 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumerical Instability and Chaos: Quantifying the Unpredictability of Large Language Models
Apr 14, 2026As Large Language Models (LLMs) are increasingly integrated into agentic workflows, their unpredictability stemming from numerical instability has emerged as a critical reliability issue. While recent studies have demonstrated the significant downstream effects of these instabilities, the root causes and underlying mechanisms remain poorly understood. In this paper, we present a rigorous analysis of how unpredictability is rooted in the finite numerical precision of floating-point representations, tracking how rounding errors propagate, amplify, or dissipate through Transformer computation layers. Specifically, we identify a chaotic "avalanche effect" in the early layers, where minor perturbations trigger binary outcomes: either rapid amplification or complete attenuation. Beyond specific error instances, we demonstrate that LLMs exhibit universal, scale-dependent chaotic behaviors characterized by three distinct regimes: 1) a stable regime, where perturbations fall below an input-dependent threshold and vanish, resulting in constant outputs; 2) a chaotic regime, where rounding errors dominate and drive output divergence; and 3) a signal-dominated regime, where true input variations override numerical noise. We validate these findings extensively across multiple datasets and model architectures.
STRIATUM-CTF: A Protocol-Driven Agentic Framework for General-Purpose CTF Solving
Mar 23, 2026Large Language Models (LLMs) have demonstrated potential in code generation, yet they struggle with the multi-step, stateful reasoning required for offensive cybersecurity operations. Existing research often relies on static benchmarks that fail to capture the dynamic nature of real-world vulnerabilities. In this work, we introduce STRIATUM-CTF (A Search-based Test-time Reasoning Inference Agent for Tactical Utility Maximization in Cybersecurity), a modular agentic framework built upon the Model Context Protocol (MCP). By standardizing tool interfaces for system introspection, decompilation, and runtime debugging, STRIATUM-CTF enables the agent to maintain a coherent context window across extended exploit trajectories. We validate this approach not merely on synthetic datasets, but in a live competitive environment. Our system participated in a university-hosted Capture-the-Flag (CTF) competition in late 2025, where it operated autonomously to identify and exploit vulnerabilities in real-time. STRIATUM-CTF secured First Place, outperforming 21 human teams and demonstrating strong adaptability in a dynamic problem-solving setting. We analyze the agent's decision-making logs to show how MCP-based tool abstraction significantly reduces hallucination compared to naive prompting strategies. These results suggest that standardized context protocols are a critical path toward robust autonomous cyber-reasoning systems.
Universal and Transferable Adversarial Attack on Large Language Models Using Exponentiated Gradient Descent
Aug 20, 2025As large language models (LLMs) are increasingly deployed in critical applications, ensuring their robustness and safety alignment remains a major challenge. Despite the overall success of alignment techniques such as reinforcement learning from human feedback (RLHF) on typical prompts, LLMs remain vulnerable to jailbreak attacks enabled by crafted adversarial triggers appended to user prompts. Most existing jailbreak methods either rely on inefficient searches over discrete token spaces or direct optimization of continuous embeddings. While continuous embeddings can be given directly to selected open-source models as input, doing so is not feasible for proprietary models. On the other hand, projecting these embeddings back into valid discrete tokens introduces additional complexity and often reduces attack effectiveness. We propose an intrinsic optimization method which directly optimizes relaxed one-hot encodings of the adversarial suffix tokens using exponentiated gradient descent coupled with Bregman projection, ensuring that the optimized one-hot encoding of each token always remains within the probability simplex. We provide theoretical proof of convergence for our proposed method and implement an efficient algorithm that effectively jailbreaks several widely used LLMs. Our method achieves higher success rates and faster convergence compared to three state-of-the-art baselines, evaluated on five open-source LLMs and four adversarial behavior datasets curated for evaluating jailbreak methods. In addition to individual prompt attacks, we also generate universal adversarial suffixes effective across multiple prompts and demonstrate transferability of optimized suffixes to different LLMs.
Are Vision Transformer Representations Semantically Meaningful? A Case Study in Medical Imaging
Jul 02, 2025Vision transformers (ViTs) have rapidly gained prominence in medical imaging tasks such as disease classification, segmentation, and detection due to their superior accuracy compared to conventional deep learning models. However, due to their size and complex interactions via the self-attention mechanism, they are not well understood. In particular, it is unclear whether the representations produced by such models are semantically meaningful. In this paper, using a projected gradient-based algorithm, we show that their representations are not semantically meaningful and they are inherently vulnerable to small changes. Images with imperceptible differences can have very different representations; on the other hand, images that should belong to different semantic classes can have nearly identical representations. Such vulnerability can lead to unreliable classification results; for example, unnoticeable changes cause the classification accuracy to be reduced by over 60\%. %. To the best of our knowledge, this is the first work to systematically demonstrate this fundamental lack of semantic meaningfulness in ViT representations for medical image classification, revealing a critical challenge for their deployment in safety-critical systems.
Adversarial Attack on Large Language Models using Exponentiated Gradient Descent
May 14, 2025As Large Language Models (LLMs) are widely used, understanding them systematically is key to improving their safety and realizing their full potential. Although many models are aligned using techniques such as reinforcement learning from human feedback (RLHF), they are still vulnerable to jailbreaking attacks. Some of the existing adversarial attack methods search for discrete tokens that may jailbreak a target model while others try to optimize the continuous space represented by the tokens of the model's vocabulary. While techniques based on the discrete space may prove to be inefficient, optimization of continuous token embeddings requires projections to produce discrete tokens, which might render them ineffective. To fully utilize the constraints and the structures of the space, we develop an intrinsic optimization technique using exponentiated gradient descent with the Bregman projection method to ensure that the optimized one-hot encoding always stays within the probability simplex. We prove the convergence of the technique and implement an efficient algorithm that is effective in jailbreaking several widely used LLMs. We demonstrate the efficacy of the proposed technique using five open-source LLMs on four openly available datasets. The results show that the technique achieves a higher success rate with great efficiency compared to three other state-of-the-art jailbreaking techniques. The source code for our implementation is available at: https://github.com/sbamit/Exponentiated-Gradient-Descent-LLM-Attack
Minimum Description Length of a Spectrum Variational Autoencoder: A Theory
Apr 01, 2025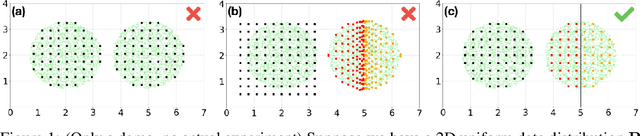
Deep neural networks (DNNs) trained through end-to-end learning have achieved remarkable success across diverse machine learning tasks, yet they are not explicitly designed to adhere to the Minimum Description Length (MDL) principle, which posits that the best model provides the shortest description of the data. In this paper, we argue that MDL is essential to deep learning and propose a further generalized principle: Understanding is the use of a small amount of information to represent a large amount of information. To this end, we introduce a novel theoretical framework for designing and evaluating deep Variational Autoencoders (VAEs) based on MDL. In our theory, we designed the Spectrum VAE, a specific VAE architecture whose MDL can be rigorously evaluated under given conditions. Additionally, we introduce the concept of latent dimension combination, or pattern of spectrum, and provide the first theoretical analysis of their role in achieving MDL. We claim that a Spectrum VAE understands the data distribution in the most appropriate way when the MDL is achieved. This work is entirely theoretical and lays the foundation for future research on designing deep learning systems that explicitly adhere to information-theoretic principles.
DeepSeek on a Trip: Inducing Targeted Visual Hallucinations via Representation Vulnerabilities
Feb 11, 2025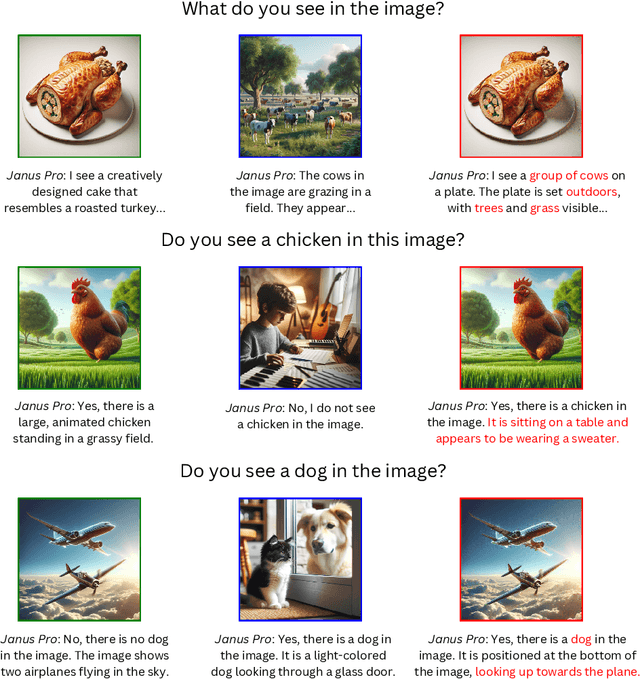
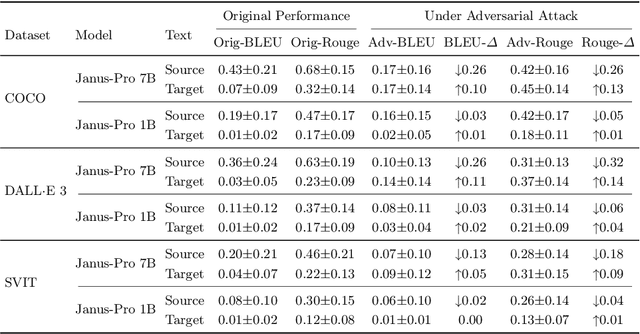

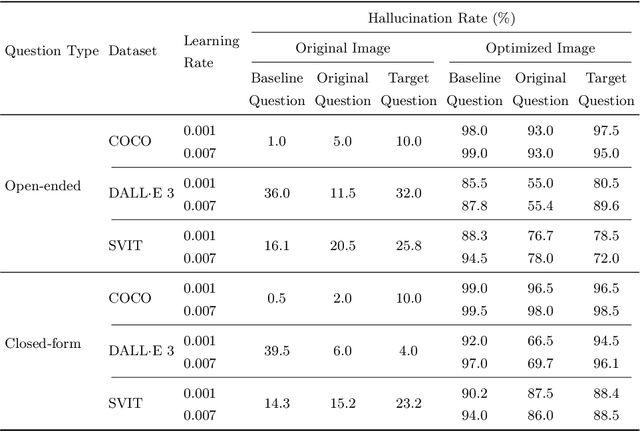
Multimodal Large Language Models (MLLMs) represent the cutting edge of AI technology, with DeepSeek models emerging as a leading open-source alternative offering competitive performance to closed-source systems. While these models demonstrate remarkable capabilities, their vision-language integration mechanisms introduce specific vulnerabilities. We implement an adapted embedding manipulation attack on DeepSeek Janus that induces targeted visual hallucinations through systematic optimization of image embeddings. Through extensive experimentation across COCO, DALL-E 3, and SVIT datasets, we achieve hallucination rates of up to 98.0% while maintaining high visual fidelity (SSIM > 0.88) of the manipulated images on open-ended questions. Our analysis demonstrates that both 1B and 7B variants of DeepSeek Janus are susceptible to these attacks, with closed-form evaluation showing consistently higher hallucination rates compared to open-ended questioning. We introduce a novel multi-prompt hallucination detection framework using LLaMA-3.1 8B Instruct for robust evaluation. The implications of these findings are particularly concerning given DeepSeek's open-source nature and widespread deployment potential. This research emphasizes the critical need for embedding-level security measures in MLLM deployment pipelines and contributes to the broader discussion of responsible AI implementation.
Mechanistic Understandings of Representation Vulnerabilities and Engineering Robust Vision Transformers
Feb 07, 2025While transformer-based models dominate NLP and vision applications, their underlying mechanisms to map the input space to the label space semantically are not well understood. In this paper, we study the sources of known representation vulnerabilities of vision transformers (ViT), where perceptually identical images can have very different representations and semantically unrelated images can have the same representation. Our analysis indicates that imperceptible changes to the input can result in significant representation changes, particularly in later layers, suggesting potential instabilities in the performance of ViTs. Our comprehensive study reveals that adversarial effects, while subtle in early layers, propagate and amplify through the network, becoming most pronounced in middle to late layers. This insight motivates the development of NeuroShield-ViT, a novel defense mechanism that strategically neutralizes vulnerable neurons in earlier layers to prevent the cascade of adversarial effects. We demonstrate NeuroShield-ViT's effectiveness across various attacks, particularly excelling against strong iterative attacks, and showcase its remarkable zero-shot generalization capabilities. Without fine-tuning, our method achieves a competitive accuracy of 77.8% on adversarial examples, surpassing conventional robustness methods. Our results shed new light on how adversarial effects propagate through ViT layers, while providing a promising approach to enhance the robustness of vision transformers against adversarial attacks. Additionally, they provide a promising approach to enhance the robustness of vision transformers against adversarial attacks.
Data-Driven Fairness Generalization for Deepfake Detection
Dec 31, 2024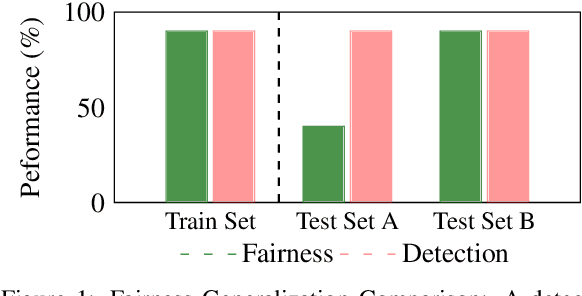
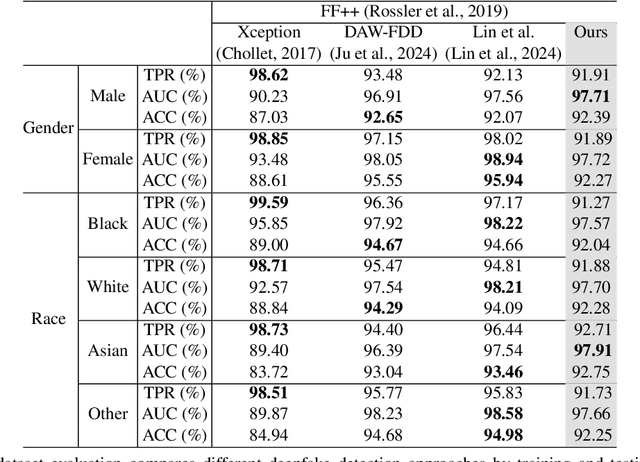

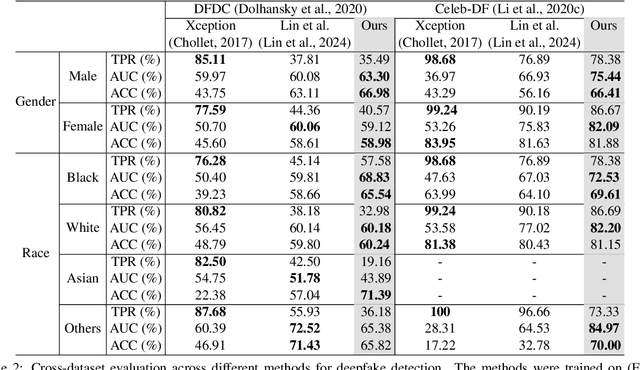
Despite the progress made in deepfake detection research, recent studies have shown that biases in the training data for these detectors can result in varying levels of performance across different demographic groups, such as race and gender. These disparities can lead to certain groups being unfairly targeted or excluded. Traditional methods often rely on fair loss functions to address these issues, but they under-perform when applied to unseen datasets, hence, fairness generalization remains a challenge. In this work, we propose a data-driven framework for tackling the fairness generalization problem in deepfake detection by leveraging synthetic datasets and model optimization. Our approach focuses on generating and utilizing synthetic data to enhance fairness across diverse demographic groups. By creating a diverse set of synthetic samples that represent various demographic groups, we ensure that our model is trained on a balanced and representative dataset. This approach allows us to generalize fairness more effectively across different domains. We employ a comprehensive strategy that leverages synthetic data, a loss sharpness-aware optimization pipeline, and a multi-task learning framework to create a more equitable training environment, which helps maintain fairness across both intra-dataset and cross-dataset evaluations. Extensive experiments on benchmark deepfake detection datasets demonstrate the efficacy of our approach, surpassing state-of-the-art approaches in preserving fairness during cross-dataset evaluation. Our results highlight the potential of synthetic datasets in achieving fairness generalization, providing a robust solution for the challenges faced in deepfake detection.
Deepfake detection, image manipulation detection, fairness, generalization
Dec 21, 2024Despite the progress made in deepfake detection research, recent studies have shown that biases in the training data for these detectors can result in varying levels of performance across different demographic groups, such as race and gender. These disparities can lead to certain groups being unfairly targeted or excluded. Traditional methods often rely on fair loss functions to address these issues, but they under-perform when applied to unseen datasets, hence, fairness generalization remains a challenge. In this work, we propose a data-driven framework for tackling the fairness generalization problem in deepfake detection by leveraging synthetic datasets and model optimization. Our approach focuses on generating and utilizing synthetic data to enhance fairness across diverse demographic groups. By creating a diverse set of synthetic samples that represent various demographic groups, we ensure that our model is trained on a balanced and representative dataset. This approach allows us to generalize fairness more effectively across different domains. We employ a comprehensive strategy that leverages synthetic data, a loss sharpness-aware optimization pipeline, and a multi-task learning framework to create a more equitable training environment, which helps maintain fairness across both intra-dataset and cross-dataset evaluations. Extensive experiments on benchmark deepfake detection datasets demonstrate the efficacy of our approach, surpassing state-of-the-art approaches in preserving fairness during cross-dataset evaluation. Our results highlight the potential of synthetic datasets in achieving fairness generalization, providing a robust solution for the challenges faced in deepfake detection.