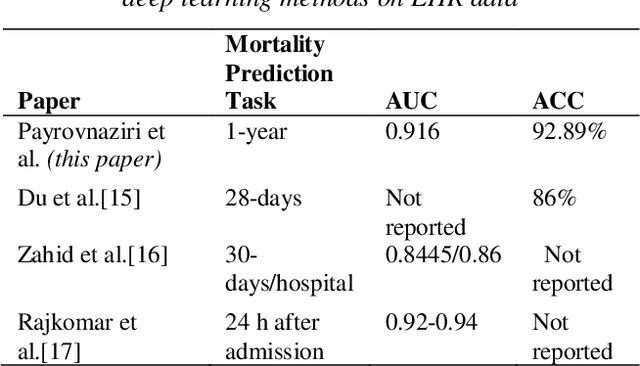
Predicting the risk of mortality for patients with acute myocardial infarction (AMI) using electronic health records (EHRs) data can help identify risky patients who might need more tailored care. In our previous work, we built computational models to predict one-year mortality of patients admitted to an intensive care unit (ICU) with AMI or post myocardial infarction syndrome. Our prior work only used the structured clinical data from MIMIC-III, a publicly available ICU clinical database. In this study, we enhanced our work by adding the word embedding features from free-text discharge summaries. Using a richer set of features resulted in significant improvement in the performance of our deep learning models. The average accuracy of our deep learning models was 92.89% and the average F-measure was 0.928. We further reported the impact of different combinations of features extracted from structured and/or unstructured data on the performance of the deep learning models.