 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
ALR$^2$: A Retrieve-then-Reason Framework for Long-context Question Answering
Oct 04, 2024



The context window of large language models (LLMs) has been extended significantly in recent years. However, while the context length that the LLM can process has grown, the capability of the model to accurately reason over that context degrades noticeably. This occurs because modern LLMs often become overwhelmed by the vast amount of information in the context; when answering questions, the model must identify and reason over relevant evidence sparsely distributed throughout the text. To alleviate the challenge of long-context reasoning, we develop a retrieve-then-reason framework, enabling LLMs to reason over relevant evidence collected during an intermediate retrieval step. We find that modern LLMs struggle to accurately retrieve relevant facts and instead, often hallucinate "retrieved facts", resulting in flawed reasoning and the production of incorrect answers. To address these issues, we introduce ALR$^2$, a method that augments the long-context reasoning capability of LLMs via an explicit two-stage procedure, i.e., aligning LLMs with the objectives of both retrieval and reasoning. We demonstrate the efficacy of ALR$^2$ for mitigating performance degradation in long-context reasoning tasks. Through extensive experiments on long-context QA benchmarks, we find our method to outperform competitive baselines by large margins, achieving at least 8.4 and 7.9 EM gains on the long-context versions of HotpotQA and SQuAD datasets, respectively.
Mintaka: A Complex, Natural, and Multilingual Dataset for End-to-End Question Answering
Oct 04, 2022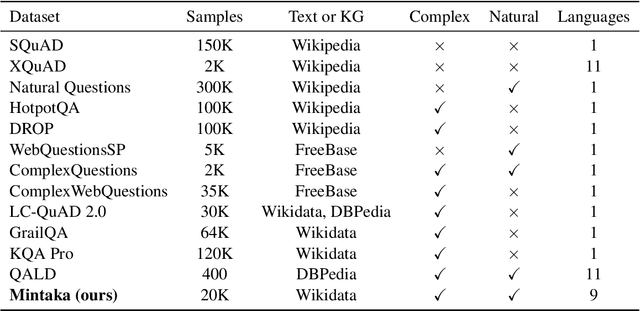
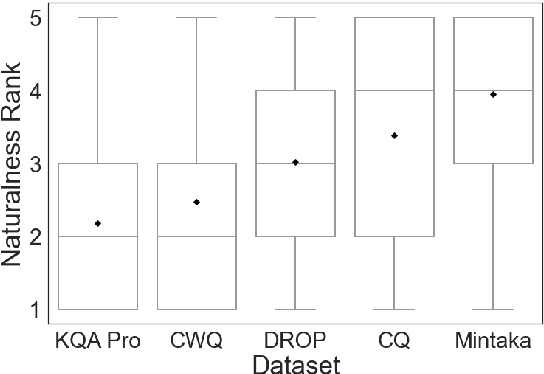

We introduce Mintaka, a complex, natural, and multilingual dataset designed for experimenting with end-to-end question-answering models. Mintaka is composed of 20,000 question-answer pairs collected in English, annotated with Wikidata entities, and translated into Arabic, French, German, Hindi, Italian, Japanese, Portuguese, and Spanish for a total of 180,000 samples. Mintaka includes 8 types of complex questions, including superlative, intersection, and multi-hop questions, which were naturally elicited from crowd workers. We run baselines over Mintaka, the best of which achieves 38% hits@1 in English and 31% hits@1 multilingually, showing that existing models have room for improvement. We release Mintaka at https://github.com/amazon-research/mintaka.
End-to-End Entity Resolution and Question Answering Using Differentiable Knowledge Graphs
Sep 13, 2021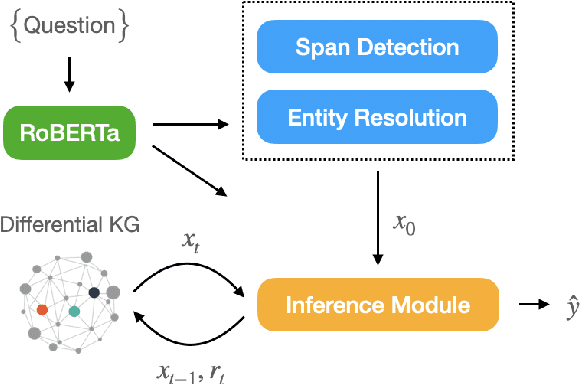
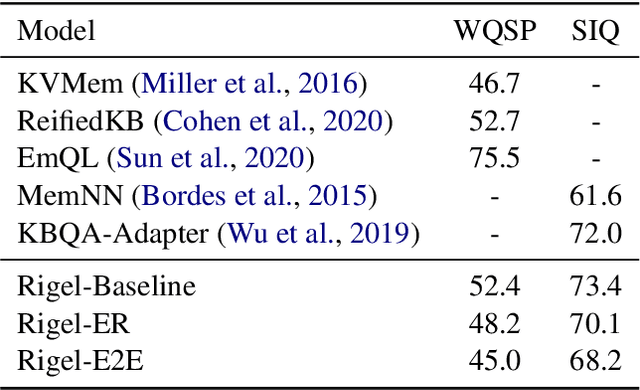

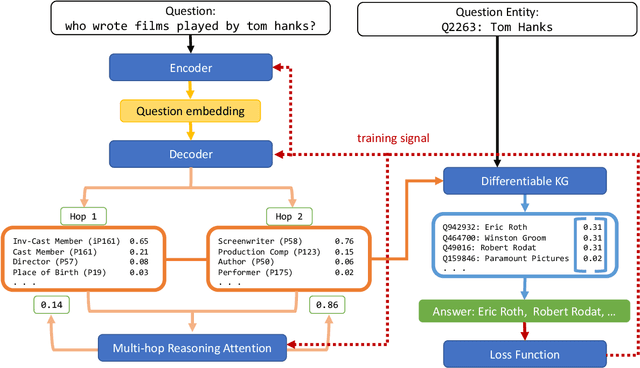
Recently, end-to-end (E2E) trained models for question answering over knowledge graphs (KGQA) have delivered promising results using only a weakly supervised dataset. However, these models are trained and evaluated in a setting where hand-annotated question entities are supplied to the model, leaving the important and non-trivial task of entity resolution (ER) outside the scope of E2E learning. In this work, we extend the boundaries of E2E learning for KGQA to include the training of an ER component. Our model only needs the question text and the answer entities to train, and delivers a stand-alone QA model that does not require an additional ER component to be supplied during runtime. Our approach is fully differentiable, thanks to its reliance on a recent method for building differentiable KGs (Cohen et al., 2020). We evaluate our E2E trained model on two public datasets and show that it comes close to baseline models that use hand-annotated entities.
Expanding End-to-End Question Answering on Differentiable Knowledge Graphs with Intersection
Sep 13, 2021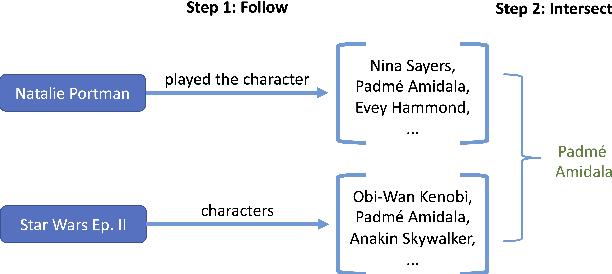
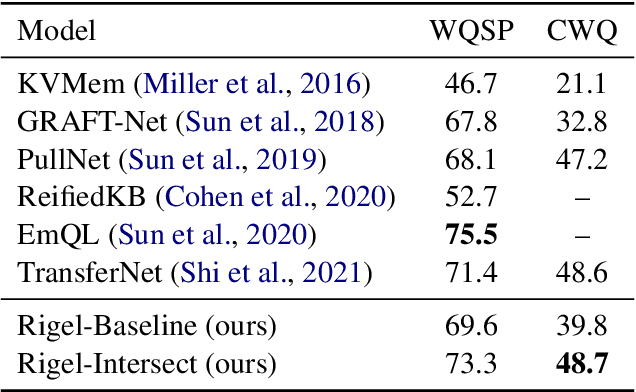
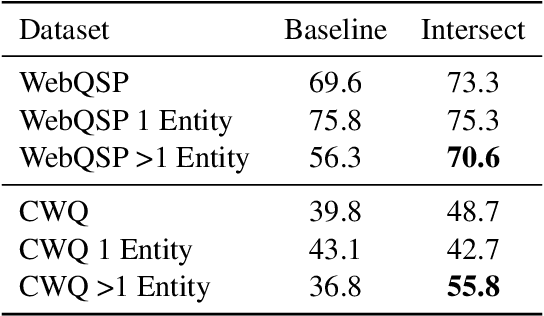
End-to-end question answering using a differentiable knowledge graph is a promising technique that requires only weak supervision, produces interpretable results, and is fully differentiable. Previous implementations of this technique (Cohen et al., 2020) have focused on single-entity questions using a relation following operation. In this paper, we propose a model that explicitly handles multiple-entity questions by implementing a new intersection operation, which identifies the shared elements between two sets of entities. We find that introducing intersection improves performance over a baseline model on two datasets, WebQuestionsSP (69.6% to 73.3% Hits@1) and ComplexWebQuestions (39.8% to 48.7% Hits@1), and in particular, improves performance on questions with multiple entities by over 14% on WebQuestionsSP and by 19% on ComplexWebQuestions.
What do Models Learn from Question Answering Datasets?
Apr 07, 2020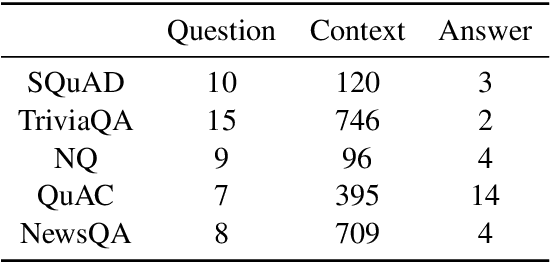
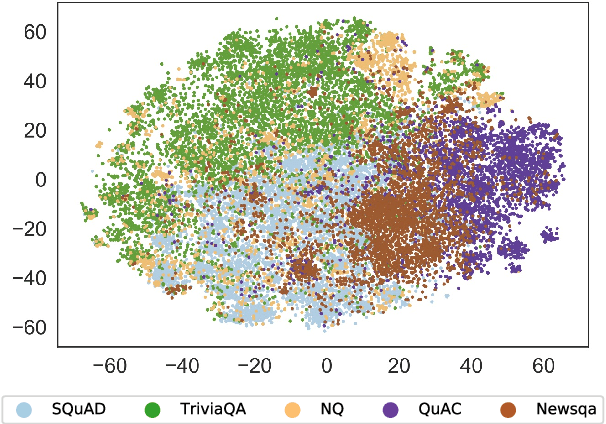
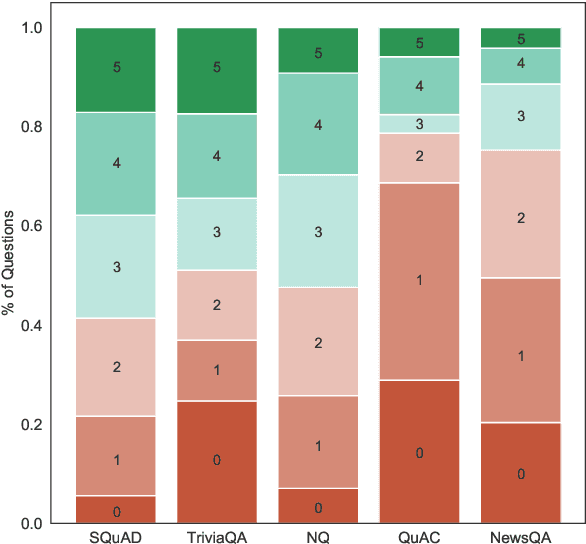
While models have reached superhuman performance on popular question answering (QA) datasets such as SQuAD, they have yet to outperform humans on the task of question answering itself. In this paper, we investigate what models are really learning from QA datasets by evaluating BERT-based models across five popular QA datasets. We evaluate models on their generalizability to out-of-domain examples, responses to missing or incorrect information in datasets, and ability to handle variations in questions. We find that no single dataset is robust to all of our experiments and identify shortcomings in both datasets and evaluation methods. Following our analysis, we make recommendations for building future QA datasets that better evaluate the task of question answering.