 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAwes, Laws, and Flaws From Today's LLM Research
Paper and Code
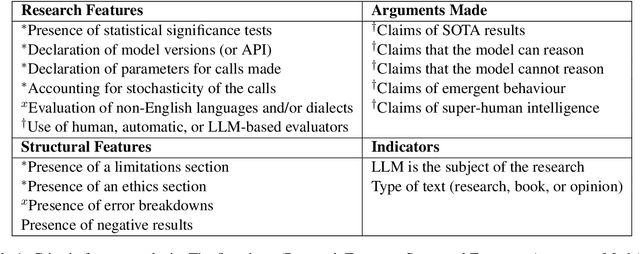
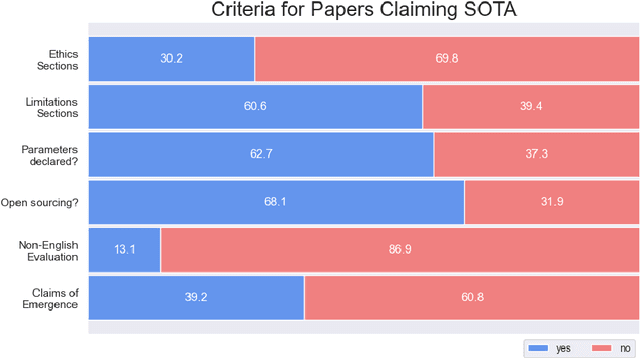
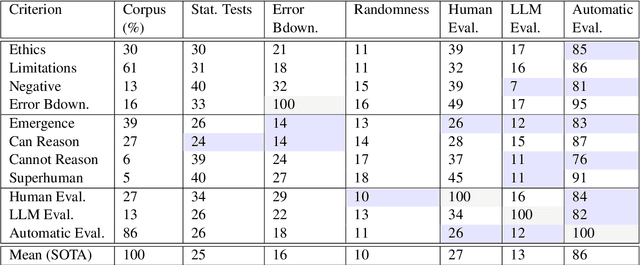

We perform a critical examination of the scientific methodology behind contemporary large language model (LLM) research. For this we assess over 2,000 research works based on criteria typical of what is considered good research (e.g. presence of statistical tests and reproducibility) and cross-validate it with arguments that are at the centre of controversy (e.g., claims of emergent behaviour, the use of LLMs as evaluators). We find multiple trends, such as declines in claims of emergent behaviour and ethics disclaimers; the rise of LLMs as evaluators in spite of a lack of consensus from the community about their useability; and an increase of claims of LLM reasoning abilities, typically without leveraging human evaluation. This paper underscores the need for more scrutiny and rigour by and from this field to live up to the fundamentals of a responsible scientific method that is ethical, reproducible, systematic, and open to criticism.