 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew advances in enumerative biclustering algorithms with online partitioning
Mar 07, 2020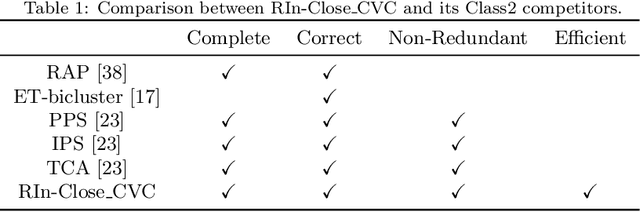


This paper further extends RIn-Close_CVC, a biclustering algorithm capable of performing an efficient, complete, correct and non-redundant enumeration of maximal biclusters with constant values on columns in numerical datasets. By avoiding a priori partitioning and itemization of the dataset, RIn-Close_CVC implements an online partitioning, which is demonstrated here to guide to more informative biclustering results. The improved algorithm is called RIn-Close_CVC3, keeps those attractive properties of RIn-Close_CVC, as formally proved here, and is characterized by: a drastic reduction in memory usage; a consistent gain in runtime; additional ability to handle datasets with missing values; and additional ability to operate with attributes characterized by distinct distributions or even mixed data types. The experimental results include synthetic and real-world datasets used to perform scalability and sensitivity analyses. As a practical case study, a parsimonious set of relevant and interpretable mixed-attribute-type rules is obtained in the context of supervised descriptive pattern mining.
RIn-Close_CVC2: an even more efficient enumerative algorithm for biclustering of numerical datasets
Oct 17, 2018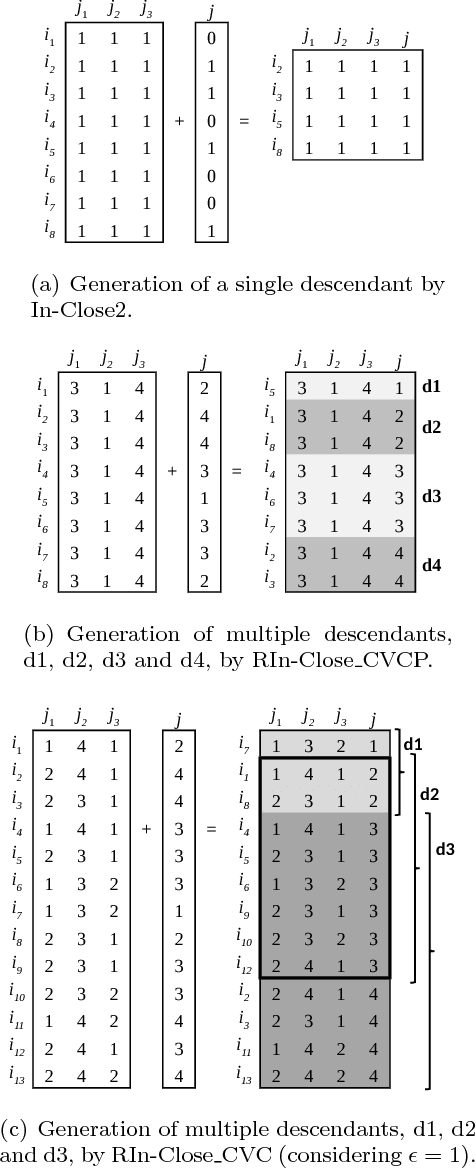

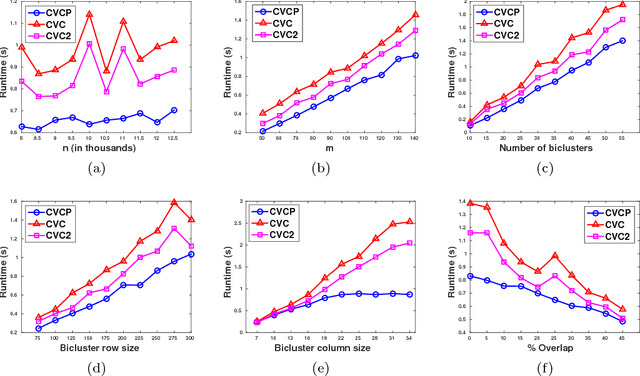
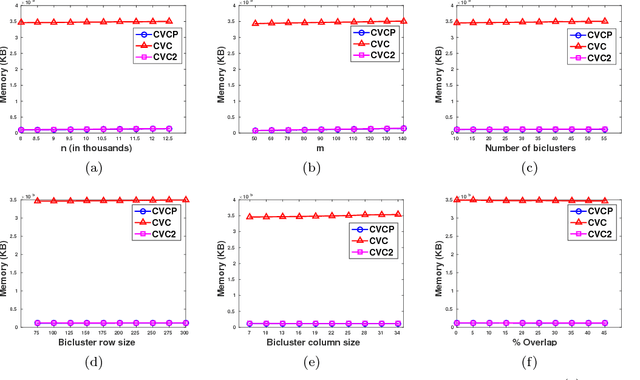
RIn-Close_CVC is an efficient (take polynomial time per bicluster), complete (find all maximal biclusters), correct (all biclusters attend the user-defined level of consistency) and non-redundant (all the obtained biclusters are maximal and the same bicluster is not enumerated more than once) enumerative algorithm for mining maximal biclusters with constant values on columns in numerical datasets. Despite RIn-Close_CVC has all these outstanding properties, it has a high computational cost in terms of memory usage because it must keep a symbol table in memory to prevent a maximal bicluster to be found more than once. In this paper, we propose a new version of RIn-Close_CVC, named RIn-Close_CVC2, that does not use a symbol table to prevent redundant biclusters, and keeps all these four properties. We also prove that these algorithms actually possess these properties. Experiments are carried out with synthetic and real-world datasets to compare RIn-Close_CVC and RIn-Close_CVC2 in terms of memory usage and runtime. The experimental results show that RIn-Close_CVC2 brings a large reduction in memory usage and, in average, significant runtime gain when compared to its predecessor.
On bicluster aggregation and its benefits for enumerative solutions
Jun 02, 2015



Biclustering involves the simultaneous clustering of objects and their attributes, thus defining local two-way clustering models. Recently, efficient algorithms were conceived to enumerate all biclusters in real-valued datasets. In this case, the solution composes a complete set of maximal and non-redundant biclusters. However, the ability to enumerate biclusters revealed a challenging scenario: in noisy datasets, each true bicluster may become highly fragmented and with a high degree of overlapping. It prevents a direct analysis of the obtained results. To revert the fragmentation, we propose here two approaches for properly aggregating the whole set of enumerated biclusters: one based on single linkage and the other directly exploring the rate of overlapping. Both proposals were compared with each other and with the actual state-of-the-art in several experiments, and they not only significantly reduced the number of biclusters but also consistently increased the quality of the solution.