 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Hrunting of AI: Where and How to Improve English Dialectal Fairness
Mar 16, 2026It is known that large language models (LLMs) underperform in English dialects, and that improving them is difficult due to data scarcity. In this work we investigate how quality and availability impact the feasibility of improving LLMs in this context. For this, we evaluate three rarely-studied English dialects (Yorkshire, Geordie, and Cornish), plus African-American Vernacular English, and West Frisian as control. We find that human-human agreement when determining LLM generation quality directly impacts LLM-as-a-judge performance. That is, LLM-human agreement mimics the human-human agreement pattern, and so do metrics such as accuracy. It is an issue because LLM-human agreement measures an LLM's alignment with the human consensus; and hence raises questions about the feasibility of improving LLM performance in locales where low populations induce low agreement. We also note that fine-tuning does not eradicate, and might amplify, this pattern in English dialects. But also find encouraging signals, such as some LLMs' ability to generate high-quality data, thus enabling scalability. We argue that data must be carefully evaluated to ensure fair and inclusive LLM improvement; and, in the presence of scarcity, new tools are needed to handle the pattern found.
Causal Reasoning Favors Encoders: On The Limits of Decoder-Only Models
Dec 11, 2025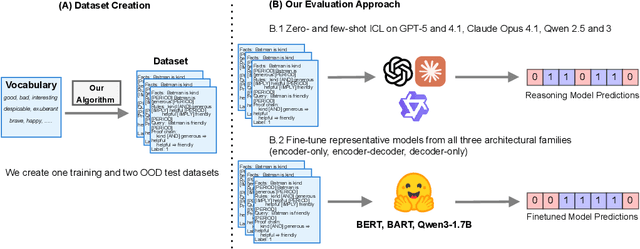



In context learning (ICL) underpins recent advances in large language models (LLMs), although its role and performance in causal reasoning remains unclear. Causal reasoning demands multihop composition and strict conjunctive control, and reliance on spurious lexical relations of the input could provide misleading results. We hypothesize that, due to their ability to project the input into a latent space, encoder and encoder decoder architectures are better suited for said multihop conjunctive reasoning versus decoder only models. To do this, we compare fine-tuned versions of all the aforementioned architectures with zero and few shot ICL in both natural language and non natural language scenarios. We find that ICL alone is insufficient for reliable causal reasoning, often overfocusing on irrelevant input features. In particular, decoder only models are noticeably brittle to distributional shifts, while finetuned encoder and encoder decoder models can generalize more robustly across our tests, including the non natural language split. Both architectures are only matched or surpassed by decoder only architectures at large scales. We conclude by noting that for cost effective, short horizon robust causal reasoning, encoder or encoder decoder architectures with targeted finetuning are preferable.
Evaluating Style-Personalized Text Generation: Challenges and Directions
Aug 08, 2025While prior research has built tools and benchmarks towards style personalized text generation, there has been limited exploration of evaluation in low-resource author style personalized text generation space. Through this work, we question the effectiveness of the widely adopted evaluation metrics like BLEU and ROUGE, and explore other evaluation paradigms such as style embeddings and LLM-as-judge to holistically evaluate the style personalized text generation task. We evaluate these metrics and their ensembles using our style discrimination benchmark, that spans eight writing tasks, and evaluates across three settings, domain discrimination, authorship attribution, and LLM personalized vs non-personalized discrimination. We provide conclusive evidence to adopt ensemble of diverse evaluation metrics to effectively evaluate style personalized text generation.
The Thin Line Between Comprehension and Persuasion in LLMs
Jul 02, 2025Large language models (LLMs) are excellent at maintaining high-level, convincing dialogues. They are being fast deployed as chatbots and evaluators in sensitive areas, such as peer review and mental health applications. This, along with the disparate accounts on their reasoning capabilities, calls for a closer examination of LLMs and their comprehension of dialogue. In this work we begin by evaluating LLMs' ability to maintain a debate--one of the purest yet most complex forms of human communication. Then we measure how this capability relates to their understanding of what is being talked about, namely, their comprehension of dialogical structures and the pragmatic context. We find that LLMs are capable of maintaining coherent, persuasive debates, often swaying the beliefs of participants and audiences alike. We also note that awareness or suspicion of AI involvement encourage people to be more critical of the arguments made. When polling LLMs on their comprehension of deeper structures of dialogue, however, they cannot demonstrate said understanding. Our findings tie the shortcomings of LLMs-as-evaluators to their (in)ability to understand the context. More broadly, for the field of argumentation theory we posit that, if an agent can convincingly maintain a dialogue, it is not necessary for it to know what it is talking about. Hence, the modelling of pragmatic context and coherence are secondary to effectiveness.
A Multilingual, Culture-First Approach to Addressing Misgendering in LLM Applications
Mar 26, 2025Misgendering is the act of referring to someone by a gender that does not match their chosen identity. It marginalizes and undermines a person's sense of self, causing significant harm. English-based approaches have clear-cut approaches to avoiding misgendering, such as the use of the pronoun ``they''. However, other languages pose unique challenges due to both grammatical and cultural constructs. In this work we develop methodologies to assess and mitigate misgendering across 42 languages and dialects using a participatory-design approach to design effective and appropriate guardrails across all languages. We test these guardrails in a standard large language model-based application (meeting transcript summarization), where both the data generation and the annotation steps followed a human-in-the-loop approach. We find that the proposed guardrails are very effective in reducing misgendering rates across all languages in the summaries generated, and without incurring loss of quality. Our human-in-the-loop approach demonstrates a method to feasibly scale inclusive and responsible AI-based solutions across multiple languages and cultures.
If Eleanor Rigby Had Met ChatGPT: A Study on Loneliness in a Post-LLM World
Dec 02, 2024



Loneliness, or the lack of fulfilling relationships, significantly impacts a person's mental and physical well-being and is prevalent worldwide. Previous research suggests that large language models (LLMs) may help mitigate loneliness. However, we argue that the use of widespread LLMs like ChatGPT is more prevalent--and riskier, as they are not designed for this purpose. To explore this, we analysed user interactions with ChatGPT, particularly those outside of its marketed use as task-oriented assistant. In dialogues classified as lonely, users frequently (37%) sought advice or validation, and received good engagement. However, ChatGPT failed in sensitive scenarios, like responding appropriately to suicidal ideation or trauma. We also observed a 35% higher incidence of toxic content, with women being 22 times more likely to be targeted than men. Our findings underscore ethical and legal questions about this technology, and note risks like radicalisation or further isolation. We conclude with recommendations for research and industry to address loneliness.
One Language, Many Gaps: Evaluating Dialect Fairness and Robustness of Large Language Models in Reasoning Tasks
Oct 14, 2024


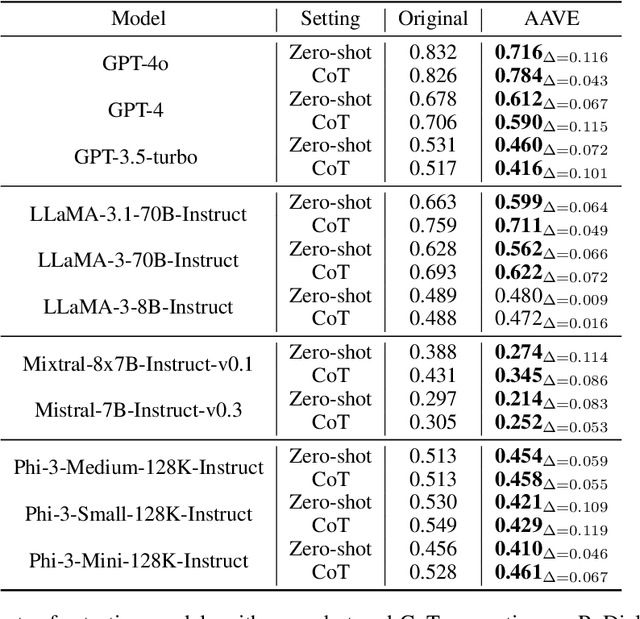
Language is not monolithic. While many benchmarks are used as proxies to systematically estimate Large Language Models' (LLM) performance in real-life tasks, they tend to ignore the nuances of within-language variation and thus fail to model the experience of speakers of minority dialects. Focusing on African American Vernacular English (AAVE), we present the first study on LLMs' fairness and robustness to a dialect in canonical reasoning tasks (algorithm, math, logic, and comprehensive reasoning). We hire AAVE speakers, including experts with computer science backgrounds, to rewrite seven popular benchmarks, such as HumanEval and GSM8K. The result of this effort is ReDial, a dialectal benchmark comprising $1.2K+$ parallel query pairs in Standardized English and AAVE. We use ReDial to evaluate state-of-the-art LLMs, including GPT-4o/4/3.5-turbo, LLaMA-3.1/3, Mistral, and Phi-3. We find that, compared to Standardized English, almost all of these widely used models show significant brittleness and unfairness to queries in AAVE. Furthermore, AAVE queries can degrade performance more substantially than misspelled texts in Standardized English, even when LLMs are more familiar with the AAVE queries. Finally, asking models to rephrase questions in Standardized English does not close the performance gap but generally introduces higher costs. Overall, our findings indicate that LLMs provide unfair service to dialect users in complex reasoning tasks. Code can be found at https://github.com/fangru-lin/redial_dialect_robustness_fairness.git.
Awes, Laws, and Flaws From Today's LLM Research
Aug 29, 2024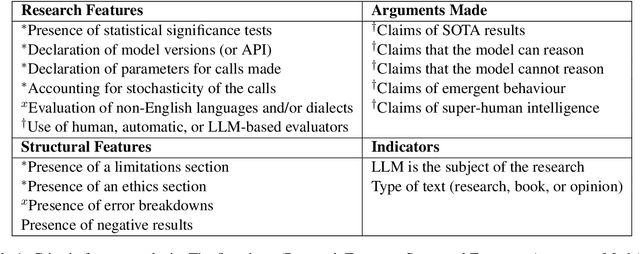
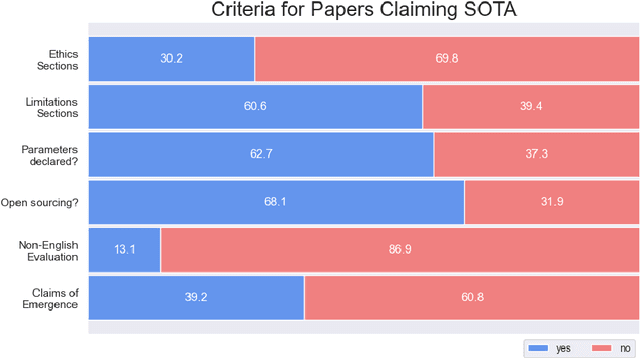
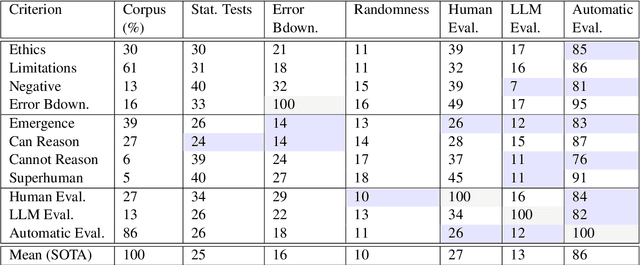

We perform a critical examination of the scientific methodology behind contemporary large language model (LLM) research. For this we assess over 2,000 research works based on criteria typical of what is considered good research (e.g. presence of statistical tests and reproducibility) and cross-validate it with arguments that are at the centre of controversy (e.g., claims of emergent behaviour, the use of LLMs as evaluators). We find multiple trends, such as declines in claims of emergent behaviour and ethics disclaimers; the rise of LLMs as evaluators in spite of a lack of consensus from the community about their useability; and an increase of claims of LLM reasoning abilities, typically without leveraging human evaluation. This paper underscores the need for more scrutiny and rigour by and from this field to live up to the fundamentals of a responsible scientific method that is ethical, reproducible, systematic, and open to criticism.
RTP-LX: Can LLMs Evaluate Toxicity in Multilingual Scenarios?
Apr 22, 2024



Large language models (LLMs) and small language models (SLMs) are being adopted at remarkable speed, although their safety still remains a serious concern. With the advent of multilingual S/LLMs, the question now becomes a matter of scale: can we expand multilingual safety evaluations of these models with the same velocity at which they are deployed? To this end we introduce RTP-LX, a human-transcreated and human-annotated corpus of toxic prompts and outputs in 28 languages. RTP-LX follows participatory design practices, and a portion of the corpus is especially designed to detect culturally-specific toxic language. We evaluate seven S/LLMs on their ability to detect toxic content in a culturally-sensitive, multilingual scenario. We find that, although they typically score acceptably in terms of accuracy, they have low agreement with human judges when judging holistically the toxicity of a prompt, and have difficulty discerning harm in context-dependent scenarios, particularly with subtle-yet-harmful content (e.g. microagressions, bias). We release of this dataset to contribute to further reduce harmful uses of these models and improve their safe deployment.
LLM as a Mastermind: A Survey of Strategic Reasoning with Large Language Models
Apr 01, 2024



This paper presents a comprehensive survey of the current status and opportunities for Large Language Models (LLMs) in strategic reasoning, a sophisticated form of reasoning that necessitates understanding and predicting adversary actions in multi-agent settings while adjusting strategies accordingly. Strategic reasoning is distinguished by its focus on the dynamic and uncertain nature of interactions among multi-agents, where comprehending the environment and anticipating the behavior of others is crucial. We explore the scopes, applications, methodologies, and evaluation metrics related to strategic reasoning with LLMs, highlighting the burgeoning development in this area and the interdisciplinary approaches enhancing their decision-making performance. It aims to systematize and clarify the scattered literature on this subject, providing a systematic review that underscores the importance of strategic reasoning as a critical cognitive capability and offers insights into future research directions and potential improvements.