 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multilingual, Culture-First Approach to Addressing Misgendering in LLM Applications
Mar 26, 2025Misgendering is the act of referring to someone by a gender that does not match their chosen identity. It marginalizes and undermines a person's sense of self, causing significant harm. English-based approaches have clear-cut approaches to avoiding misgendering, such as the use of the pronoun ``they''. However, other languages pose unique challenges due to both grammatical and cultural constructs. In this work we develop methodologies to assess and mitigate misgendering across 42 languages and dialects using a participatory-design approach to design effective and appropriate guardrails across all languages. We test these guardrails in a standard large language model-based application (meeting transcript summarization), where both the data generation and the annotation steps followed a human-in-the-loop approach. We find that the proposed guardrails are very effective in reducing misgendering rates across all languages in the summaries generated, and without incurring loss of quality. Our human-in-the-loop approach demonstrates a method to feasibly scale inclusive and responsible AI-based solutions across multiple languages and cultures.
RTP-LX: Can LLMs Evaluate Toxicity in Multilingual Scenarios?
Apr 22, 2024



Large language models (LLMs) and small language models (SLMs) are being adopted at remarkable speed, although their safety still remains a serious concern. With the advent of multilingual S/LLMs, the question now becomes a matter of scale: can we expand multilingual safety evaluations of these models with the same velocity at which they are deployed? To this end we introduce RTP-LX, a human-transcreated and human-annotated corpus of toxic prompts and outputs in 28 languages. RTP-LX follows participatory design practices, and a portion of the corpus is especially designed to detect culturally-specific toxic language. We evaluate seven S/LLMs on their ability to detect toxic content in a culturally-sensitive, multilingual scenario. We find that, although they typically score acceptably in terms of accuracy, they have low agreement with human judges when judging holistically the toxicity of a prompt, and have difficulty discerning harm in context-dependent scenarios, particularly with subtle-yet-harmful content (e.g. microagressions, bias). We release of this dataset to contribute to further reduce harmful uses of these models and improve their safe deployment.
On Meta-Prompting
Dec 11, 2023
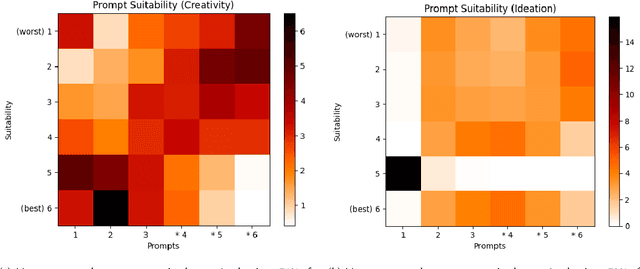
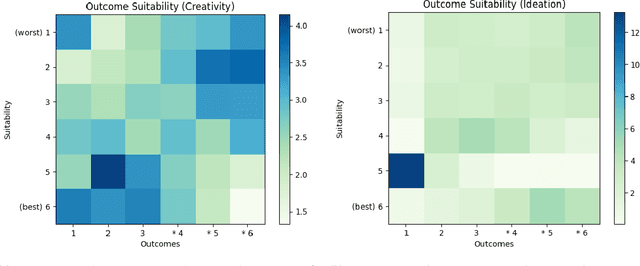
Certain statistical models are capable of interpreting input strings as instructions, or prompts, and carry out tasks based on them. Many approaches to prompting and pre-training these models involve the automated generation of these prompts. We call these approaches meta-prompting, or prompting to obtain prompts. We propose a theoretical framework based on category theory to generalize and describe them. This framework is flexible enough to account for LLM stochasticity; and allows us to obtain formal results around task agnosticity and equivalence of various meta-prompting approaches. We experiment with meta-prompting in two active areas of model research: creativity and ideation. We find that user preference favors (p < 0.01) the prompts generated under meta-prompting, as well as their corresponding outputs, over a series of hardcoded baseline prompts that include the original task prompt. Using our framework, we argue that meta-prompting is more effective than basic prompting at generating desirable outputs.
An Evaluation on Large Language Model Outputs: Discourse and Memorization
Apr 17, 2023We present an empirical evaluation of various outputs generated by nine of the most widely-available large language models (LLMs). Our analysis is done with off-the-shelf, readily-available tools. We find a correlation between percentage of memorized text, percentage of unique text, and overall output quality, when measured with respect to output pathologies such as counterfactual and logically-flawed statements, and general failures like not staying on topic. Overall, 80.0% of the outputs evaluated contained memorized data, but outputs containing the most memorized content were also more likely to be considered of high quality. We discuss and evaluate mitigation strategies, showing that, in the models evaluated, the rate of memorized text being output is reduced. We conclude with a discussion on potential implications around what it means to learn, to memorize, and to evaluate quality text.
Incremental user embedding modeling for personalized text classification
Feb 13, 2022
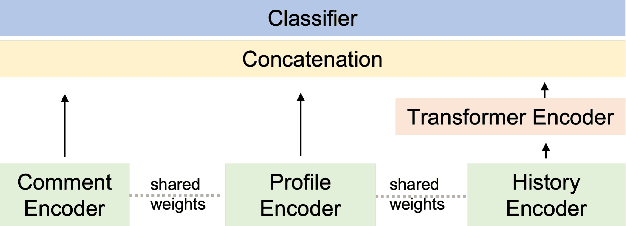


Individual user profiles and interaction histories play a significant role in providing customized experiences in real-world applications such as chatbots, social media, retail, and education. Adaptive user representation learning by utilizing user personalized information has become increasingly challenging due to ever-growing history data. In this work, we propose an incremental user embedding modeling approach, in which embeddings of user's recent interaction histories are dynamically integrated into the accumulated history vectors via a transformer encoder. This modeling paradigm allows us to create generalized user representations in a consecutive manner and also alleviate the challenges of data management. We demonstrate the effectiveness of this approach by applying it to a personalized multi-class classification task based on the Reddit dataset, and achieve 9% and 30% relative improvement on prediction accuracy over a baseline system for two experiment settings through appropriate comment history encoding and task modeling.
Random Quadratic Forms with Dependence: Applications to Restricted Isometry and Beyond
Oct 11, 2019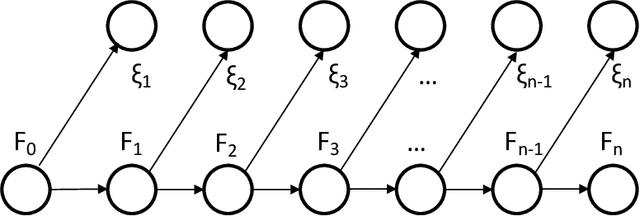


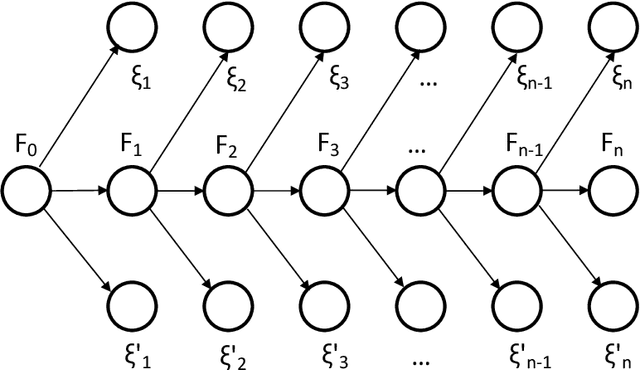
Several important families of computational and statistical results in machine learning and randomized algorithms rely on uniform bounds on quadratic forms of random vectors or matrices. Such results include the Johnson-Lindenstrauss (J-L) Lemma, the Restricted Isometry Property (RIP), randomized sketching algorithms, and approximate linear algebra. The existing results critically depend on statistical independence, e.g., independent entries for random vectors, independent rows for random matrices, etc., which prevent their usage in dependent or adaptive modeling settings. In this paper, we show that such independence is in fact not needed for such results which continue to hold under fairly general dependence structures. In particular, we present uniform bounds on random quadratic forms of stochastic processes which are conditionally independent and sub-Gaussian given another (latent) process. Our setup allows general dependencies of the stochastic process on the history of the latent process and the latent process to be influenced by realizations of the stochastic process. The results are thus applicable to adaptive modeling settings and also allows for sequential design of random vectors and matrices. We also discuss stochastic process based forms of J-L, RIP, and sketching, to illustrate the generality of the results.
Hessian based analysis of SGD for Deep Nets: Dynamics and Generalization
Jul 24, 2019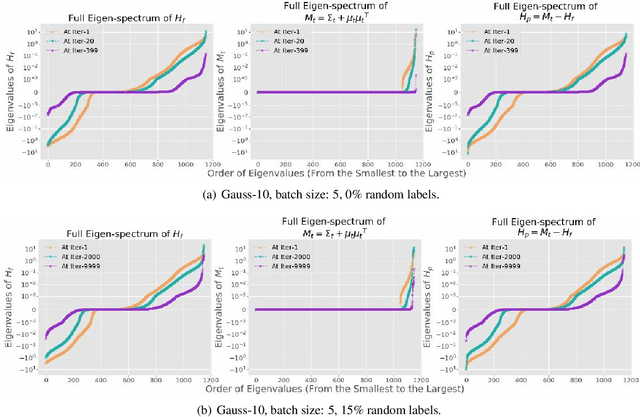
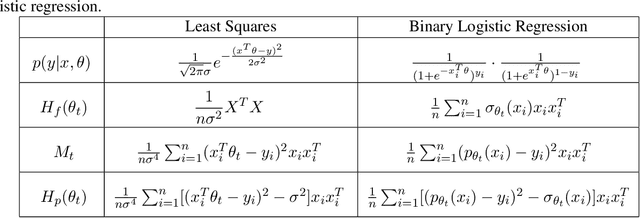
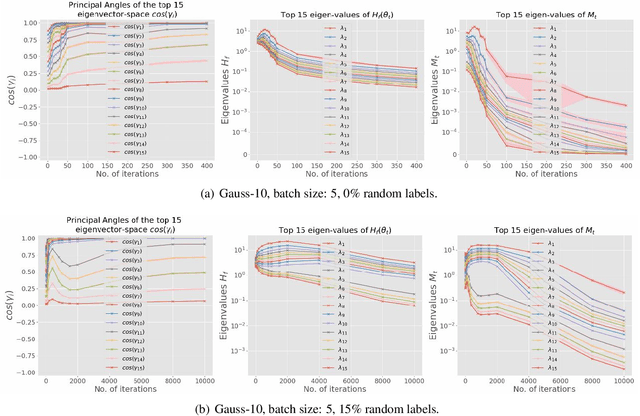
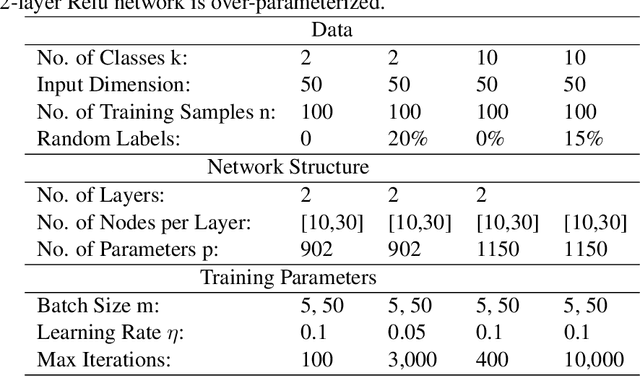
While stochastic gradient descent (SGD) and variants have been surprisingly successful for training deep nets, several aspects of the optimization dynamics and generalization are still not well understood. In this paper, we present new empirical observations and theoretical results on both the optimization dynamics and generalization behavior of SGD for deep nets based on the Hessian of the training loss and associated quantities. We consider three specific research questions: (1) what is the relationship between the Hessian of the loss and the second moment of stochastic gradients (SGs)? (2) how can we characterize the stochastic optimization dynamics of SGD with fixed and adaptive step sizes and diagonal pre-conditioning based on the first and second moments of SGs? and (3) how can we characterize a scale-invariant generalization bound of deep nets based on the Hessian of the loss, which by itself is not scale invariant? We shed light on these three questions using theoretical results supported by extensive empirical observations, with experiments on synthetic data, MNIST, and CIFAR-10, with different batch sizes, and with different difficulty levels by synthetically adding random labels.
High Dimensional Structured Superposition Models
May 30, 2017

High dimensional superposition models characterize observations using parameters which can be written as a sum of multiple component parameters, each with its own structure, e.g., sum of low rank and sparse matrices, sum of sparse and rotated sparse vectors, etc. In this paper, we consider general superposition models which allow sum of any number of component parameters, and each component structure can be characterized by any norm. We present a simple estimator for such models, give a geometric condition under which the components can be accurately estimated, characterize sample complexity of the estimator, and give high probability non-asymptotic bounds on the componentwise estimation error. We use tools from empirical processes and generic chaining for the statistical analysis, and our results, which substantially generalize prior work on superposition models, are in terms of Gaussian widths of suitable sets.