 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-Augmented Language Model Prompting for Zero-Shot Knowledge Graph Question Answering
Jun 07, 2023



Large Language Models (LLMs) are capable of performing zero-shot closed-book question answering tasks, based on their internal knowledge stored in parameters during pre-training. However, such internalized knowledge might be insufficient and incorrect, which could lead LLMs to generate factually wrong answers. Furthermore, fine-tuning LLMs to update their knowledge is expensive. To this end, we propose to augment the knowledge directly in the input of LLMs. Specifically, we first retrieve the relevant facts to the input question from the knowledge graph based on semantic similarities between the question and its associated facts. After that, we prepend the retrieved facts to the input question in the form of the prompt, which is then forwarded to LLMs to generate the answer. Our framework, Knowledge-Augmented language model PromptING (KAPING), requires no model training, thus completely zero-shot. We validate the performance of our KAPING framework on the knowledge graph question answering task, that aims to answer the user's question based on facts over a knowledge graph, on which ours outperforms relevant zero-shot baselines by up to 48% in average, across multiple LLMs of various sizes.
CLASP: Few-Shot Cross-Lingual Data Augmentation for Semantic Parsing
Oct 14, 2022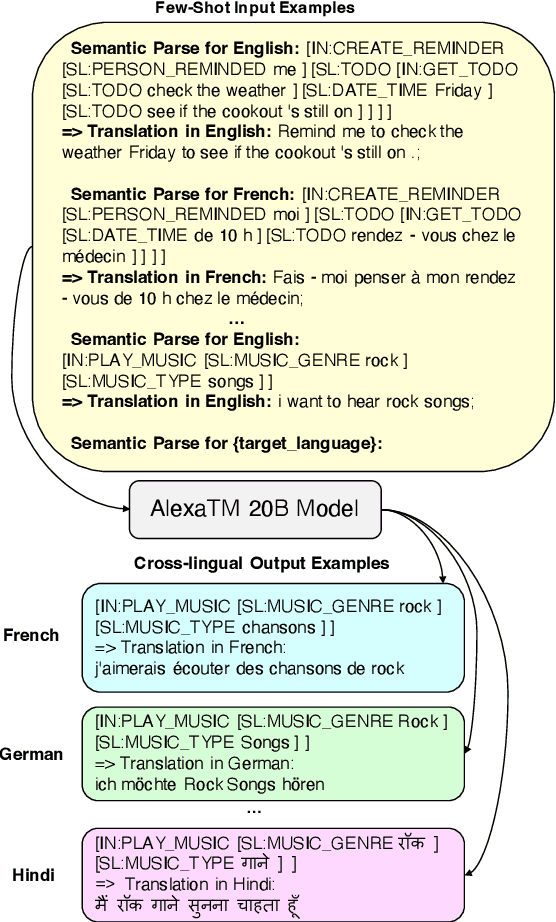
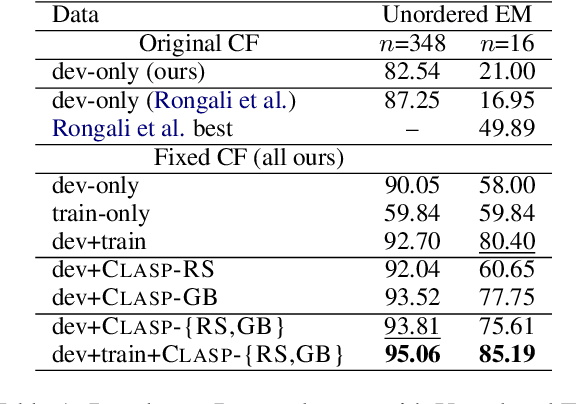

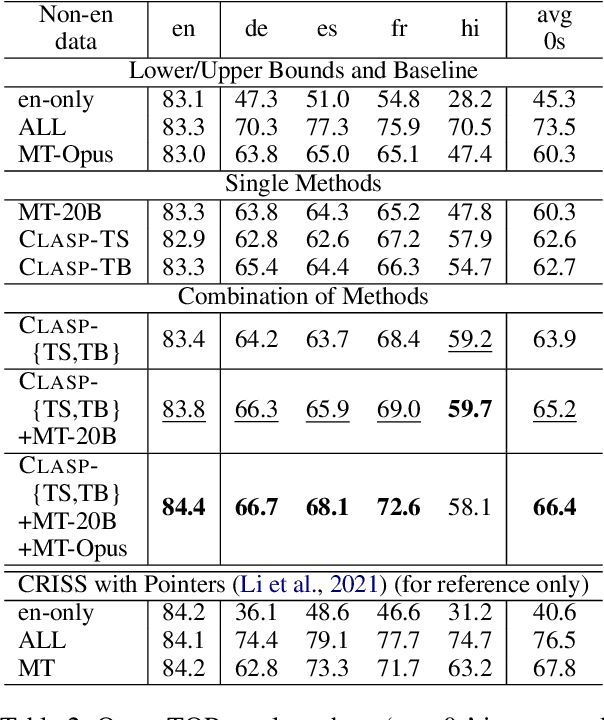
A bottleneck to developing Semantic Parsing (SP) models is the need for a large volume of human-labeled training data. Given the complexity and cost of human annotation for SP, labeled data is often scarce, particularly in multilingual settings. Large Language Models (LLMs) excel at SP given only a few examples, however LLMs are unsuitable for runtime systems which require low latency. In this work, we propose CLASP, a simple method to improve low-resource SP for moderate-sized models: we generate synthetic data from AlexaTM 20B to augment the training set for a model 40x smaller (500M parameters). We evaluate on two datasets in low-resource settings: English PIZZA, containing either 348 or 16 real examples, and mTOP cross-lingual zero-shot, where training data is available only in English, and the model must generalize to four new languages. On both datasets, we show significant improvements over strong baseline methods.
Mintaka: A Complex, Natural, and Multilingual Dataset for End-to-End Question Answering
Oct 04, 2022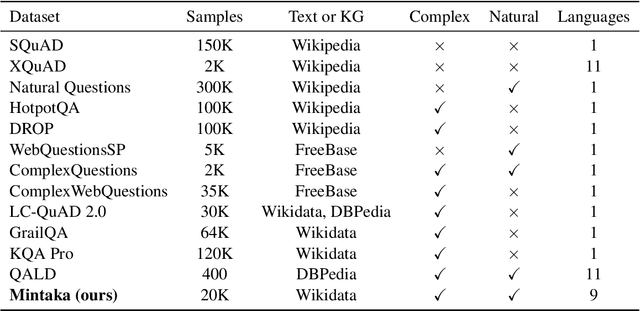
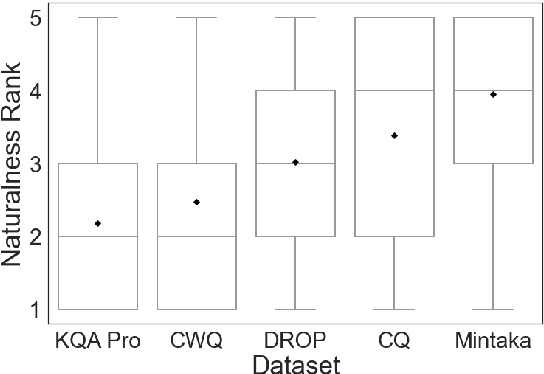

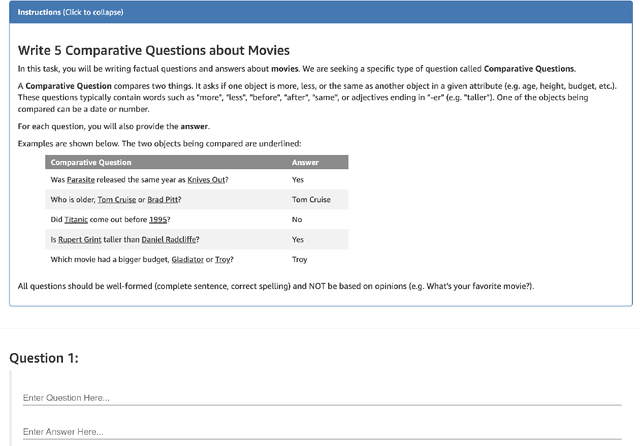
We introduce Mintaka, a complex, natural, and multilingual dataset designed for experimenting with end-to-end question-answering models. Mintaka is composed of 20,000 question-answer pairs collected in English, annotated with Wikidata entities, and translated into Arabic, French, German, Hindi, Italian, Japanese, Portuguese, and Spanish for a total of 180,000 samples. Mintaka includes 8 types of complex questions, including superlative, intersection, and multi-hop questions, which were naturally elicited from crowd workers. We run baselines over Mintaka, the best of which achieves 38% hits@1 in English and 31% hits@1 multilingually, showing that existing models have room for improvement. We release Mintaka at https://github.com/amazon-research/mintaka.
End-to-End Entity Resolution and Question Answering Using Differentiable Knowledge Graphs
Sep 13, 2021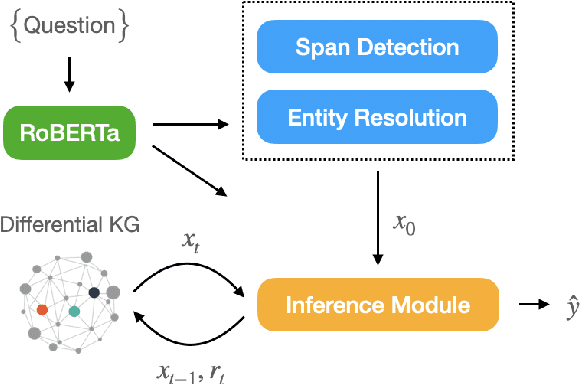

Recently, end-to-end (E2E) trained models for question answering over knowledge graphs (KGQA) have delivered promising results using only a weakly supervised dataset. However, these models are trained and evaluated in a setting where hand-annotated question entities are supplied to the model, leaving the important and non-trivial task of entity resolution (ER) outside the scope of E2E learning. In this work, we extend the boundaries of E2E learning for KGQA to include the training of an ER component. Our model only needs the question text and the answer entities to train, and delivers a stand-alone QA model that does not require an additional ER component to be supplied during runtime. Our approach is fully differentiable, thanks to its reliance on a recent method for building differentiable KGs (Cohen et al., 2020). We evaluate our E2E trained model on two public datasets and show that it comes close to baseline models that use hand-annotated entities.
Expanding End-to-End Question Answering on Differentiable Knowledge Graphs with Intersection
Sep 13, 2021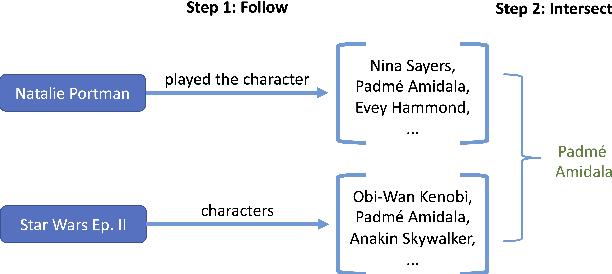
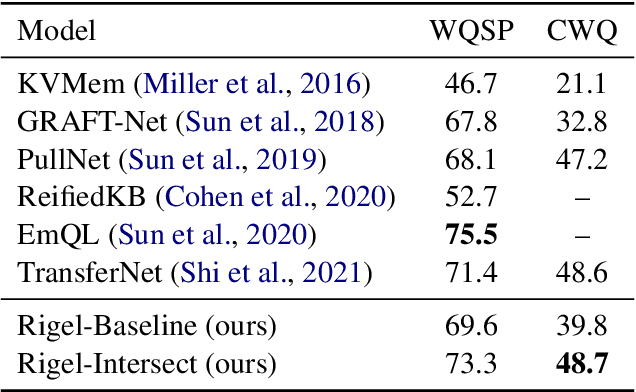
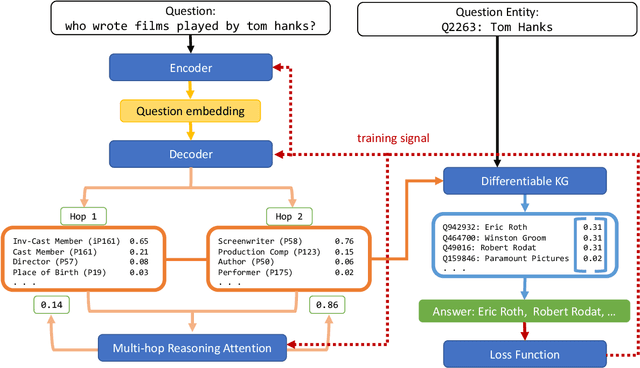
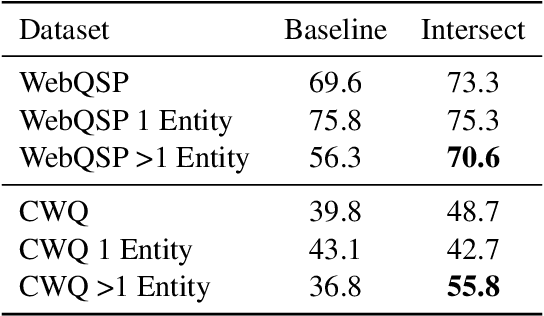
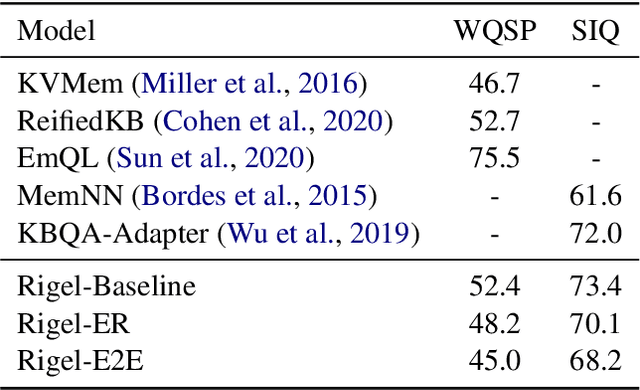
End-to-end question answering using a differentiable knowledge graph is a promising technique that requires only weak supervision, produces interpretable results, and is fully differentiable. Previous implementations of this technique (Cohen et al., 2020) have focused on single-entity questions using a relation following operation. In this paper, we propose a model that explicitly handles multiple-entity questions by implementing a new intersection operation, which identifies the shared elements between two sets of entities. We find that introducing intersection improves performance over a baseline model on two datasets, WebQuestionsSP (69.6% to 73.3% Hits@1) and ComplexWebQuestions (39.8% to 48.7% Hits@1), and in particular, improves performance on questions with multiple entities by over 14% on WebQuestionsSP and by 19% on ComplexWebQuestions.
Relation Extraction from Tables using Artificially Generated Metadata
Sep 06, 2021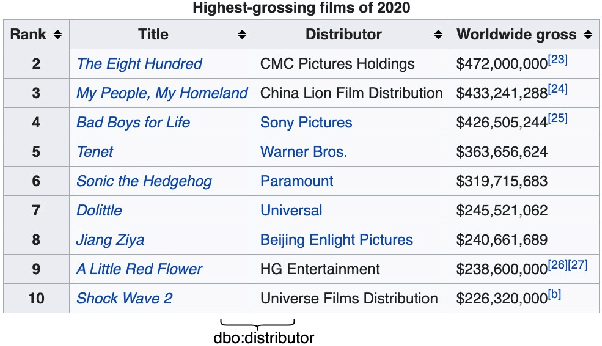
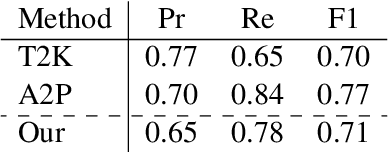
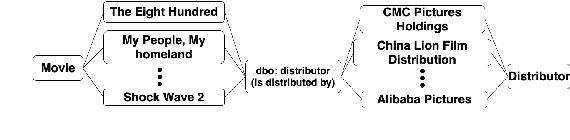

Relation Extraction (RE) from tables is the task of identifying relations between pairs of columns of a table. Generally, RE models for this task require labelled tables for training. These labelled tables can also be generated artificially from a Knowledge Graph (KG), which makes the cost to acquire them much lower in comparison to manual annotations. However, unlike real tables, these synthetic tables lack associated metadata, such as, column-headers, captions, etc; this is because synthetic tables are created out of KGs that do not store such metadata. Meanwhile, previous works have shown that metadata is important for accurate RE from tables. To address this issue, we propose methods to artificially create some of this metadata for synthetic tables. Afterward, we experiment with a BERT-based model, in line with recently published works, that takes as input a combination of proposed artificial metadata and table content. Our empirical results show that this leads to an improvement of 9\%-45\% in F1 score, in absolute terms, over 2 tabular datasets.
Have Your Text and Use It Too! End-to-End Neural Data-to-Text Generation with Semantic Fidelity
Apr 08, 2020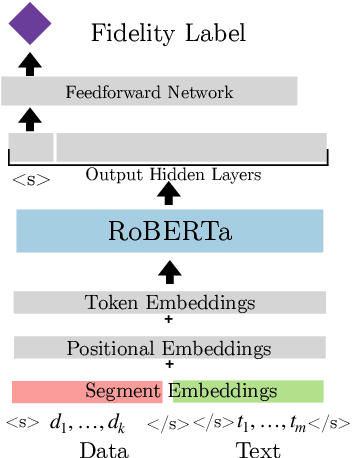
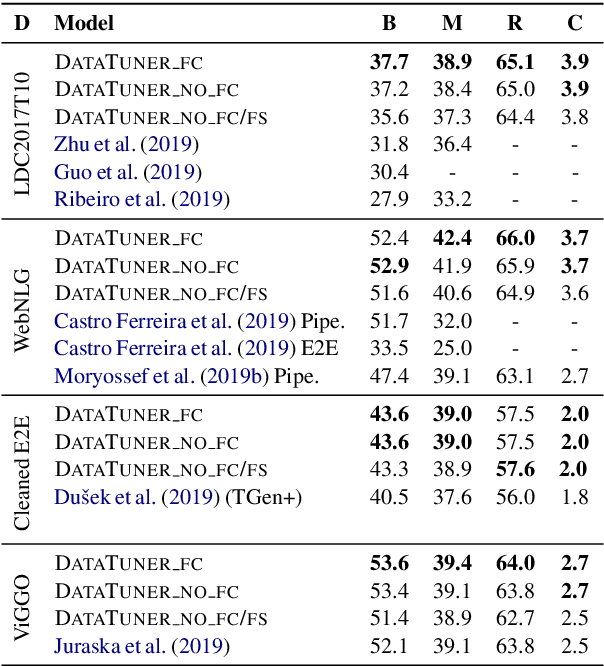
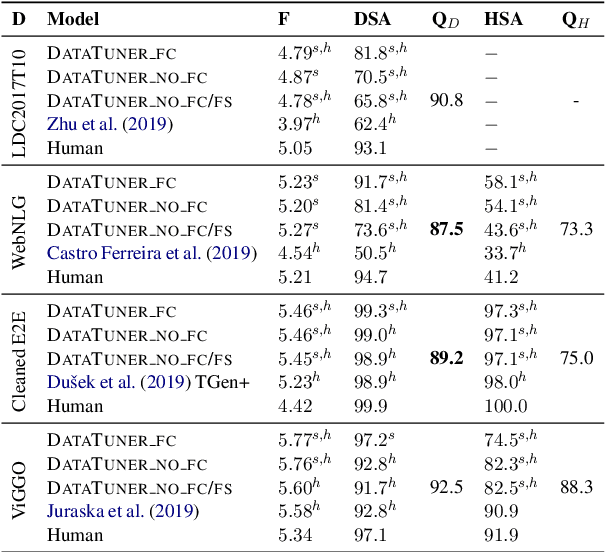
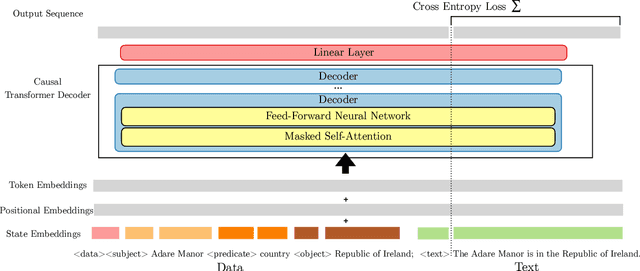
End-to-end neural data-to-text (D2T) generation has recently emerged as an alternative to pipeline-based architectures. However, it has faced challenges in generalizing to new domains and generating semantically consistent text. In this work, we present DataTuner, a neural, end-to-end data-to-text generation system that makes minimal assumptions about the data representation and the target domain. We take a two-stage generation-reranking approach, combining a fine-tuned language model with a semantic fidelity classifier. Each of our components is learnt end-to-end without the need for dataset-specific heuristics, entity delexicalization, or post-processing. We show that DataTuner achieves state of the art results on the automated metrics across four major D2T datasets (LDC2017T10, WebNLG, ViGGO, and Cleaned E2E), with a fluency assessed by human annotators nearing or exceeding the human-written reference texts. We further demonstrate that the model-based semantic fidelity scorer in DataTuner is a better assessment tool compared to traditional, heuristic-based measures. Our generated text has a significantly better semantic fidelity than the state of the art across all four datasets
What do Models Learn from Question Answering Datasets?
Apr 07, 2020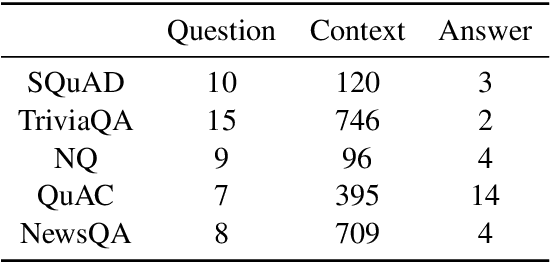
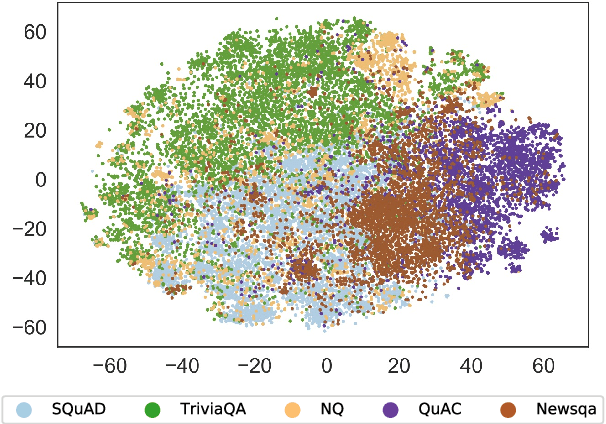
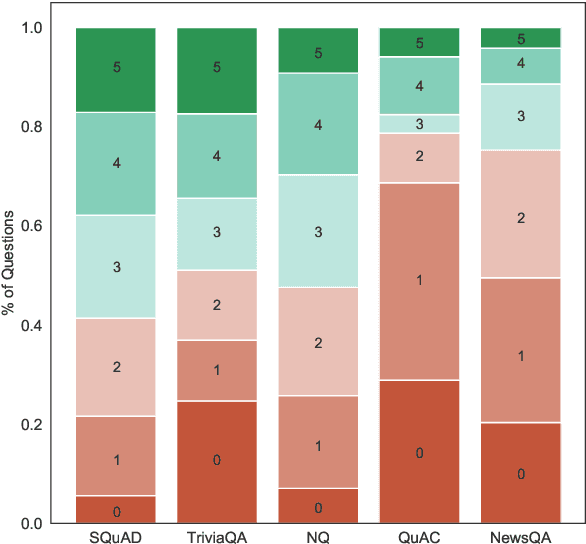
While models have reached superhuman performance on popular question answering (QA) datasets such as SQuAD, they have yet to outperform humans on the task of question answering itself. In this paper, we investigate what models are really learning from QA datasets by evaluating BERT-based models across five popular QA datasets. We evaluate models on their generalizability to out-of-domain examples, responses to missing or incorrect information in datasets, and ability to handle variations in questions. We find that no single dataset is robust to all of our experiments and identify shortcomings in both datasets and evaluation methods. Following our analysis, we make recommendations for building future QA datasets that better evaluate the task of question answering.
Interpretable Graph Convolutional Neural Networks for Inference on Noisy Knowledge Graphs
Dec 01, 2018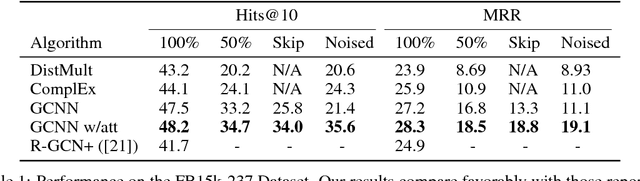
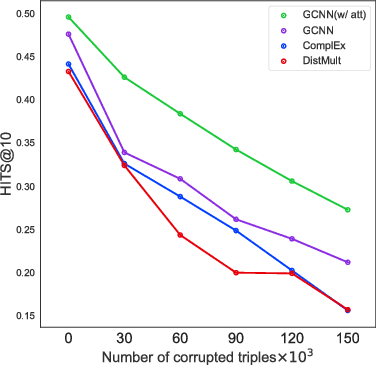
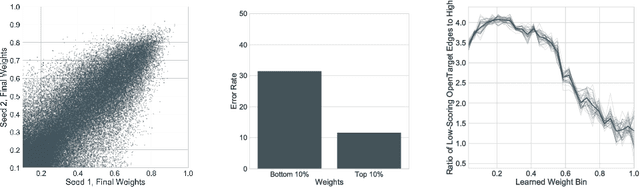
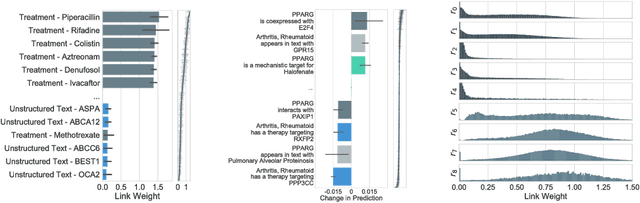
In this work, we provide a new formulation for Graph Convolutional Neural Networks (GCNNs) for link prediction on graph data that addresses common challenges for biomedical knowledge graphs (KGs). We introduce a regularized attention mechanism to GCNNs that not only improves performance on clean datasets, but also favorably accommodates noise in KGs, a pervasive issue in real-world applications. Further, we explore new visualization methods for interpretable modelling and to illustrate how the learned representation can be exploited to automate dataset denoising. The results are demonstrated on a synthetic dataset, the common benchmark dataset FB15k-237, and a large biomedical knowledge graph derived from a combination of noisy and clean data sources. Using these improvements, we visualize a learned model's representation of the disease cystic fibrosis and demonstrate how to interrogate a neural network to show the potential of PPARG as a candidate therapeutic target for rheumatoid arthritis.
DEFactor: Differentiable Edge Factorization-based Probabilistic Graph Generation
Nov 24, 2018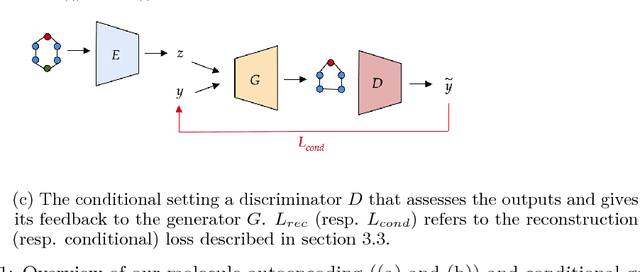
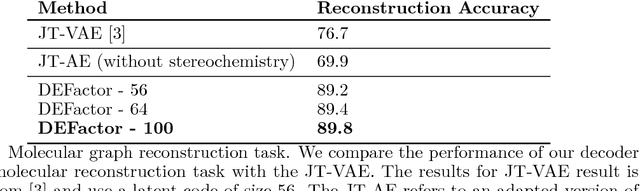
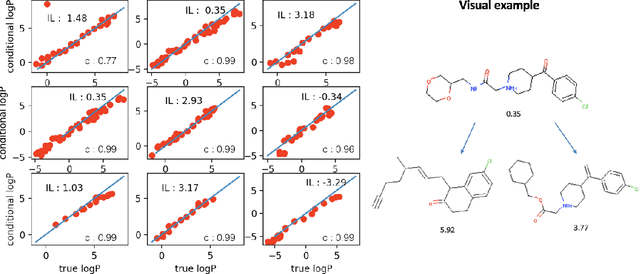
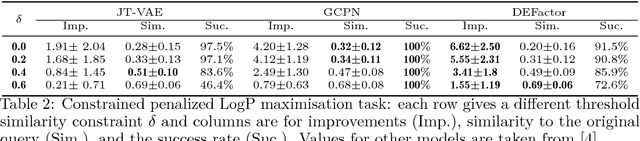
Generating novel molecules with optimal properties is a crucial step in many industries such as drug discovery. Recently, deep generative models have shown a promising way of performing de-novo molecular design. Although graph generative models are currently available they either have a graph size dependency in their number of parameters, limiting their use to only very small graphs or are formulated as a sequence of discrete actions needed to construct a graph, making the output graph non-differentiable w.r.t the model parameters, therefore preventing them to be used in scenarios such as conditional graph generation. In this work we propose a model for conditional graph generation that is computationally efficient and enables direct optimisation of the graph. We demonstrate favourable performance of our model on prototype-based molecular graph conditional generation tasks.