 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew advances in enumerative biclustering algorithms with online partitioning
Paper and Code
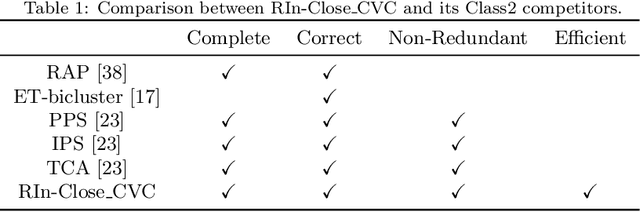
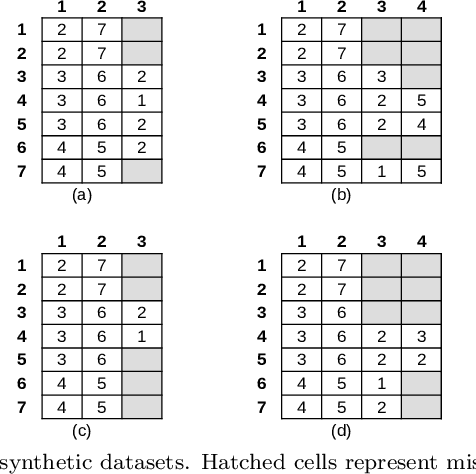


This paper further extends RIn-Close_CVC, a biclustering algorithm capable of performing an efficient, complete, correct and non-redundant enumeration of maximal biclusters with constant values on columns in numerical datasets. By avoiding a priori partitioning and itemization of the dataset, RIn-Close_CVC implements an online partitioning, which is demonstrated here to guide to more informative biclustering results. The improved algorithm is called RIn-Close_CVC3, keeps those attractive properties of RIn-Close_CVC, as formally proved here, and is characterized by: a drastic reduction in memory usage; a consistent gain in runtime; additional ability to handle datasets with missing values; and additional ability to operate with attributes characterized by distinct distributions or even mixed data types. The experimental results include synthetic and real-world datasets used to perform scalability and sensitivity analyses. As a practical case study, a parsimonious set of relevant and interpretable mixed-attribute-type rules is obtained in the context of supervised descriptive pattern mining.