 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Self-Learning with Weak Supervision for Speech Recognition
Jun 21, 2023



Automatic speech recognition (ASR) models with low-footprint are increasingly being deployed on edge devices for conversational agents, which enhances privacy. We study the problem of federated continual incremental learning for recurrent neural network-transducer (RNN-T) ASR models in the privacy-enhancing scheme of learning on-device, without access to ground truth human transcripts or machine transcriptions from a stronger ASR model. In particular, we study the performance of a self-learning based scheme, with a paired teacher model updated through an exponential moving average of ASR models. Further, we propose using possibly noisy weak-supervision signals such as feedback scores and natural language understanding semantics determined from user behavior across multiple turns in a session of interactions with the conversational agent. These signals are leveraged in a multi-task policy-gradient training approach to improve the performance of self-learning for ASR. Finally, we show how catastrophic forgetting can be mitigated by combining on-device learning with a memory-replay approach using selected historical datasets. These innovations allow for 10% relative improvement in WER on new use cases with minimal degradation on other test sets in the absence of strong-supervision signals such as ground-truth transcriptions.
ILASR: Privacy-Preserving Incremental Learning for Automatic Speech Recognition at Production Scale
Jul 22, 2022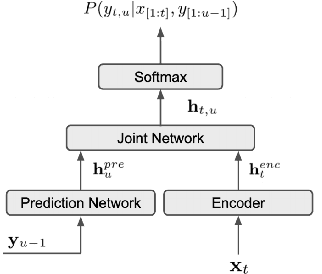
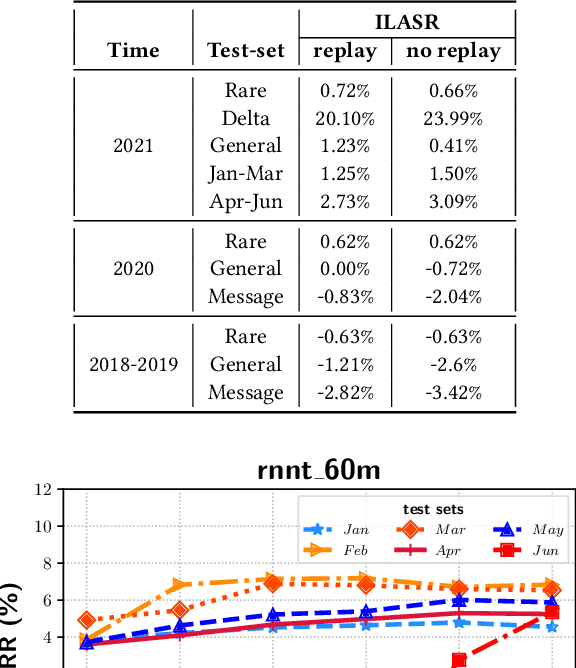
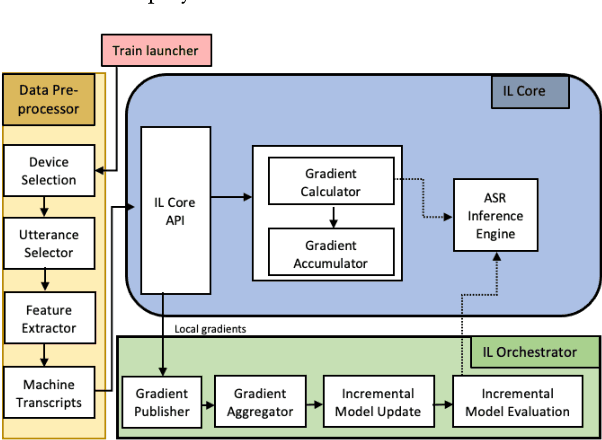
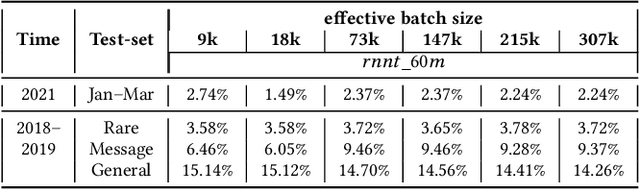
Incremental learning is one paradigm to enable model building and updating at scale with streaming data. For end-to-end automatic speech recognition (ASR) tasks, the absence of human annotated labels along with the need for privacy preserving policies for model building makes it a daunting challenge. Motivated by these challenges, in this paper we use a cloud based framework for production systems to demonstrate insights from privacy preserving incremental learning for automatic speech recognition (ILASR). By privacy preserving, we mean, usage of ephemeral data which are not human annotated. This system is a step forward for production levelASR models for incremental/continual learning that offers near real-time test-bed for experimentation in the cloud for end-to-end ASR, while adhering to privacy-preserving policies. We show that the proposed system can improve the production models significantly(3%) over a new time period of six months even in the absence of human annotated labels with varying levels of weak supervision and large batch sizes in incremental learning. This improvement is 20% over test sets with new words and phrases in the new time period. We demonstrate the effectiveness of model building in a privacy-preserving incremental fashion for ASR while further exploring the utility of having an effective teacher model and use of large batch sizes.
End-to-End Spoken Language Understanding using RNN-Transducer ASR
Jul 08, 2021
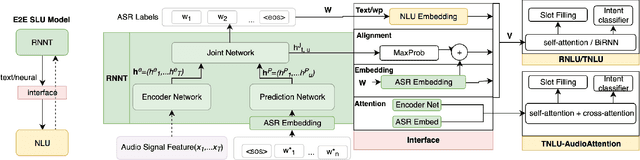

We propose an end-to-end trained spoken language understanding (SLU) system that extracts transcripts, intents and slots from an input speech utterance. It consists of a streaming recurrent neural network transducer (RNNT) based automatic speech recognition (ASR) model connected to a neural natural language understanding (NLU) model through a neural interface. This interface allows for end-to-end training using multi-task RNNT and NLU losses. Additionally, we introduce semantic sequence loss training for the joint RNNT-NLU system that allows direct optimization of non-differentiable SLU metrics. This end-to-end SLU model paradigm can leverage state-of-the-art advancements and pretrained models in both ASR and NLU research communities, outperforming recently proposed direct speech-to-semantics models, and conventional pipelined ASR and NLU systems. We show that this method improves both ASR and NLU metrics on both public SLU datasets and large proprietary datasets.
Personalization Strategies for End-to-End Speech Recognition Systems
Feb 15, 2021
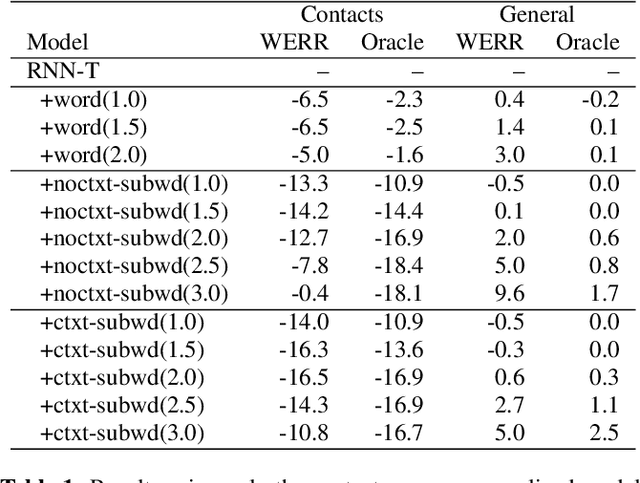
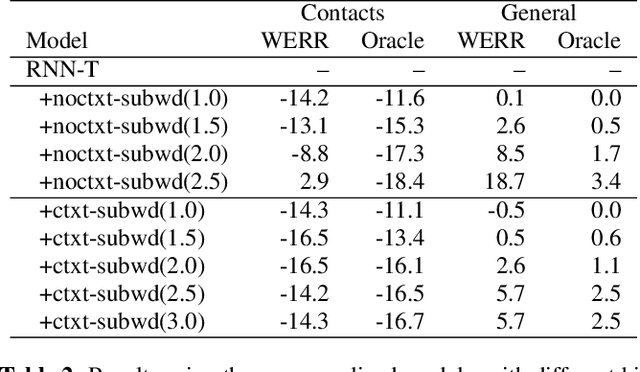
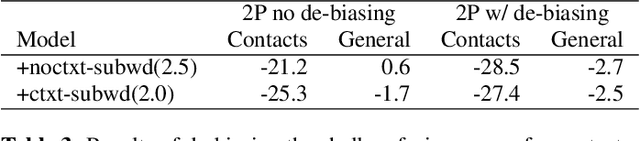
The recognition of personalized content, such as contact names, remains a challenging problem for end-to-end speech recognition systems. In this work, we demonstrate how first and second-pass rescoring strategies can be leveraged together to improve the recognition of such words. Following previous work, we use a shallow fusion approach to bias towards recognition of personalized content in the first-pass decoding. We show that such an approach can improve personalized content recognition by up to 16% with minimum degradation on the general use case. We describe a fast and scalable algorithm that enables our biasing models to remain at the word-level, while applying the biasing at the subword level. This has the advantage of not requiring the biasing models to be dependent on any subword symbol table. We also describe a novel second-pass de-biasing approach: used in conjunction with a first-pass shallow fusion that optimizes on oracle WER, we can achieve an additional 14% improvement on personalized content recognition, and even improve accuracy for the general use case by up to 2.5%.
Do as I mean, not as I say: Sequence Loss Training for Spoken Language Understanding
Feb 12, 2021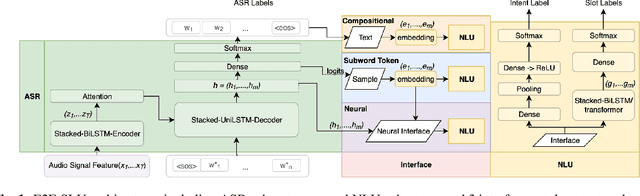
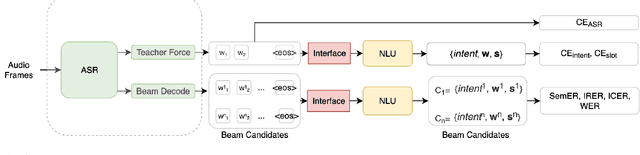
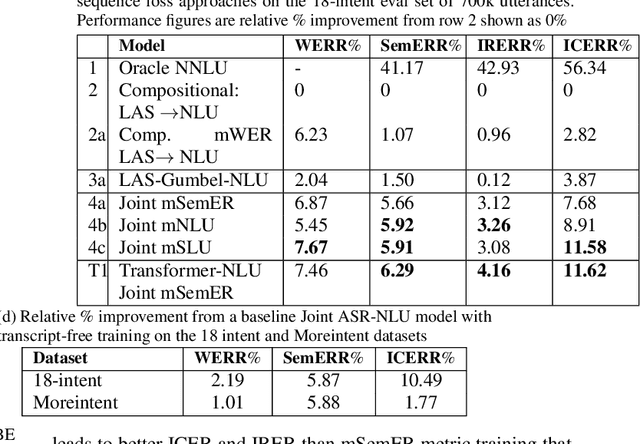
Spoken language understanding (SLU) systems extract transcriptions, as well as semantics of intent or named entities from speech, and are essential components of voice activated systems. SLU models, which either directly extract semantics from audio or are composed of pipelined automatic speech recognition (ASR) and natural language understanding (NLU) models, are typically trained via differentiable cross-entropy losses, even when the relevant performance metrics of interest are word or semantic error rates. In this work, we propose non-differentiable sequence losses based on SLU metrics as a proxy for semantic error and use the REINFORCE trick to train ASR and SLU models with this loss. We show that custom sequence loss training is the state-of-the-art on open SLU datasets and leads to 6% relative improvement in both ASR and NLU performance metrics on large proprietary datasets. We also demonstrate how the semantic sequence loss training paradigm can be used to update ASR and SLU models without transcripts, using semantic feedback alone.
Efficient minimum word error rate training of RNN-Transducer for end-to-end speech recognition
Jul 27, 2020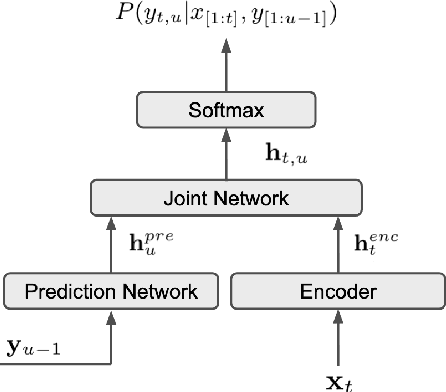
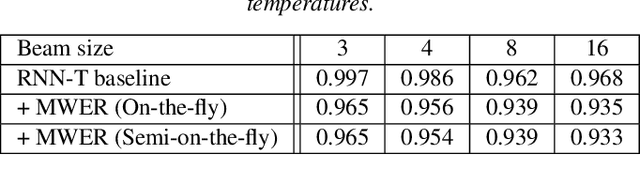
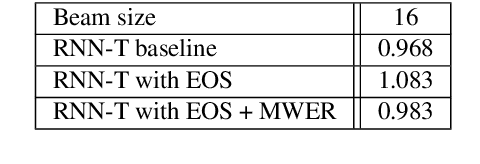
In this work, we propose a novel and efficient minimum word error rate (MWER) training method for RNN-Transducer (RNN-T). Unlike previous work on this topic, which performs on-the-fly limited-size beam-search decoding and generates alignment scores for expected edit-distance computation, in our proposed method, we re-calculate and sum scores of all the possible alignments for each hypothesis in N-best lists. The hypothesis probability scores and back-propagated gradients are calculated efficiently using the forward-backward algorithm. Moreover, the proposed method allows us to decouple the decoding and training processes, and thus we can perform offline parallel-decoding and MWER training for each subset iteratively. Experimental results show that this proposed semi-on-the-fly method can speed up the on-the-fly method by 6 times and result in a similar WER improvement (3.6%) over a baseline RNN-T model. The proposed MWER training can also effectively reduce high-deletion errors (9.2% WER-reduction) introduced by RNN-T models when EOS is added for endpointer. Further improvement can be achieved if we use a proposed RNN-T rescoring method to re-rank hypotheses and use external RNN-LM to perform additional rescoring. The best system achieves a 5% relative improvement on an English test-set of real far-field recordings and a 11.6% WER reduction on music-domain utterances.
Scalable Multi Corpora Neural Language Models for ASR
Jul 02, 2019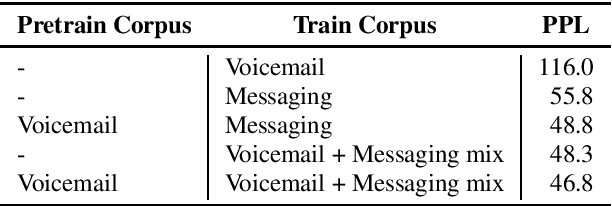


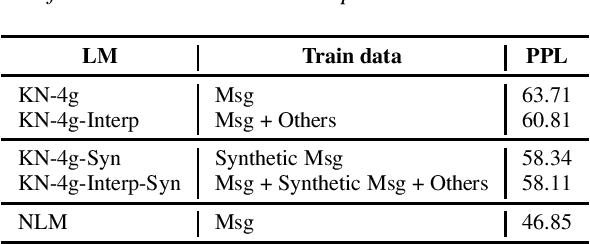
Neural language models (NLM) have been shown to outperform conventional n-gram language models by a substantial margin in Automatic Speech Recognition (ASR) and other tasks. There are, however, a number of challenges that need to be addressed for an NLM to be used in a practical large-scale ASR system. In this paper, we present solutions to some of the challenges, including training NLM from heterogenous corpora, limiting latency impact and handling personalized bias in the second-pass rescorer. Overall, we show that we can achieve a 6.2% relative WER reduction using neural LM in a second-pass n-best rescoring framework with a minimal increase in latency.