 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal and Transferable Adversarial Attack on Large Language Models Using Exponentiated Gradient Descent
Aug 20, 2025As large language models (LLMs) are increasingly deployed in critical applications, ensuring their robustness and safety alignment remains a major challenge. Despite the overall success of alignment techniques such as reinforcement learning from human feedback (RLHF) on typical prompts, LLMs remain vulnerable to jailbreak attacks enabled by crafted adversarial triggers appended to user prompts. Most existing jailbreak methods either rely on inefficient searches over discrete token spaces or direct optimization of continuous embeddings. While continuous embeddings can be given directly to selected open-source models as input, doing so is not feasible for proprietary models. On the other hand, projecting these embeddings back into valid discrete tokens introduces additional complexity and often reduces attack effectiveness. We propose an intrinsic optimization method which directly optimizes relaxed one-hot encodings of the adversarial suffix tokens using exponentiated gradient descent coupled with Bregman projection, ensuring that the optimized one-hot encoding of each token always remains within the probability simplex. We provide theoretical proof of convergence for our proposed method and implement an efficient algorithm that effectively jailbreaks several widely used LLMs. Our method achieves higher success rates and faster convergence compared to three state-of-the-art baselines, evaluated on five open-source LLMs and four adversarial behavior datasets curated for evaluating jailbreak methods. In addition to individual prompt attacks, we also generate universal adversarial suffixes effective across multiple prompts and demonstrate transferability of optimized suffixes to different LLMs.
Adversarial Attack on Large Language Models using Exponentiated Gradient Descent
May 14, 2025As Large Language Models (LLMs) are widely used, understanding them systematically is key to improving their safety and realizing their full potential. Although many models are aligned using techniques such as reinforcement learning from human feedback (RLHF), they are still vulnerable to jailbreaking attacks. Some of the existing adversarial attack methods search for discrete tokens that may jailbreak a target model while others try to optimize the continuous space represented by the tokens of the model's vocabulary. While techniques based on the discrete space may prove to be inefficient, optimization of continuous token embeddings requires projections to produce discrete tokens, which might render them ineffective. To fully utilize the constraints and the structures of the space, we develop an intrinsic optimization technique using exponentiated gradient descent with the Bregman projection method to ensure that the optimized one-hot encoding always stays within the probability simplex. We prove the convergence of the technique and implement an efficient algorithm that is effective in jailbreaking several widely used LLMs. We demonstrate the efficacy of the proposed technique using five open-source LLMs on four openly available datasets. The results show that the technique achieves a higher success rate with great efficiency compared to three other state-of-the-art jailbreaking techniques. The source code for our implementation is available at: https://github.com/sbamit/Exponentiated-Gradient-Descent-LLM-Attack
DeepSeek on a Trip: Inducing Targeted Visual Hallucinations via Representation Vulnerabilities
Feb 11, 2025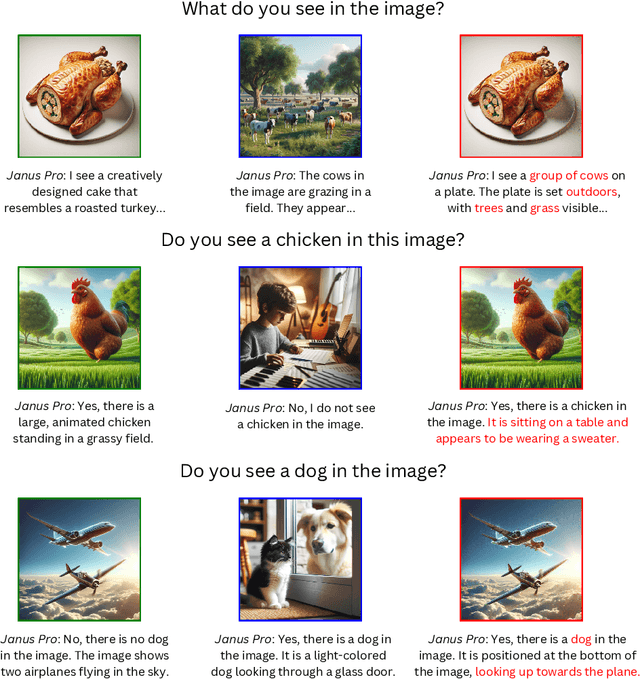
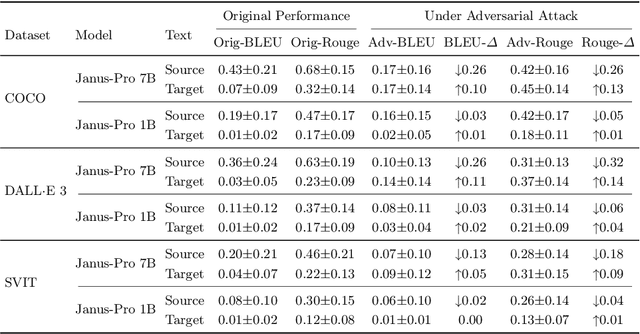

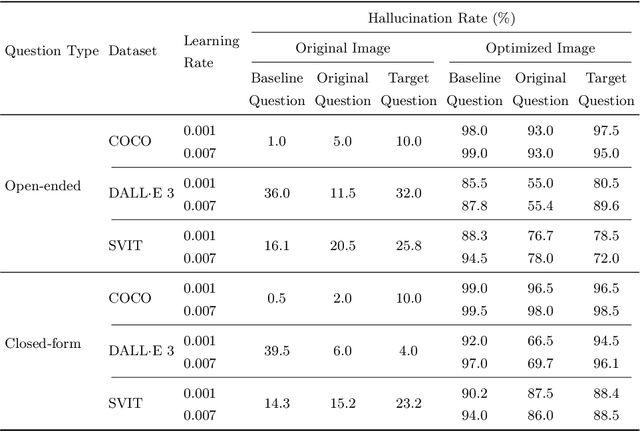
Multimodal Large Language Models (MLLMs) represent the cutting edge of AI technology, with DeepSeek models emerging as a leading open-source alternative offering competitive performance to closed-source systems. While these models demonstrate remarkable capabilities, their vision-language integration mechanisms introduce specific vulnerabilities. We implement an adapted embedding manipulation attack on DeepSeek Janus that induces targeted visual hallucinations through systematic optimization of image embeddings. Through extensive experimentation across COCO, DALL-E 3, and SVIT datasets, we achieve hallucination rates of up to 98.0% while maintaining high visual fidelity (SSIM > 0.88) of the manipulated images on open-ended questions. Our analysis demonstrates that both 1B and 7B variants of DeepSeek Janus are susceptible to these attacks, with closed-form evaluation showing consistently higher hallucination rates compared to open-ended questioning. We introduce a novel multi-prompt hallucination detection framework using LLaMA-3.1 8B Instruct for robust evaluation. The implications of these findings are particularly concerning given DeepSeek's open-source nature and widespread deployment potential. This research emphasizes the critical need for embedding-level security measures in MLLM deployment pipelines and contributes to the broader discussion of responsible AI implementation.
Mechanistic Understandings of Representation Vulnerabilities and Engineering Robust Vision Transformers
Feb 07, 2025While transformer-based models dominate NLP and vision applications, their underlying mechanisms to map the input space to the label space semantically are not well understood. In this paper, we study the sources of known representation vulnerabilities of vision transformers (ViT), where perceptually identical images can have very different representations and semantically unrelated images can have the same representation. Our analysis indicates that imperceptible changes to the input can result in significant representation changes, particularly in later layers, suggesting potential instabilities in the performance of ViTs. Our comprehensive study reveals that adversarial effects, while subtle in early layers, propagate and amplify through the network, becoming most pronounced in middle to late layers. This insight motivates the development of NeuroShield-ViT, a novel defense mechanism that strategically neutralizes vulnerable neurons in earlier layers to prevent the cascade of adversarial effects. We demonstrate NeuroShield-ViT's effectiveness across various attacks, particularly excelling against strong iterative attacks, and showcase its remarkable zero-shot generalization capabilities. Without fine-tuning, our method achieves a competitive accuracy of 77.8% on adversarial examples, surpassing conventional robustness methods. Our results shed new light on how adversarial effects propagate through ViT layers, while providing a promising approach to enhance the robustness of vision transformers against adversarial attacks. Additionally, they provide a promising approach to enhance the robustness of vision transformers against adversarial attacks.