 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting and Controlling Model Behavior via Constitutions for Atomic Concept Edits
Jan 23, 2026We introduce a black-box interpretability framework that learns a verifiable constitution: a natural language summary of how changes to a prompt affect a model's specific behavior, such as its alignment, correctness, or adherence to constraints. Our method leverages atomic concept edits (ACEs), which are targeted operations that add, remove, or replace an interpretable concept in the input prompt. By systematically applying ACEs and observing the resulting effects on model behavior across various tasks, our framework learns a causal mapping from edits to predictable outcomes. This learned constitution provides deep, generalizable insights into the model. Empirically, we validate our approach across diverse tasks, including mathematical reasoning and text-to-image alignment, for controlling and understanding model behavior. We found that for text-to-image generation, GPT-Image tends to focus on grammatical adherence, while Imagen 4 prioritizes atmospheric coherence. In mathematical reasoning, distractor variables confuse GPT-5 but leave Gemini 2.5 models and o4-mini largely unaffected. Moreover, our results show that the learned constitutions are highly effective for controlling model behavior, achieving an average of 1.86 times boost in success rate over methods that do not use constitutions.
ShieldGemma: Generative AI Content Moderation Based on Gemma
Jul 31, 2024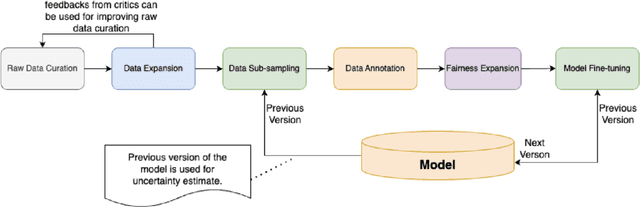
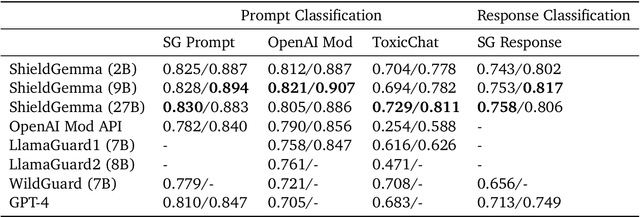

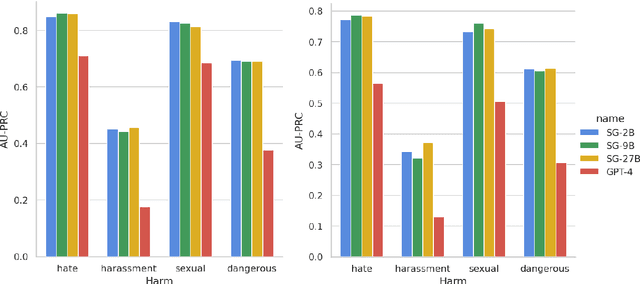
We present ShieldGemma, a comprehensive suite of LLM-based safety content moderation models built upon Gemma2. These models provide robust, state-of-the-art predictions of safety risks across key harm types (sexually explicit, dangerous content, harassment, hate speech) in both user input and LLM-generated output. By evaluating on both public and internal benchmarks, we demonstrate superior performance compared to existing models, such as Llama Guard (+10.8\% AU-PRC on public benchmarks) and WildCard (+4.3\%). Additionally, we present a novel LLM-based data curation pipeline, adaptable to a variety of safety-related tasks and beyond. We have shown strong generalization performance for model trained mainly on synthetic data. By releasing ShieldGemma, we provide a valuable resource to the research community, advancing LLM safety and enabling the creation of more effective content moderation solutions for developers.