 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMintaka: A Complex, Natural, and Multilingual Dataset for End-to-End Question Answering
Paper and Code
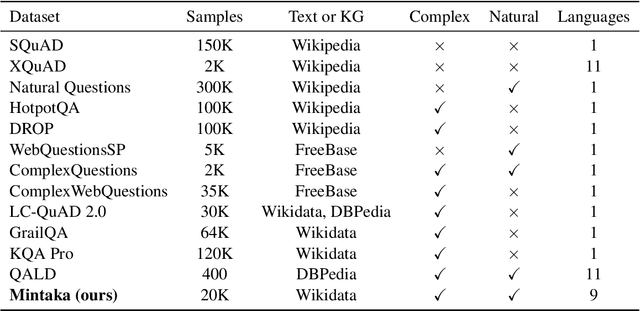
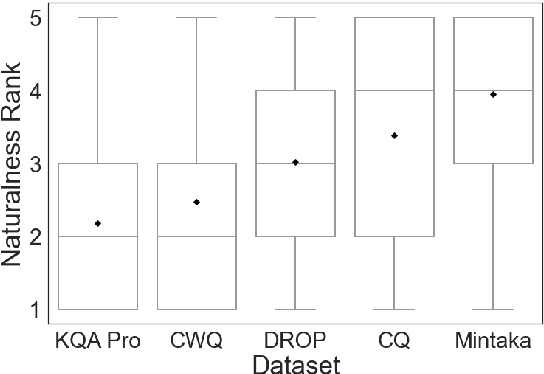

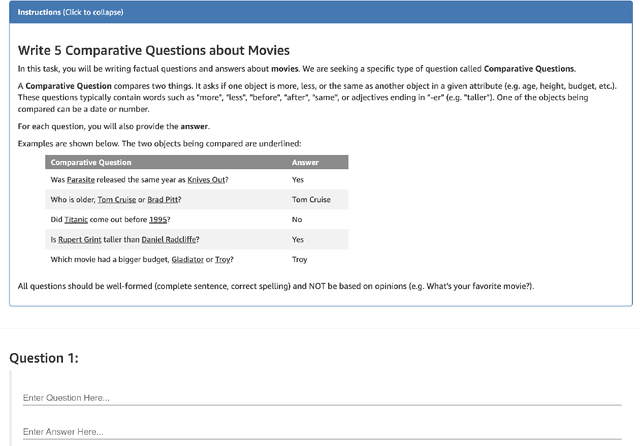
We introduce Mintaka, a complex, natural, and multilingual dataset designed for experimenting with end-to-end question-answering models. Mintaka is composed of 20,000 question-answer pairs collected in English, annotated with Wikidata entities, and translated into Arabic, French, German, Hindi, Italian, Japanese, Portuguese, and Spanish for a total of 180,000 samples. Mintaka includes 8 types of complex questions, including superlative, intersection, and multi-hop questions, which were naturally elicited from crowd workers. We run baselines over Mintaka, the best of which achieves 38% hits@1 in English and 31% hits@1 multilingually, showing that existing models have room for improvement. We release Mintaka at https://github.com/amazon-research/mintaka.