 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Multi-Task Learning with Recursive Least Squares and Recursive Kernel Methods
Aug 03, 2023



This paper introduces two novel approaches for Online Multi-Task Learning (MTL) Regression Problems. We employ a high performance graph-based MTL formulation and develop its recursive versions based on the Weighted Recursive Least Squares (WRLS) and the Online Sparse Least Squares Support Vector Regression (OSLSSVR). Adopting task-stacking transformations, we demonstrate the existence of a single matrix incorporating the relationship of multiple tasks and providing structural information to be embodied by the MT-WRLS method in its initialization procedure and by the MT-OSLSSVR in its multi-task kernel function. Contrasting the existing literature, which is mostly based on Online Gradient Descent (OGD) or cubic inexact approaches, we achieve exact and approximate recursions with quadratic per-instance cost on the dimension of the input space (MT-WRLS) or on the size of the dictionary of instances (MT-OSLSSVR). We compare our online MTL methods to other contenders in a real-world wind speed forecasting case study, evidencing the significant gain in performance of both proposed approaches.
OFA$^2$: A Multi-Objective Perspective for the Once-for-All Neural Architecture Search
Mar 23, 2023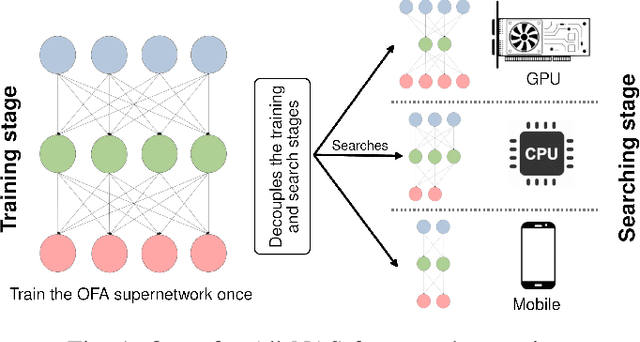
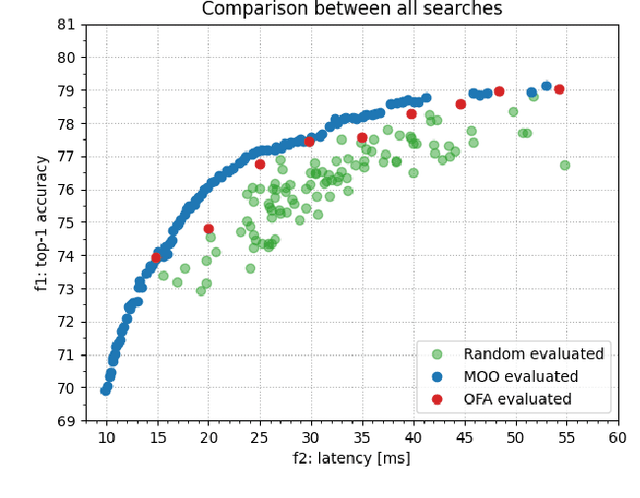
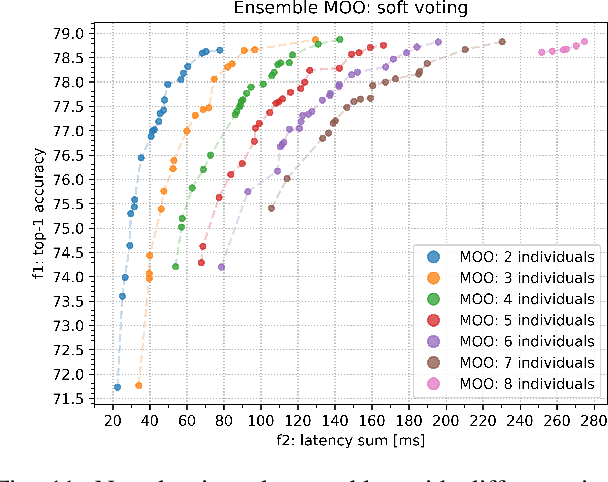
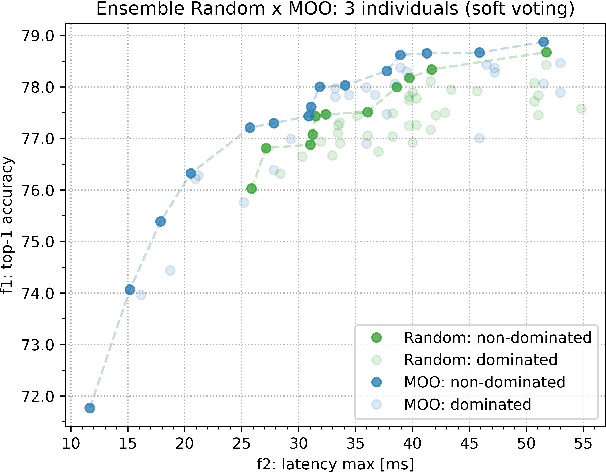
Once-for-All (OFA) is a Neural Architecture Search (NAS) framework designed to address the problem of searching efficient architectures for devices with different resources constraints by decoupling the training and the searching stages. The computationally expensive process of training the OFA neural network is done only once, and then it is possible to perform multiple searches for subnetworks extracted from this trained network according to each deployment scenario. In this work we aim to give one step further in the search for efficiency by explicitly conceiving the search stage as a multi-objective optimization problem. A Pareto frontier is then populated with efficient, and already trained, neural architectures exhibiting distinct trade-offs among the conflicting objectives. This could be achieved by using any multi-objective evolutionary algorithm during the search stage, such as NSGA-II and SMS-EMOA. In other words, the neural network is trained once, the searching for subnetworks considering different hardware constraints is also done one single time, and then the user can choose a suitable neural network according to each deployment scenario. The conjugation of OFA and an explicit algorithm for multi-objective optimization opens the possibility of a posteriori decision-making in NAS, after sampling efficient subnetworks which are a very good approximation of the Pareto frontier, given that those subnetworks are already trained and ready to use. The source code and the final search algorithm will be released at https://github.com/ito-rafael/once-for-all-2
New advances in enumerative biclustering algorithms with online partitioning
Mar 07, 2020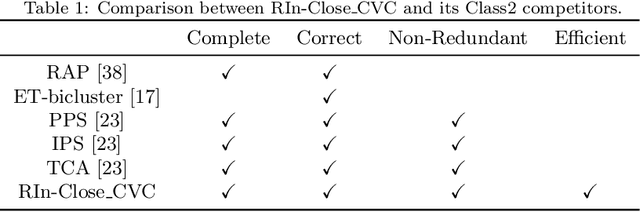


This paper further extends RIn-Close_CVC, a biclustering algorithm capable of performing an efficient, complete, correct and non-redundant enumeration of maximal biclusters with constant values on columns in numerical datasets. By avoiding a priori partitioning and itemization of the dataset, RIn-Close_CVC implements an online partitioning, which is demonstrated here to guide to more informative biclustering results. The improved algorithm is called RIn-Close_CVC3, keeps those attractive properties of RIn-Close_CVC, as formally proved here, and is characterized by: a drastic reduction in memory usage; a consistent gain in runtime; additional ability to handle datasets with missing values; and additional ability to operate with attributes characterized by distinct distributions or even mixed data types. The experimental results include synthetic and real-world datasets used to perform scalability and sensitivity analyses. As a practical case study, a parsimonious set of relevant and interpretable mixed-attribute-type rules is obtained in the context of supervised descriptive pattern mining.
RIn-Close_CVC2: an even more efficient enumerative algorithm for biclustering of numerical datasets
Oct 17, 2018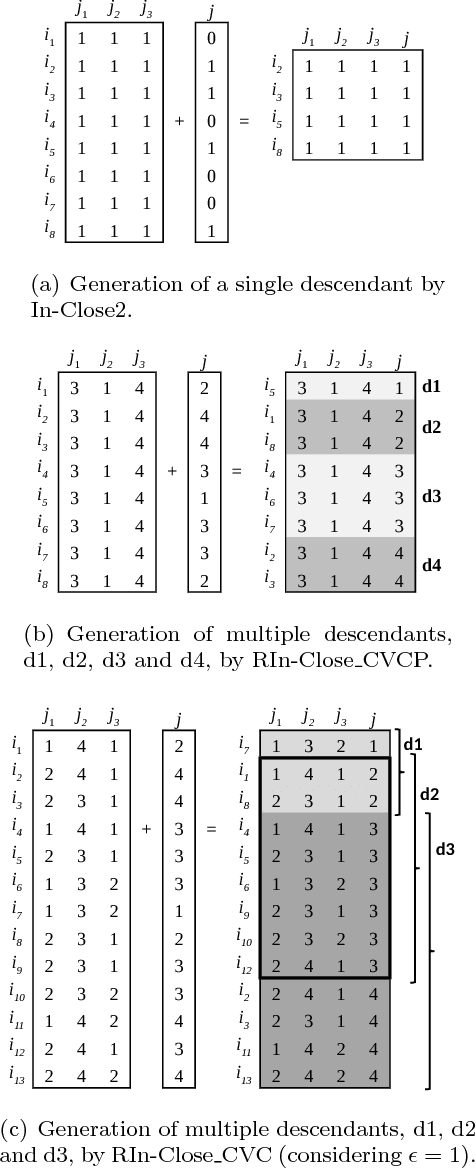

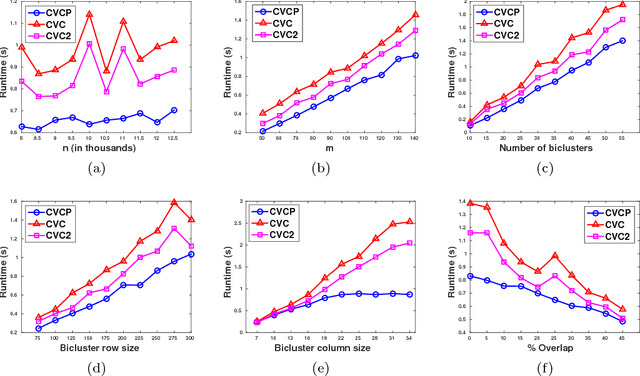
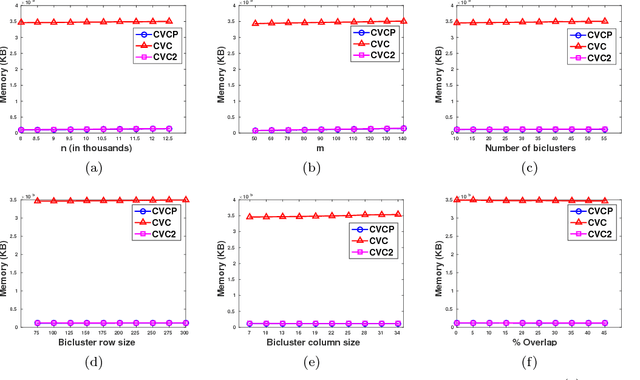
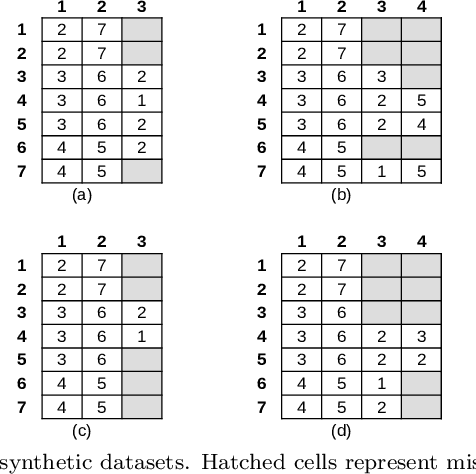
RIn-Close_CVC is an efficient (take polynomial time per bicluster), complete (find all maximal biclusters), correct (all biclusters attend the user-defined level of consistency) and non-redundant (all the obtained biclusters are maximal and the same bicluster is not enumerated more than once) enumerative algorithm for mining maximal biclusters with constant values on columns in numerical datasets. Despite RIn-Close_CVC has all these outstanding properties, it has a high computational cost in terms of memory usage because it must keep a symbol table in memory to prevent a maximal bicluster to be found more than once. In this paper, we propose a new version of RIn-Close_CVC, named RIn-Close_CVC2, that does not use a symbol table to prevent redundant biclusters, and keeps all these four properties. We also prove that these algorithms actually possess these properties. Experiments are carried out with synthetic and real-world datasets to compare RIn-Close_CVC and RIn-Close_CVC2 in terms of memory usage and runtime. The experimental results show that RIn-Close_CVC2 brings a large reduction in memory usage and, in average, significant runtime gain when compared to its predecessor.
Spatial Projection of Multiple Climate Variables using Hierarchical Multitask Learning
Jan 30, 2017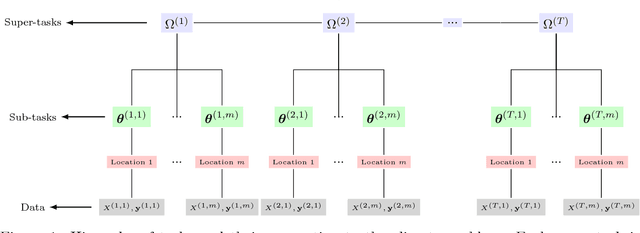
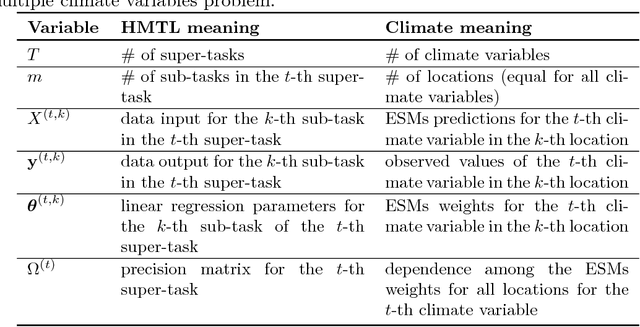
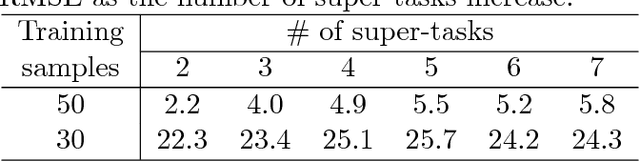
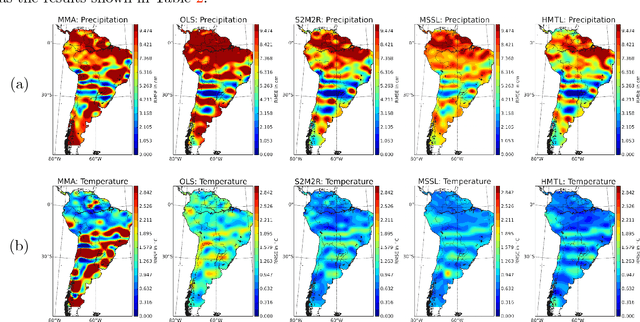
Future projection of climate is typically obtained by combining outputs from multiple Earth System Models (ESMs) for several climate variables such as temperature and precipitation. While IPCC has traditionally used a simple model output average, recent work has illustrated potential advantages of using a multitask learning (MTL) framework for projections of individual climate variables. In this paper we introduce a framework for hierarchical multitask learning (HMTL) with two levels of tasks such that each super-task, i.e., task at the top level, is itself a multitask learning problem over sub-tasks. For climate projections, each super-task focuses on projections of specific climate variables spatially using an MTL formulation. For the proposed HMTL approach, a group lasso regularization is added to couple parameters across the super-tasks, which in the climate context helps exploit relationships among the behavior of different climate variables at a given spatial location. We show that some recent works on MTL based on learning task dependency structures can be viewed as special cases of HMTL. Experiments on synthetic and real climate data show that HMTL produces better results than decoupled MTL methods applied separately on the super-tasks and HMTL significantly outperforms baselines for climate projection.
An Extremal Optimization approach to parallel resonance constrained capacitor placement problem
Jan 29, 2017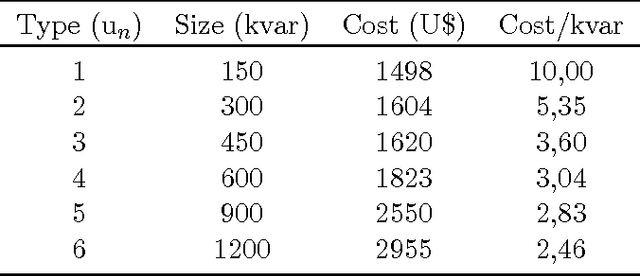


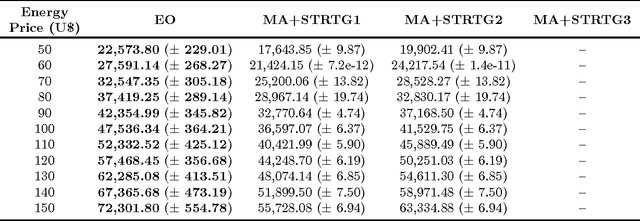
Installation of capacitors in distribution networks is one of the most used procedure to compensate reactive power generated by loads and, consequently, to reduce technical losses. So, the problem consists in identifying the optimal placement and sizing of capacitors. This problem is known in the literature as optimal capacitor placement problem. Neverthless, depending on the location and size of the capacitor, it may become a harmonic source, allowing capacitor to enter into resonance with the distribution network, causing several undesired side effects. In this work we propose a parsimonious method to deal with the capacitor placement problem that incorporates resonance constraints, ensuring that every allocated capacitor will not act as a harmonic source. This proposed algorithm is based upon a physical inspired metaheuristic known as Extremal Optimization. The results achieved showed that this proposal has reached significant gains when compared with other proposals that attempt repair, in a post-optimization stage, already obtained solutions which violate resonance constraints.
Single-Solution Hypervolume Maximization and its use for Improving Generalization of Neural Networks
Feb 03, 2016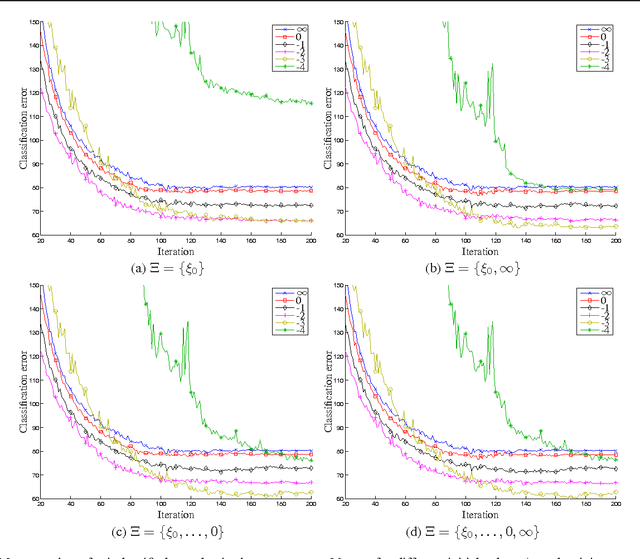
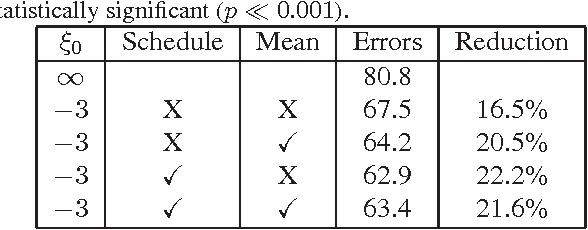
This paper introduces the hypervolume maximization with a single solution as an alternative to the mean loss minimization. The relationship between the two problems is proved through bounds on the cost function when an optimal solution to one of the problems is evaluated on the other, with a hyperparameter to control the similarity between the two problems. This same hyperparameter allows higher weight to be placed on samples with higher loss when computing the hypervolume's gradient, whose normalized version can range from the mean loss to the max loss. An experiment on MNIST with a neural network is used to validate the theory developed, showing that the hypervolume maximization can behave similarly to the mean loss minimization and can also provide better performance, resulting on a 20% reduction of the classification error on the test set.
Reducing the Training Time of Neural Networks by Partitioning
Jan 03, 2016

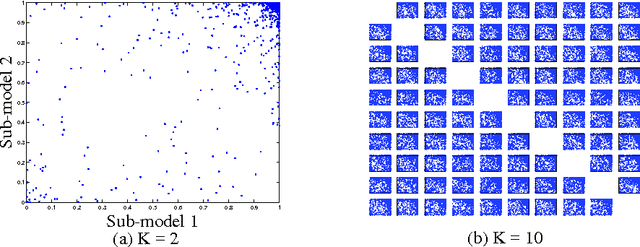
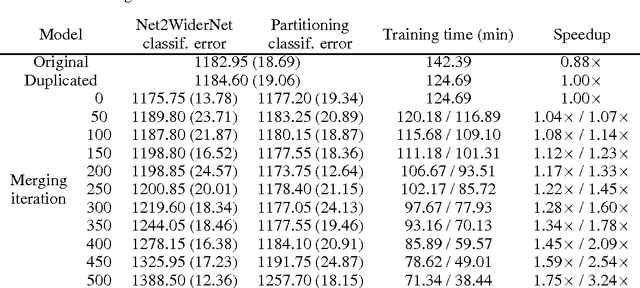
This paper presents a new method for pre-training neural networks that can decrease the total training time for a neural network while maintaining the final performance, which motivates its use on deep neural networks. By partitioning the training task in multiple training subtasks with sub-models, which can be performed independently and in parallel, it is shown that the size of the sub-models reduces almost quadratically with the number of subtasks created, quickly scaling down the sub-models used for the pre-training. The sub-models are then merged to provide a pre-trained initial set of weights for the original model. The proposed method is independent of the other aspects of the training, such as architecture of the neural network, training method, and objective, making it compatible with a wide range of existing approaches. The speedup without loss of performance is validated experimentally on MNIST and on CIFAR10 data sets, also showing that even performing the subtasks sequentially can decrease the training time. Moreover, we show that larger models may present higher speedups and conjecture about the benefits of the method in distributed learning systems.
Asymmetric Distributions from Constrained Mixtures
Mar 22, 2015

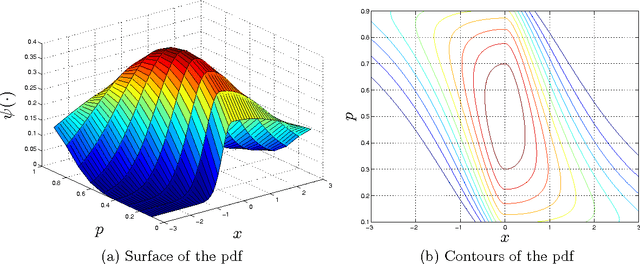
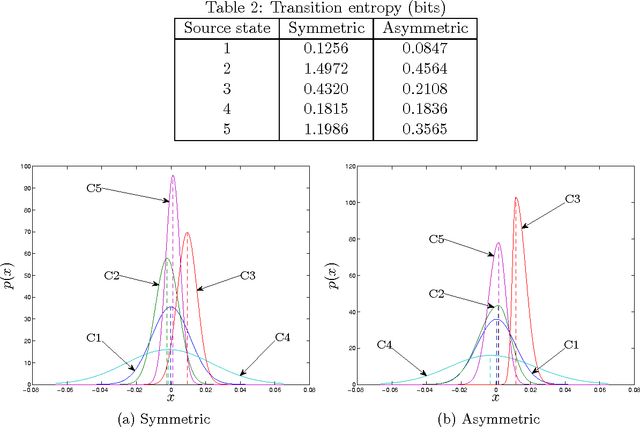
This paper introduces constrained mixtures for continuous distributions, characterized by a mixture of distributions where each distribution has a shape similar to the base distribution and disjoint domains. This new concept is used to create generalized asymmetric versions of the Laplace and normal distributions, which are shown to define exponential families, with known conjugate priors, and to have maximum likelihood estimates for the original parameters, with known closed-form expressions. The asymmetric and symmetric normal distributions are compared in a linear regression example, showing that the asymmetric version performs at least as well as the symmetric one, and in a real world time-series problem, where a hidden Markov model is used to fit a stock index, indicating that the asymmetric version provides higher likelihood and may learn distribution models over states and transition distributions with considerably less entropy.
Multi-task Sparse Structure Learning
Sep 02, 2014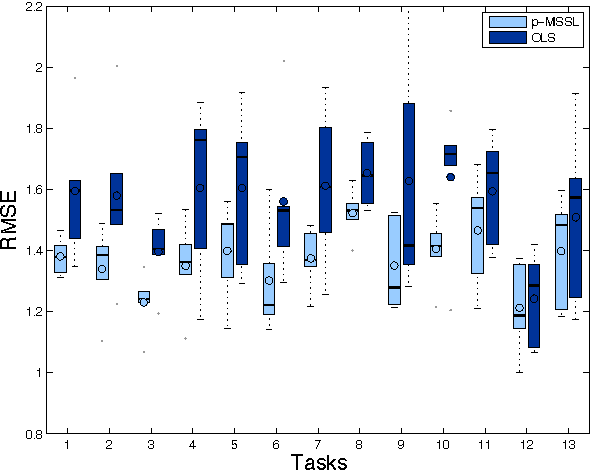

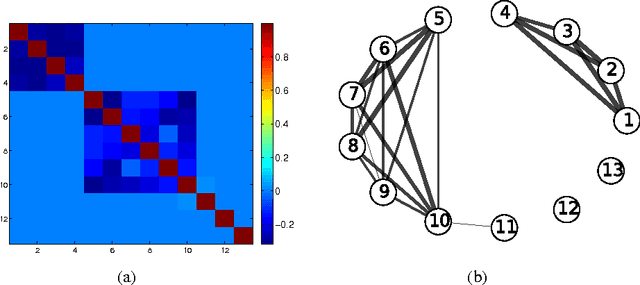

Multi-task learning (MTL) aims to improve generalization performance by learning multiple related tasks simultaneously. While sometimes the underlying task relationship structure is known, often the structure needs to be estimated from data at hand. In this paper, we present a novel family of models for MTL, applicable to regression and classification problems, capable of learning the structure of task relationships. In particular, we consider a joint estimation problem of the task relationship structure and the individual task parameters, which is solved using alternating minimization. The task relationship structure learning component builds on recent advances in structure learning of Gaussian graphical models based on sparse estimators of the precision (inverse covariance) matrix. We illustrate the effectiveness of the proposed model on a variety of synthetic and benchmark datasets for regression and classification. We also consider the problem of combining climate model outputs for better projections of future climate, with focus on temperature in South America, and show that the proposed model outperforms several existing methods for the problem.