 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cherry-Picking Approach to Large Load Shaping for More Effective Carbon Reduction
Jan 25, 2026Shaping multi-megawatt loads, such as data centers, impacts generator dispatch on the electric grid, which in turn affects system CO2 emissions and energy cost. Substantiating the effectiveness of prevalent load shaping strategies, such as those based on grid-level average carbon intensity, locational marginal price, or marginal emissions, is challenging due to the lack of detailed counterfactual data required for accurate attribution. This study uses a series of calibrated granular ERCOT day-ahead direct current optimal power flow (DC-OPF) simulations for counterfactual analysis of a broad set of load shaping strategies on grid CO2 emissions and cost of electricity. In terms of annual grid level CO2 emissions reductions, LMP-based shaping outperforms other common strategies, but can be significantly improved upon. Examining the performance of practicable strategies under different grid conditions motivates a more effective load shaping approach: one that "cherry-picks" a daily strategy based on observable grid signals and historical data. The cherry-picking approach to power load shaping is applicable to any large flexible consumer on the electricity grid, such as data centers, distributed energy resources and Virtual Power Plants (VPPs).
METAL: Towards Multilingual Meta-Evaluation
Apr 02, 2024



With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
Are Large Language Model-based Evaluators the Solution to Scaling Up Multilingual Evaluation?
Sep 14, 2023



Large Language Models (LLMs) have demonstrated impressive performance on Natural Language Processing (NLP) tasks, such as Question Answering, Summarization, and Classification. The use of LLMs as evaluators, that can rank or score the output of other models (usually LLMs) has become increasingly popular, due to the limitations of current evaluation techniques including the lack of appropriate benchmarks, metrics, cost, and access to human annotators. While LLMs are capable of handling approximately 100 languages, the majority of languages beyond the top 20 lack systematic evaluation across various tasks, metrics, and benchmarks. This creates an urgent need to scale up multilingual evaluation to ensure a precise understanding of LLM performance across diverse languages. LLM-based evaluators seem like the perfect solution to this problem, as they do not require human annotators, human-created references, or benchmarks and can theoretically be used to evaluate any language covered by the LLM. In this paper, we investigate whether LLM-based evaluators can help scale up multilingual evaluation. Specifically, we calibrate LLM-based evaluation against 20k human judgments of five metrics across three text-generation tasks in eight languages. Our findings indicate that LLM-based evaluators may exhibit bias towards higher scores and should be used with caution and should always be calibrated with a dataset of native speaker judgments, particularly in low-resource and non-Latin script languages.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022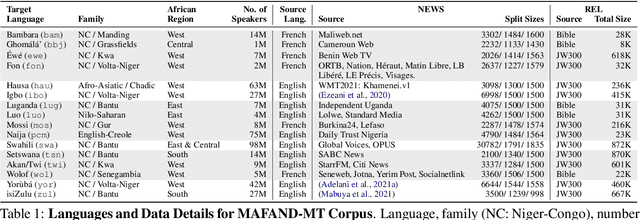
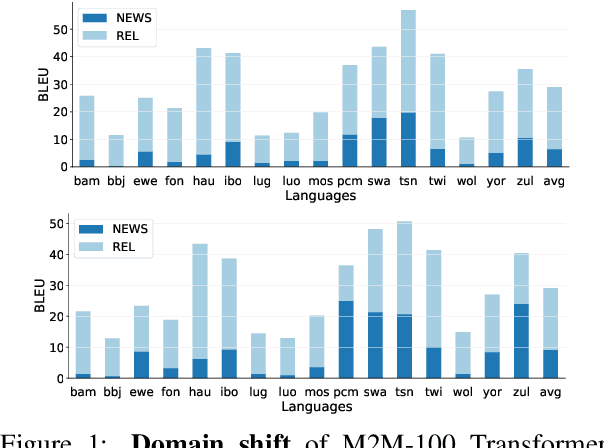

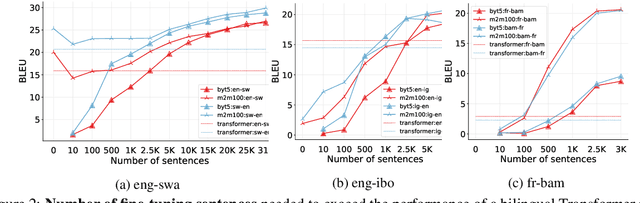
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.
Molecular representation learning with language models and domain-relevant auxiliary tasks
Nov 26, 2020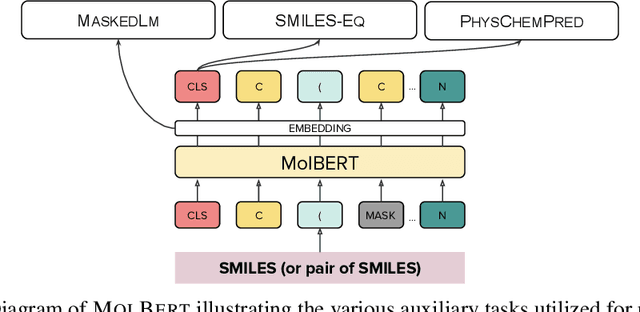

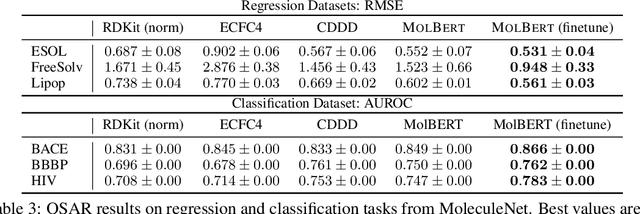
We apply a Transformer architecture, specifically BERT, to learn flexible and high quality molecular representations for drug discovery problems. We study the impact of using different combinations of self-supervised tasks for pre-training, and present our results for the established Virtual Screening and QSAR benchmarks. We show that: i) The selection of appropriate self-supervised task(s) for pre-training has a significant impact on performance in subsequent downstream tasks such as Virtual Screening. ii) Using auxiliary tasks with more domain relevance for Chemistry, such as learning to predict calculated molecular properties, increases the fidelity of our learnt representations. iii) Finally, we show that molecular representations learnt by our model `MolBert' improve upon the current state of the art on the benchmark datasets.
DEFactor: Differentiable Edge Factorization-based Probabilistic Graph Generation
Nov 24, 2018
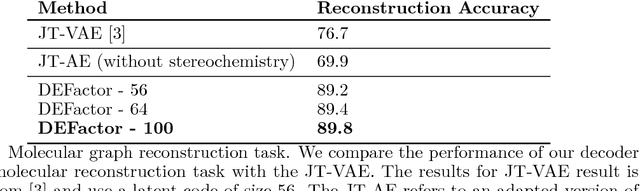
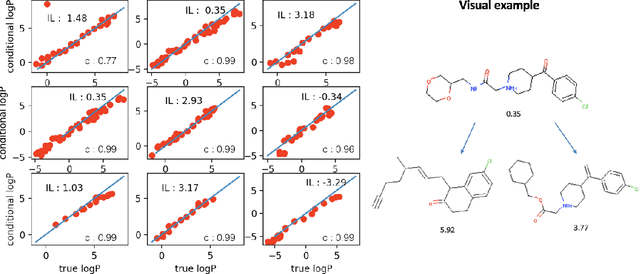
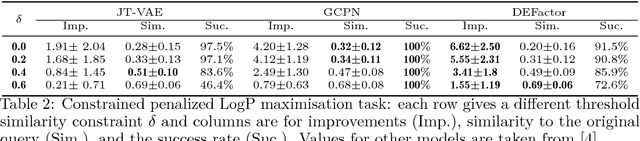
Generating novel molecules with optimal properties is a crucial step in many industries such as drug discovery. Recently, deep generative models have shown a promising way of performing de-novo molecular design. Although graph generative models are currently available they either have a graph size dependency in their number of parameters, limiting their use to only very small graphs or are formulated as a sequence of discrete actions needed to construct a graph, making the output graph non-differentiable w.r.t the model parameters, therefore preventing them to be used in scenarios such as conditional graph generation. In this work we propose a model for conditional graph generation that is computationally efficient and enables direct optimisation of the graph. We demonstrate favourable performance of our model on prototype-based molecular graph conditional generation tasks.
Learning Convolutional Neural Networks for Graphs
Jun 08, 2016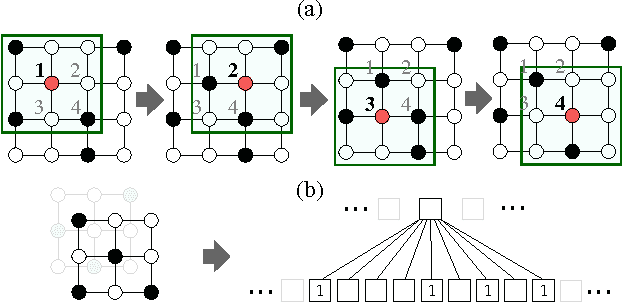
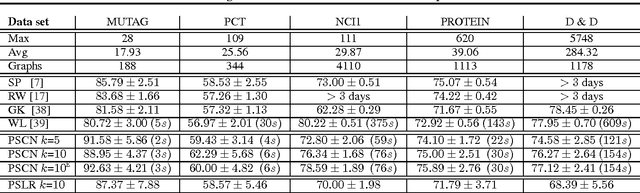
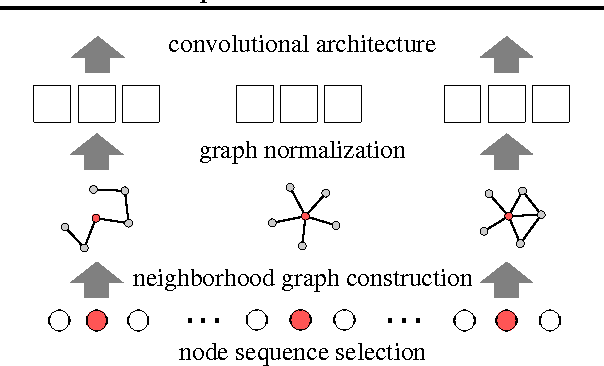
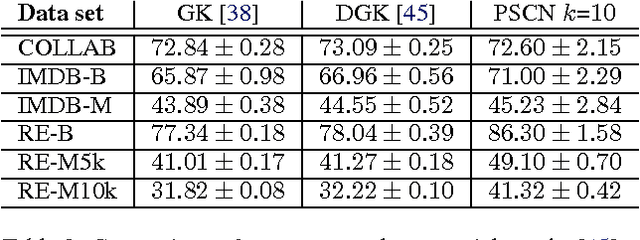
Numerous important problems can be framed as learning from graph data. We propose a framework for learning convolutional neural networks for arbitrary graphs. These graphs may be undirected, directed, and with both discrete and continuous node and edge attributes. Analogous to image-based convolutional networks that operate on locally connected regions of the input, we present a general approach to extracting locally connected regions from graphs. Using established benchmark data sets, we demonstrate that the learned feature representations are competitive with state of the art graph kernels and that their computation is highly efficient.