Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analysis on the Learning Rules of the Skip-Gram Model
Paper and Code
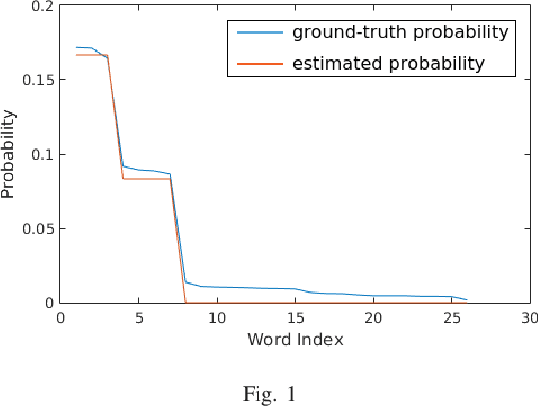
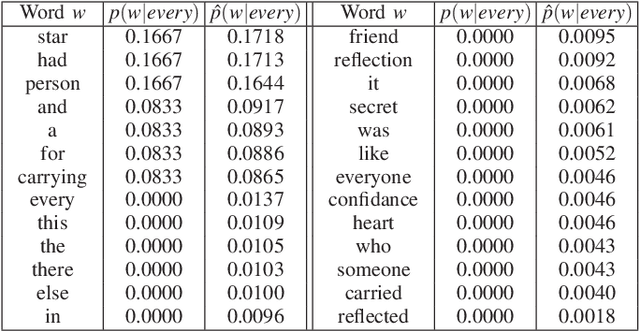
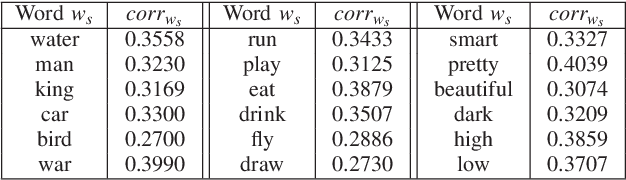
To improve the generalization of the representations for natural language processing tasks, words are commonly represented using vectors, where distances among the vectors are related to the similarity of the words. While word2vec, the state-of-the-art implementation of the skip-gram model, is widely used and improves the performance of many natural language processing tasks, its mechanism is not yet well understood. In this work, we derive the learning rules for the skip-gram model and establish their close relationship to competitive learning. In addition, we provide the global optimal solution constraints for the skip-gram model and validate them by experimental results.
* The 2019 International Joint Conference on Neural Networks (IJCNN) * Published on the 2019 International Joint Conference on Neural
Networks
View paper on