 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Linear Contextual Bandits: A Sharp and Geometric Smoothed Analysis
Feb 26, 2020Bandit learning algorithms typically involve the balance of exploration and exploitation. However, in many practical applications, worst-case scenarios needing systematic exploration are seldom encountered. In this work, we consider a smoothed setting for structured linear contextual bandits where the adversarial contexts are perturbed by Gaussian noise and the unknown parameter $\theta^*$ has structure, e.g., sparsity, group sparsity, low rank, etc. We propose simple greedy algorithms for both the single- and multi-parameter (i.e., different parameter for each context) settings and provide a unified regret analysis for $\theta^*$ with any assumed structure. The regret bounds are expressed in terms of geometric quantities such as Gaussian widths associated with the structure of $\theta^*$. We also obtain sharper regret bounds compared to earlier work for the unstructured $\theta^*$ setting as a consequence of our improved analysis. We show there is implicit exploration in the smoothed setting where a simple greedy algorithm works.
Random Quadratic Forms with Dependence: Applications to Restricted Isometry and Beyond
Oct 11, 2019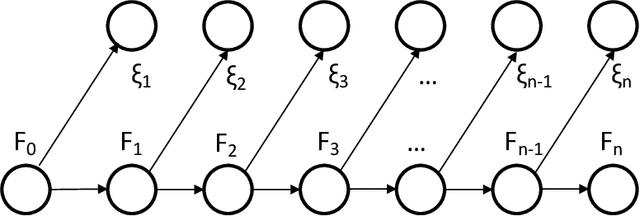


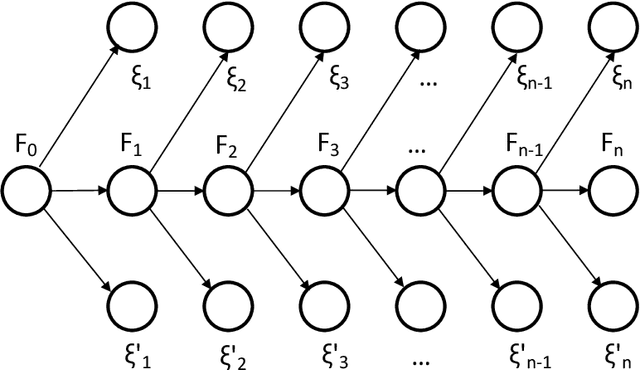
Several important families of computational and statistical results in machine learning and randomized algorithms rely on uniform bounds on quadratic forms of random vectors or matrices. Such results include the Johnson-Lindenstrauss (J-L) Lemma, the Restricted Isometry Property (RIP), randomized sketching algorithms, and approximate linear algebra. The existing results critically depend on statistical independence, e.g., independent entries for random vectors, independent rows for random matrices, etc., which prevent their usage in dependent or adaptive modeling settings. In this paper, we show that such independence is in fact not needed for such results which continue to hold under fairly general dependence structures. In particular, we present uniform bounds on random quadratic forms of stochastic processes which are conditionally independent and sub-Gaussian given another (latent) process. Our setup allows general dependencies of the stochastic process on the history of the latent process and the latent process to be influenced by realizations of the stochastic process. The results are thus applicable to adaptive modeling settings and also allows for sequential design of random vectors and matrices. We also discuss stochastic process based forms of J-L, RIP, and sketching, to illustrate the generality of the results.
Structured Stochastic Linear Bandits
Jun 17, 2016The stochastic linear bandit problem proceeds in rounds where at each round the algorithm selects a vector from a decision set after which it receives a noisy linear loss parameterized by an unknown vector. The goal in such a problem is to minimize the (pseudo) regret which is the difference between the total expected loss of the algorithm and the total expected loss of the best fixed vector in hindsight. In this paper, we consider settings where the unknown parameter has structure, e.g., sparse, group sparse, low-rank, which can be captured by a norm, e.g., $L_1$, $L_{(1,2)}$, nuclear norm. We focus on constructing confidence ellipsoids which contain the unknown parameter across all rounds with high-probability. We show the radius of such ellipsoids depend on the Gaussian width of sets associated with the norm capturing the structure. Such characterization leads to tighter confidence ellipsoids and, therefore, sharper regret bounds compared to bounds in the existing literature which are based on the ambient dimensionality.
Estimation with Norm Regularization
Nov 30, 2015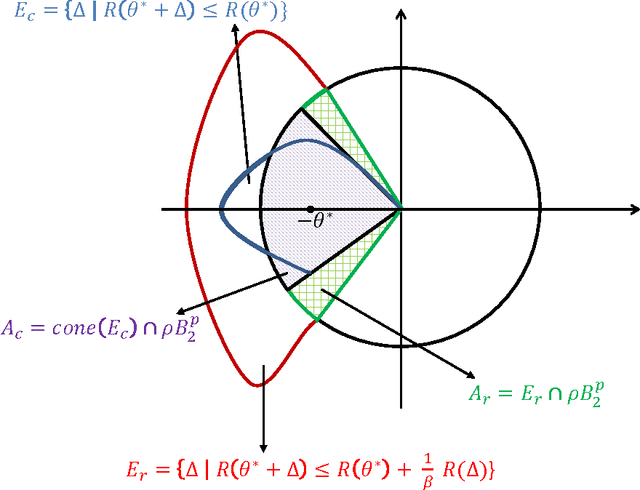
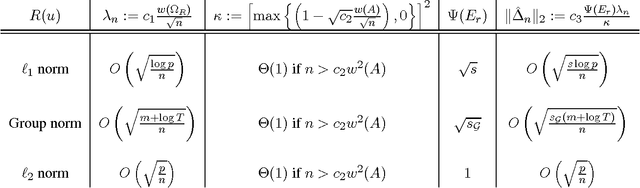
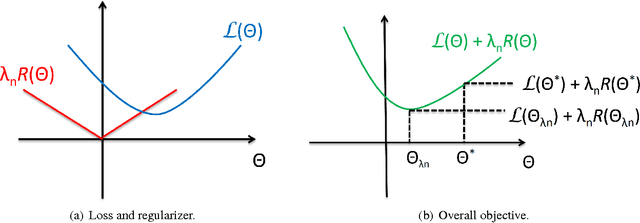
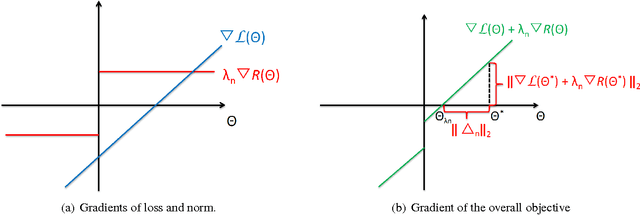
Analysis of non-asymptotic estimation error and structured statistical recovery based on norm regularized regression, such as Lasso, needs to consider four aspects: the norm, the loss function, the design matrix, and the noise model. This paper presents generalizations of such estimation error analysis on all four aspects compared to the existing literature. We characterize the restricted error set where the estimation error vector lies, establish relations between error sets for the constrained and regularized problems, and present an estimation error bound applicable to any norm. Precise characterizations of the bound is presented for isotropic as well as anisotropic subGaussian design matrices, subGaussian noise models, and convex loss functions, including least squares and generalized linear models. Generic chaining and associated results play an important role in the analysis. A key result from the analysis is that the sample complexity of all such estimators depends on the Gaussian width of a spherical cap corresponding to the restricted error set. Further, once the number of samples $n$ crosses the required sample complexity, the estimation error decreases as $\frac{c}{\sqrt{n}}$, where $c$ depends on the Gaussian width of the unit norm ball.
Multi-task Sparse Structure Learning
Sep 02, 2014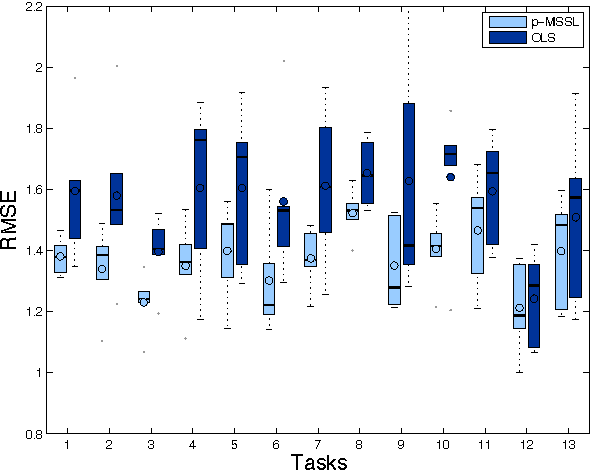

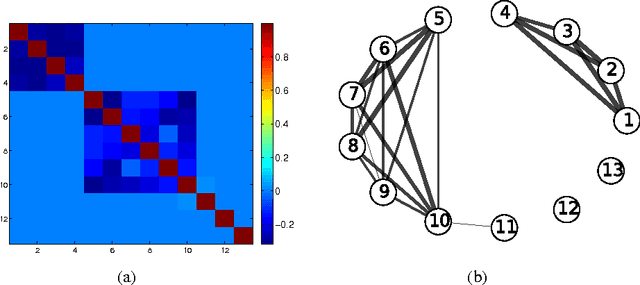

Multi-task learning (MTL) aims to improve generalization performance by learning multiple related tasks simultaneously. While sometimes the underlying task relationship structure is known, often the structure needs to be estimated from data at hand. In this paper, we present a novel family of models for MTL, applicable to regression and classification problems, capable of learning the structure of task relationships. In particular, we consider a joint estimation problem of the task relationship structure and the individual task parameters, which is solved using alternating minimization. The task relationship structure learning component builds on recent advances in structure learning of Gaussian graphical models based on sparse estimators of the precision (inverse covariance) matrix. We illustrate the effectiveness of the proposed model on a variety of synthetic and benchmark datasets for regression and classification. We also consider the problem of combining climate model outputs for better projections of future climate, with focus on temperature in South America, and show that the proposed model outperforms several existing methods for the problem.