 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental user embedding modeling for personalized text classification
Feb 13, 2022
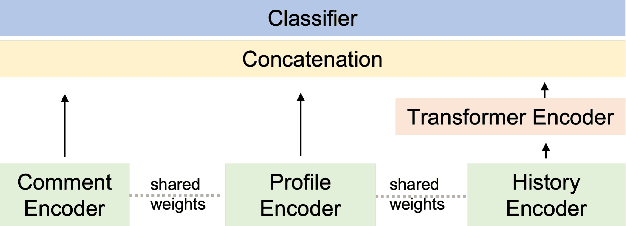


Individual user profiles and interaction histories play a significant role in providing customized experiences in real-world applications such as chatbots, social media, retail, and education. Adaptive user representation learning by utilizing user personalized information has become increasingly challenging due to ever-growing history data. In this work, we propose an incremental user embedding modeling approach, in which embeddings of user's recent interaction histories are dynamically integrated into the accumulated history vectors via a transformer encoder. This modeling paradigm allows us to create generalized user representations in a consecutive manner and also alleviate the challenges of data management. We demonstrate the effectiveness of this approach by applying it to a personalized multi-class classification task based on the Reddit dataset, and achieve 9% and 30% relative improvement on prediction accuracy over a baseline system for two experiment settings through appropriate comment history encoding and task modeling.
Wav2vec-C: A Self-supervised Model for Speech Representation Learning
Mar 09, 2021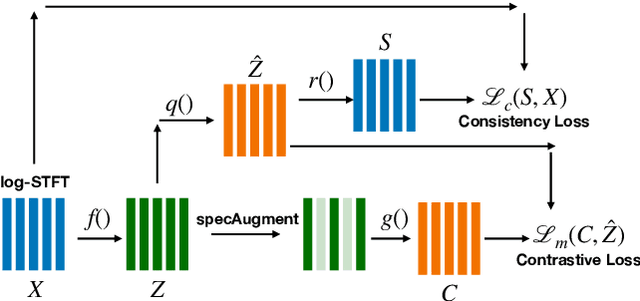

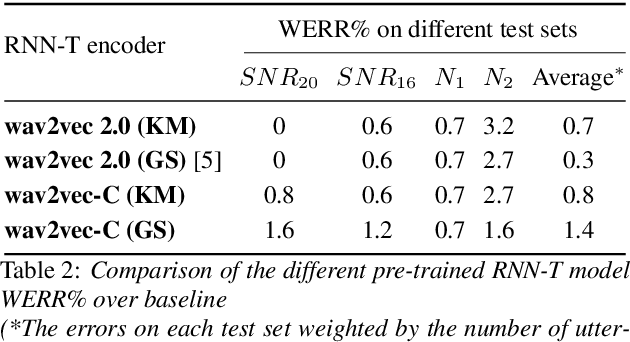
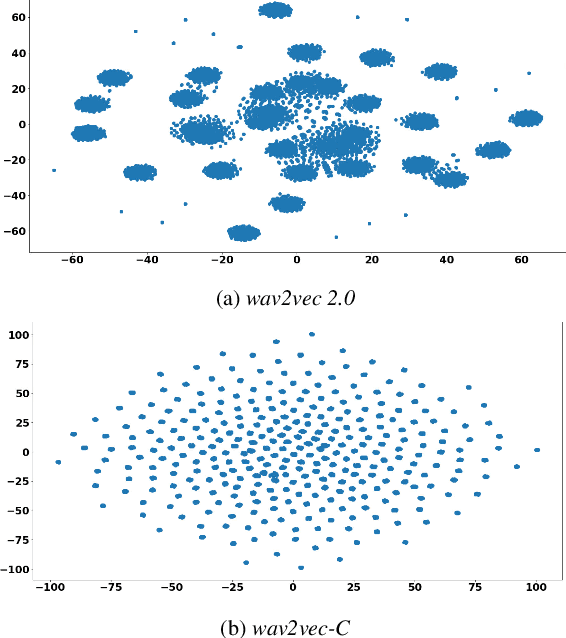
Wav2vec-C introduces a novel representation learning technique combining elements from wav2vec 2.0 and VQ-VAE. Our model learns to reproduce quantized representations from partially masked speech encoding using a contrastive loss in a way similar to Wav2vec 2.0. However, the quantization process is regularized by an additional consistency network that learns to reconstruct the input features to the wav2vec 2.0 network from the quantized representations in a way similar to a VQ-VAE model. The proposed self-supervised model is trained on 10k hours of unlabeled data and subsequently used as the speech encoder in a RNN-T ASR model and fine-tuned with 1k hours of labeled data. This work is one of only a few studies of self-supervised learning on speech tasks with a large volume of real far-field labeled data. The Wav2vec-C encoded representations achieves, on average, twice the error reduction over baseline and a higher codebook utilization in comparison to wav2vec 2.0
Efficient minimum word error rate training of RNN-Transducer for end-to-end speech recognition
Jul 27, 2020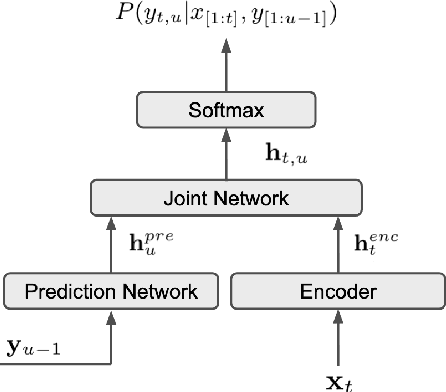
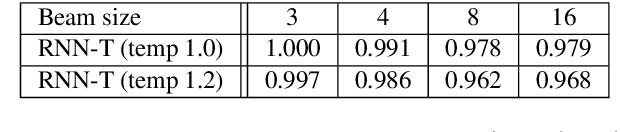
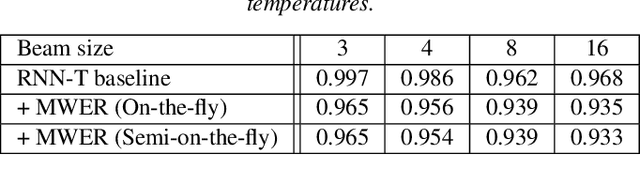
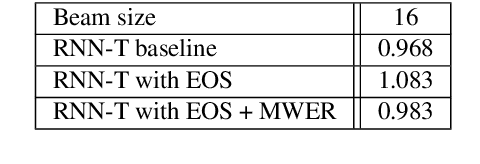
In this work, we propose a novel and efficient minimum word error rate (MWER) training method for RNN-Transducer (RNN-T). Unlike previous work on this topic, which performs on-the-fly limited-size beam-search decoding and generates alignment scores for expected edit-distance computation, in our proposed method, we re-calculate and sum scores of all the possible alignments for each hypothesis in N-best lists. The hypothesis probability scores and back-propagated gradients are calculated efficiently using the forward-backward algorithm. Moreover, the proposed method allows us to decouple the decoding and training processes, and thus we can perform offline parallel-decoding and MWER training for each subset iteratively. Experimental results show that this proposed semi-on-the-fly method can speed up the on-the-fly method by 6 times and result in a similar WER improvement (3.6%) over a baseline RNN-T model. The proposed MWER training can also effectively reduce high-deletion errors (9.2% WER-reduction) introduced by RNN-T models when EOS is added for endpointer. Further improvement can be achieved if we use a proposed RNN-T rescoring method to re-rank hypotheses and use external RNN-LM to perform additional rescoring. The best system achieves a 5% relative improvement on an English test-set of real far-field recordings and a 11.6% WER reduction on music-domain utterances.
Normalization Before Shaking Toward Learning Symmetrically Distributed Representation Without Margin in Speech Emotion Recognition
Aug 05, 2018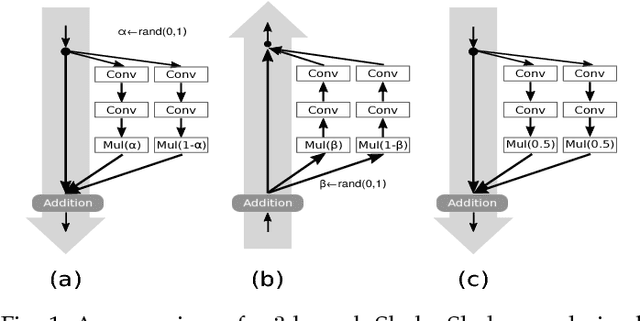
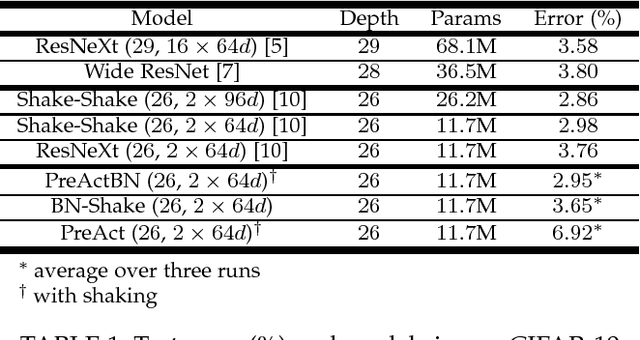
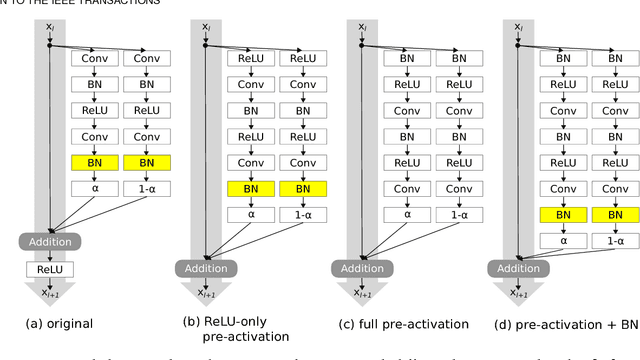
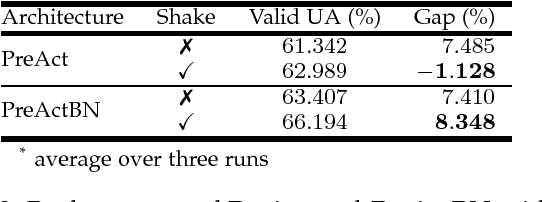
Regularization is crucial to the success of many practical deep learning models, in particular in a more often than not scenario where there are only a few to a moderate number of accessible training samples. In addition to weight decay, data augmentation and dropout, regularization based on multi-branch architectures, such as Shake-Shake regularization, has been proven successful in many applications and attracted more and more attention. However, beyond model-based representation augmentation, it is unclear how Shake-Shake regularization helps to provide further improvement on classification tasks, let alone the baffling interaction between batch normalization and shaking. In this work, we present our investigation on Shake-Shake regularization, drawing connections to the vicinal risk minimization principle and discriminative feature learning in verification tasks. Furthermore, we identify a strong resemblance between batch normalized residual blocks and batch normalized recurrent neural networks, where both of them share a similar convergence behavior, which could be mitigated by a proper initialization of batch normalization. Based on the findings, our experiments on speech emotion recognition demonstrate simultaneously an improvement on the classification accuracy and a reduction on the generalization gap both with statistical significance.
Characterizing Types of Convolution in Deep Convolutional Recurrent Neural Networks for Robust Speech Emotion Recognition
Jan 13, 2018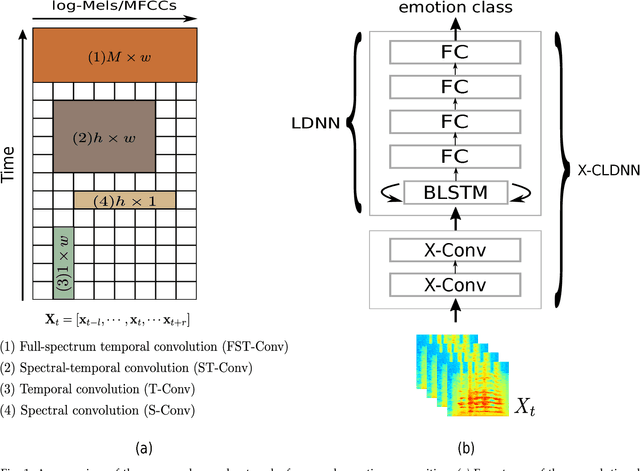

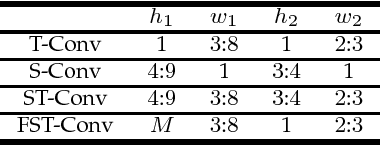
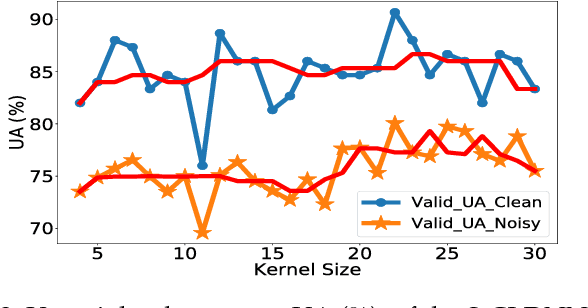
Deep convolutional neural networks are being actively investigated in a wide range of speech and audio processing applications including speech recognition, audio event detection and computational paralinguistics, owing to their ability to reduce factors of variations, for learning from speech. However, studies have suggested to favor a certain type of convolutional operations when building a deep convolutional neural network for speech applications although there has been promising results using different types of convolutional operations. In this work, we study four types of convolutional operations on different input features for speech emotion recognition under noisy and clean conditions in order to derive a comprehensive understanding. Since affective behavioral information has been shown to reflect temporally varying of mental state and convolutional operation are applied locally in time, all deep neural networks share a deep recurrent sub-network architecture for further temporal modeling. We present detailed quantitative module-wise performance analysis to gain insights into information flows within the proposed architectures. In particular, we demonstrate the interplay of affective information and the other irrelevant information during the progression from one module to another. Finally we show that all of our deep neural networks provide state-of-the-art performance on the eNTERFACE'05 corpus.