 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning-Driven Synthetic Data Generation and Evaluation
Mar 31, 2026Although many AI applications of interest require specialized multi-modal models, relevant data to train such models is inherently scarce or inaccessible. Filling these gaps with human annotators is prohibitively expensive, error-prone, and time-consuming, leading model builders to increasingly consider synthetic data as a scalable alternative. However, existing synthetic data generation methods often rely on manual prompts, evolutionary algorithms, or extensive seed data from the target distribution - limiting their scalability, explainability, and control. In this paper, we introduce Simula: a novel reasoning-driven framework for data generation and evaluation. It employs a seedless, agentic approach to generate synthetic datasets at scale, allowing users to define desired dataset characteristics through an explainable and controllable process that enables fine-grained resource allocation. We show the efficacy of our approach on a variety of datasets, rigorously testing both intrinsic and downstream properties. Our work (1) offers guidelines for synthetic data mechanism design, (2) provides insights into generating and evaluating synthetic data at scale, and (3) unlocks new opportunities for developing and deploying AI in domains where data scarcity or privacy concerns are paramount.
Democratizing ML for Enterprise Security: A Self-Sustained Attack Detection Framework
Dec 09, 2025Despite advancements in machine learning for security, rule-based detection remains prevalent in Security Operations Centers due to the resource intensiveness and skill gap associated with ML solutions. While traditional rule-based methods offer efficiency, their rigidity leads to high false positives or negatives and requires continuous manual maintenance. This paper proposes a novel, two-stage hybrid framework to democratize ML-based threat detection. The first stage employs intentionally loose YARA rules for coarse-grained filtering, optimized for high recall. The second stage utilizes an ML classifier to filter out false positives from the first stage's output. To overcome data scarcity, the system leverages Simula, a seedless synthetic data generation framework, enabling security analysts to create high-quality training datasets without extensive data science expertise or pre-labeled examples. A continuous feedback loop incorporates real-time investigation results to adaptively tune the ML model, preventing rule degradation. This proposed model with active learning has been rigorously tested for a prolonged time in a production environment spanning tens of thousands of systems. The system handles initial raw log volumes often reaching 250 billion events per day, significantly reducing them through filtering and ML inference to a handful of daily tickets for human investigation. Live experiments over an extended timeline demonstrate a general improvement in the model's precision over time due to the active learning feature. This approach offers a self-sustained, low-overhead, and low-maintenance solution, allowing security professionals to guide model learning as expert ``teachers''.
ShieldGemma: Generative AI Content Moderation Based on Gemma
Jul 31, 2024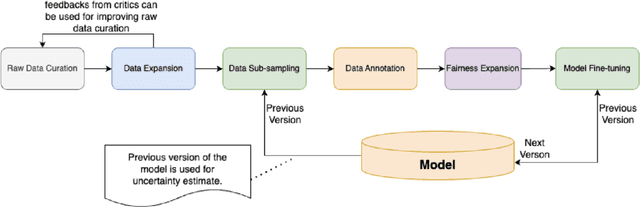
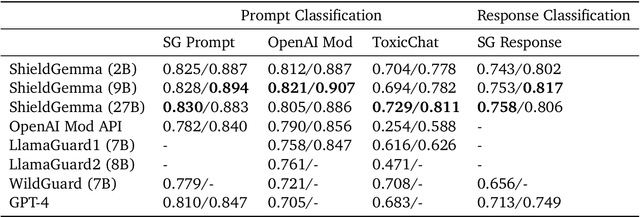

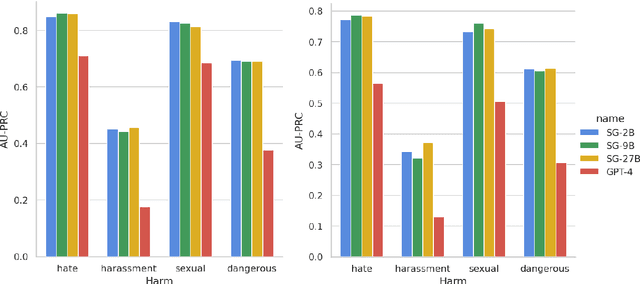
We present ShieldGemma, a comprehensive suite of LLM-based safety content moderation models built upon Gemma2. These models provide robust, state-of-the-art predictions of safety risks across key harm types (sexually explicit, dangerous content, harassment, hate speech) in both user input and LLM-generated output. By evaluating on both public and internal benchmarks, we demonstrate superior performance compared to existing models, such as Llama Guard (+10.8\% AU-PRC on public benchmarks) and WildCard (+4.3\%). Additionally, we present a novel LLM-based data curation pipeline, adaptable to a variety of safety-related tasks and beyond. We have shown strong generalization performance for model trained mainly on synthetic data. By releasing ShieldGemma, we provide a valuable resource to the research community, advancing LLM safety and enabling the creation of more effective content moderation solutions for developers.
A Decade of Privacy-Relevant Android App Reviews: Large Scale Trends
Mar 07, 2024



We present an analysis of 12 million instances of privacy-relevant reviews publicly visible on the Google Play Store that span a 10 year period. By leveraging state of the art NLP techniques, we examine what users have been writing about privacy along multiple dimensions: time, countries, app types, diverse privacy topics, and even across a spectrum of emotions. We find consistent growth of privacy-relevant reviews, and explore topics that are trending (such as Data Deletion and Data Theft), as well as those on the decline (such as privacy-relevant reviews on sensitive permissions). We find that although privacy reviews come from more than 200 countries, 33 countries provide 90% of privacy reviews. We conduct a comparison across countries by examining the distribution of privacy topics a country's users write about, and find that geographic proximity is not a reliable indicator that nearby countries have similar privacy perspectives. We uncover some countries with unique patterns and explore those herein. Surprisingly, we uncover that it is not uncommon for reviews that discuss privacy to be positive (32%); many users express pleasure about privacy features within apps or privacy-focused apps. We also uncover some unexpected behaviors, such as the use of reviews to deliver privacy disclaimers to developers. Finally, we demonstrate the value of analyzing app reviews with our approach as a complement to existing methods for understanding users' perspectives about privacy
Have Your Text and Use It Too! End-to-End Neural Data-to-Text Generation with Semantic Fidelity
Apr 08, 2020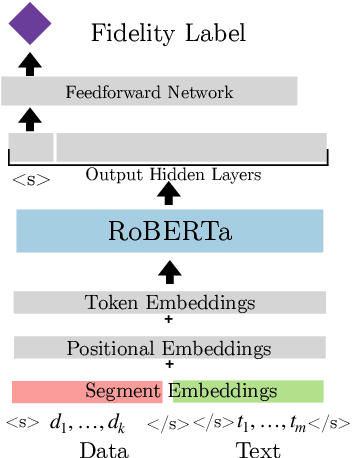
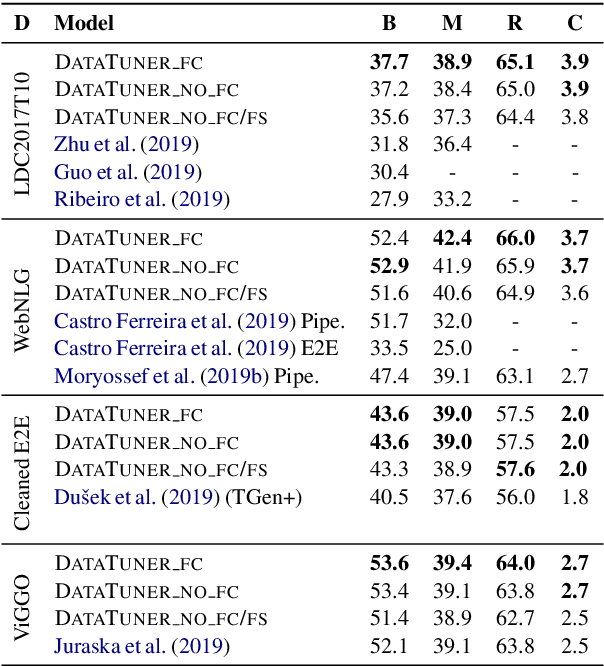
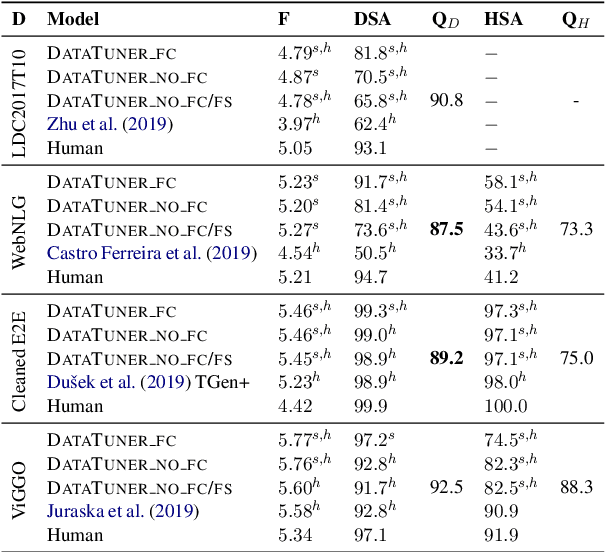
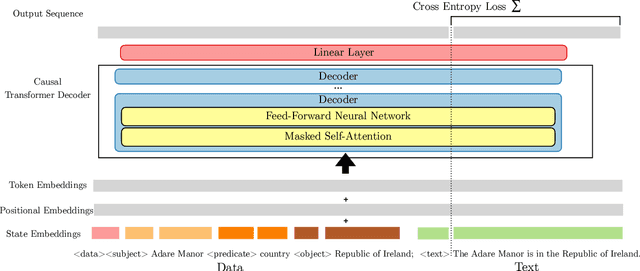
End-to-end neural data-to-text (D2T) generation has recently emerged as an alternative to pipeline-based architectures. However, it has faced challenges in generalizing to new domains and generating semantically consistent text. In this work, we present DataTuner, a neural, end-to-end data-to-text generation system that makes minimal assumptions about the data representation and the target domain. We take a two-stage generation-reranking approach, combining a fine-tuned language model with a semantic fidelity classifier. Each of our components is learnt end-to-end without the need for dataset-specific heuristics, entity delexicalization, or post-processing. We show that DataTuner achieves state of the art results on the automated metrics across four major D2T datasets (LDC2017T10, WebNLG, ViGGO, and Cleaned E2E), with a fluency assessed by human annotators nearing or exceeding the human-written reference texts. We further demonstrate that the model-based semantic fidelity scorer in DataTuner is a better assessment tool compared to traditional, heuristic-based measures. Our generated text has a significantly better semantic fidelity than the state of the art across all four datasets
The Privacy Policy Landscape After the GDPR
Sep 22, 2018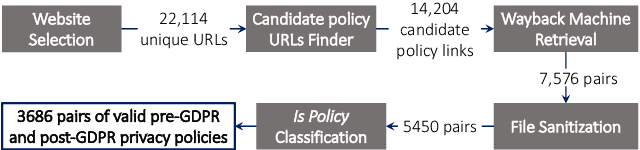
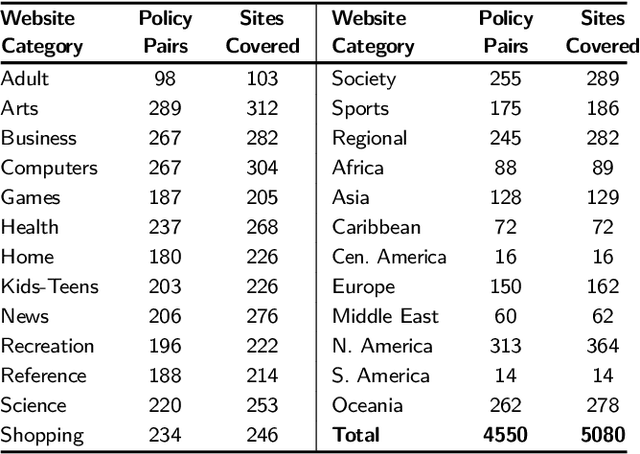
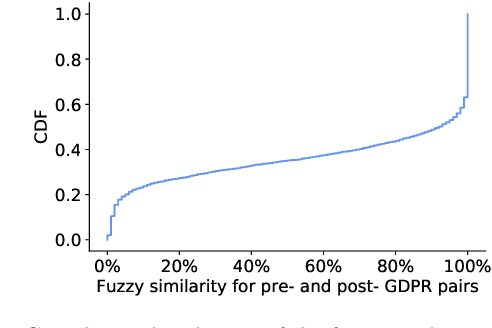
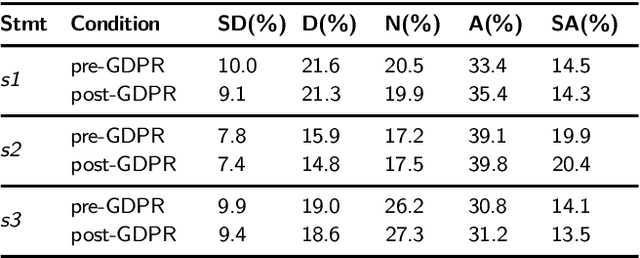
Every new privacy regulation brings along the question of whether it results in improving the privacy for the users or whether it creates more barriers to understanding and exercising their rights. The EU General Data Protection Regulation (GDPR) is one of the most demanding and comprehensive privacy regulations of all time. Hence, a few months after it went into effect, it is natural to study its impact over the landscape of privacy policies online. In this work, we conduct the first longitudinal, in-depth, and at-scale assessment of privacy policies before and after the GDPR. We gauge the complete consumption cycle of these policies, from the first user impressions until the compliance assessment. We create a diverse corpus of 3,086 English-language privacy policies for which we fetch the pre-GPDR and the post-GDPR versions. Via a user study with 530 participants on Amazon Mturk, we discover that the visual presentation of privacy policies has slightly improved in limited data-sensitive categories in addition to the top European websites. We also find that the readability of privacy policies suffers under the GDPR, due to almost a 30% more sentences and words, despite the efforts to reduce the reliance on passive sentences. We further develop a new workflow for the automated assessment of requirements in privacy policies, building on automated natural language processing techniques. We find evidence for positive changes triggered by the GDPR, with the ambiguity level, averaged over 8 metrics, improving in over 20.5% of the policies. Finally, we show that privacy policies cover more data practices, particularly around data retention, user access rights, and specific audiences, and that an average of 15.2% of the policies improved across 8 compliance metrics. Our analysis, however, reveals a large gap that exists between the current status-quo and the ultimate goals of the GDPR.
Polisis: Automated Analysis and Presentation of Privacy Policies Using Deep Learning
Jun 29, 2018

Privacy policies are the primary channel through which companies inform users about their data collection and sharing practices. These policies are often long and difficult to comprehend. Short notices based on information extracted from privacy policies have been shown to be useful but face a significant scalability hurdle, given the number of policies and their evolution over time. Companies, users, researchers, and regulators still lack usable and scalable tools to cope with the breadth and depth of privacy policies. To address these hurdles, we propose an automated framework for privacy policy analysis (Polisis). It enables scalable, dynamic, and multi-dimensional queries on natural language privacy policies. At the core of Polisis is a privacy-centric language model, built with 130K privacy policies, and a novel hierarchy of neural-network classifiers that accounts for both high-level aspects and fine-grained details of privacy practices. We demonstrate Polisis' modularity and utility with two applications supporting structured and free-form querying. The structured querying application is the automated assignment of privacy icons from privacy policies. With Polisis, we can achieve an accuracy of 88.4% on this task. The second application, PriBot, is the first freeform question-answering system for privacy policies. We show that PriBot can produce a correct answer among its top-3 results for 82% of the test questions. Using an MTurk user study with 700 participants, we show that at least one of PriBot's top-3 answers is relevant to users for 89% of the test questions.
Taxonomy Induction using Hypernym Subsequences
Sep 14, 2017

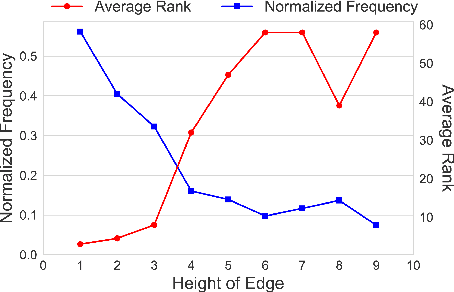
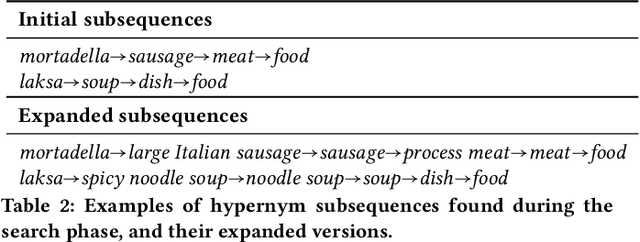
We propose a novel, semi-supervised approach towards domain taxonomy induction from an input vocabulary of seed terms. Unlike all previous approaches, which typically extract direct hypernym edges for terms, our approach utilizes a novel probabilistic framework to extract hypernym subsequences. Taxonomy induction from extracted subsequences is cast as an instance of the minimumcost flow problem on a carefully designed directed graph. Through experiments, we demonstrate that our approach outperforms stateof- the-art taxonomy induction approaches across four languages. Importantly, we also show that our approach is robust to the presence of noise in the input vocabulary. To the best of our knowledge, no previous approaches have been empirically proven to manifest noise-robustness in the input vocabulary.
280 Birds with One Stone: Inducing Multilingual Taxonomies from Wikipedia using Character-level Classification
Sep 12, 2017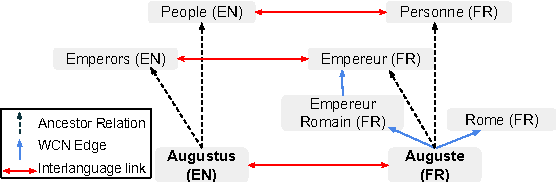

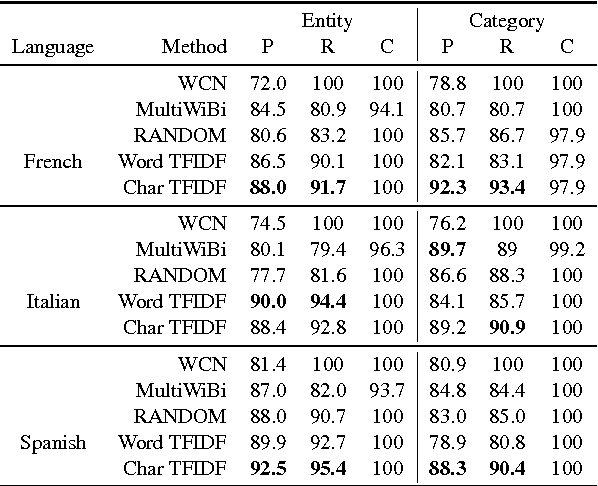
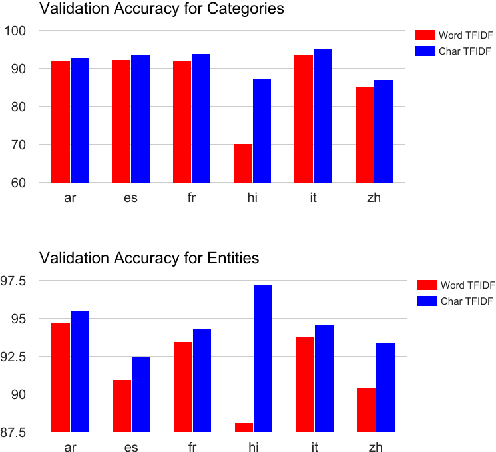
We propose a simple, yet effective, approach towards inducing multilingual taxonomies from Wikipedia. Given an English taxonomy, our approach leverages the interlanguage links of Wikipedia followed by character-level classifiers to induce high-precision, high-coverage taxonomies in other languages. Through experiments, we demonstrate that our approach significantly outperforms the state-of-the-art, heuristics-heavy approaches for six languages. As a consequence of our work, we release presumably the largest and the most accurate multilingual taxonomic resource spanning over 280 languages.