 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLASP: Few-Shot Cross-Lingual Data Augmentation for Semantic Parsing
Oct 14, 2022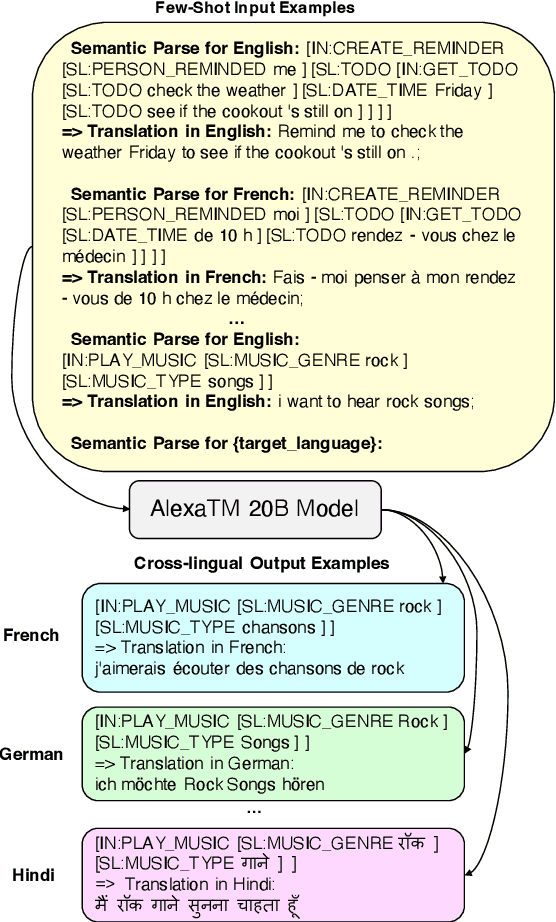
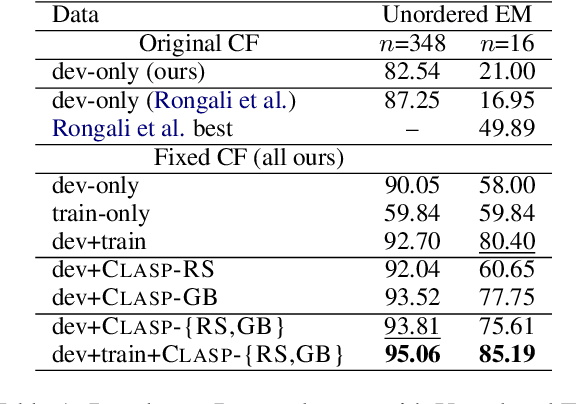

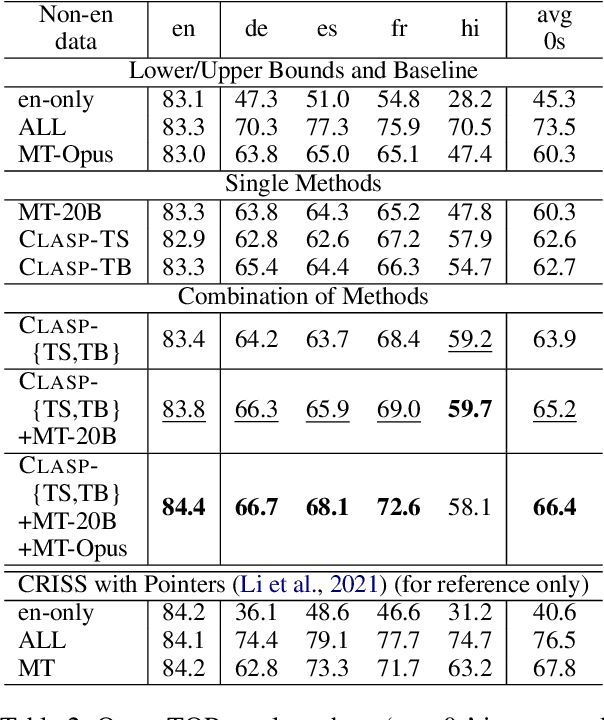
A bottleneck to developing Semantic Parsing (SP) models is the need for a large volume of human-labeled training data. Given the complexity and cost of human annotation for SP, labeled data is often scarce, particularly in multilingual settings. Large Language Models (LLMs) excel at SP given only a few examples, however LLMs are unsuitable for runtime systems which require low latency. In this work, we propose CLASP, a simple method to improve low-resource SP for moderate-sized models: we generate synthetic data from AlexaTM 20B to augment the training set for a model 40x smaller (500M parameters). We evaluate on two datasets in low-resource settings: English PIZZA, containing either 348 or 16 real examples, and mTOP cross-lingual zero-shot, where training data is available only in English, and the model must generalize to four new languages. On both datasets, we show significant improvements over strong baseline methods.
Have Your Text and Use It Too! End-to-End Neural Data-to-Text Generation with Semantic Fidelity
Apr 08, 2020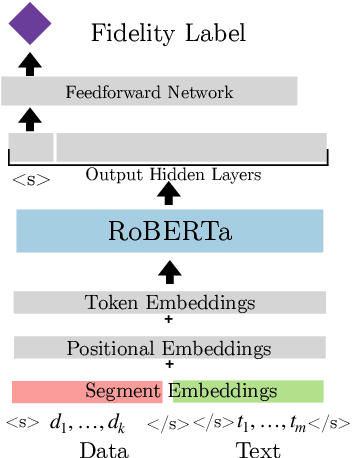
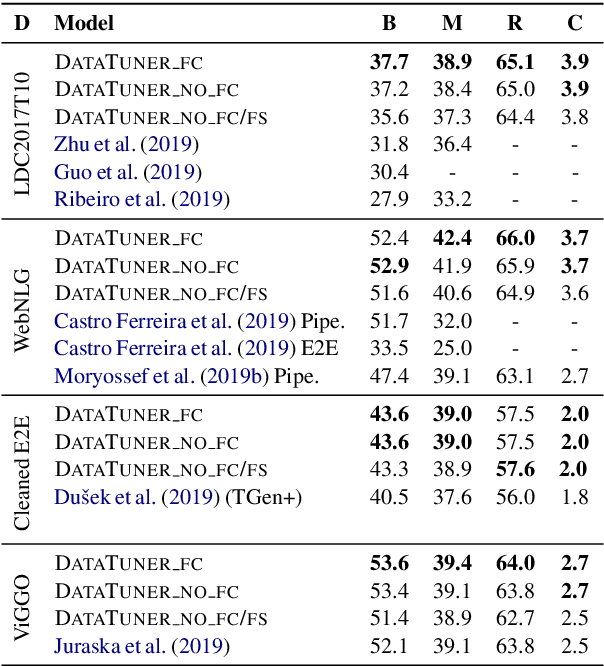
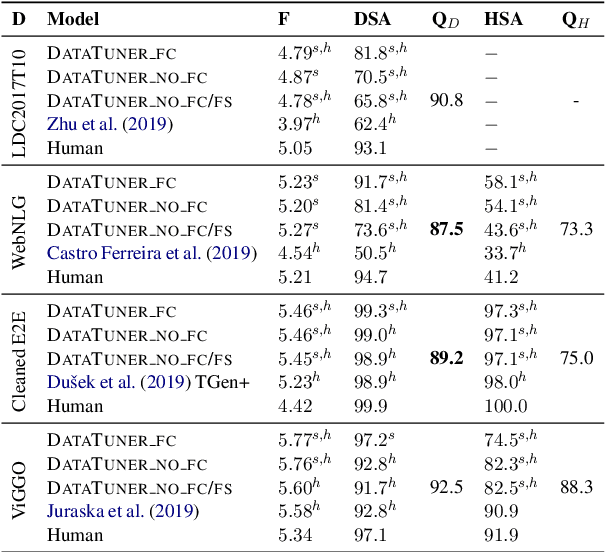
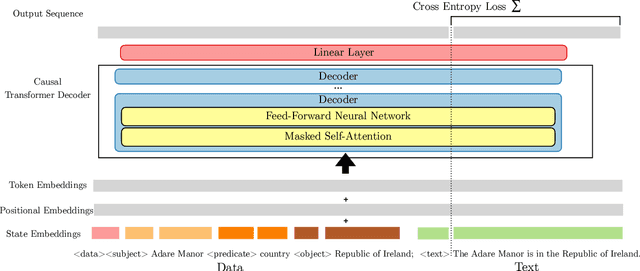
End-to-end neural data-to-text (D2T) generation has recently emerged as an alternative to pipeline-based architectures. However, it has faced challenges in generalizing to new domains and generating semantically consistent text. In this work, we present DataTuner, a neural, end-to-end data-to-text generation system that makes minimal assumptions about the data representation and the target domain. We take a two-stage generation-reranking approach, combining a fine-tuned language model with a semantic fidelity classifier. Each of our components is learnt end-to-end without the need for dataset-specific heuristics, entity delexicalization, or post-processing. We show that DataTuner achieves state of the art results on the automated metrics across four major D2T datasets (LDC2017T10, WebNLG, ViGGO, and Cleaned E2E), with a fluency assessed by human annotators nearing or exceeding the human-written reference texts. We further demonstrate that the model-based semantic fidelity scorer in DataTuner is a better assessment tool compared to traditional, heuristic-based measures. Our generated text has a significantly better semantic fidelity than the state of the art across all four datasets