 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalization Strategies for End-to-End Speech Recognition Systems
Feb 15, 2021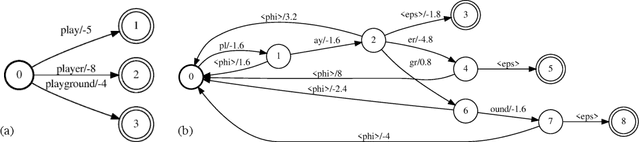
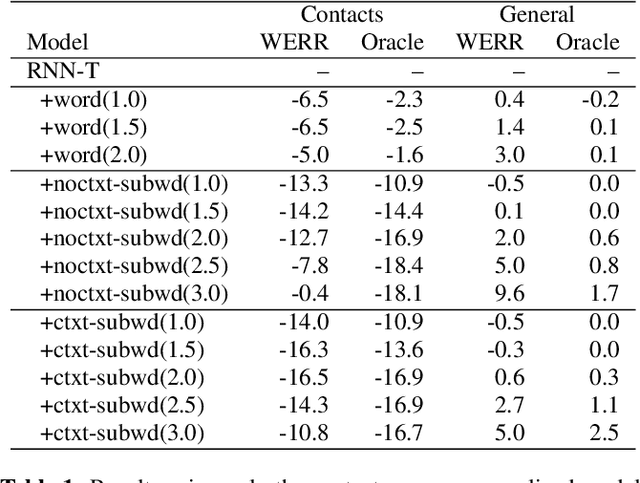
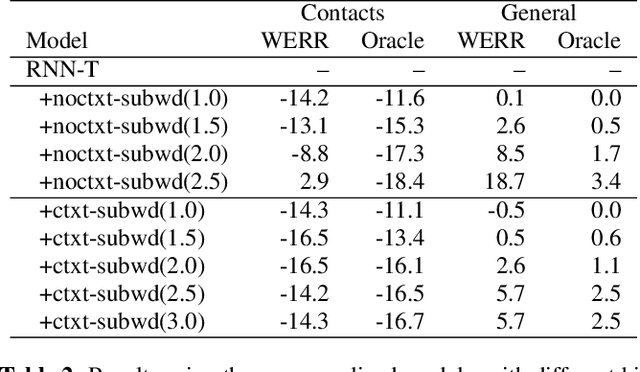
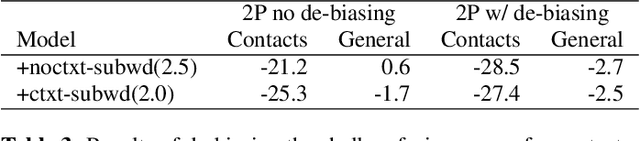
The recognition of personalized content, such as contact names, remains a challenging problem for end-to-end speech recognition systems. In this work, we demonstrate how first and second-pass rescoring strategies can be leveraged together to improve the recognition of such words. Following previous work, we use a shallow fusion approach to bias towards recognition of personalized content in the first-pass decoding. We show that such an approach can improve personalized content recognition by up to 16% with minimum degradation on the general use case. We describe a fast and scalable algorithm that enables our biasing models to remain at the word-level, while applying the biasing at the subword level. This has the advantage of not requiring the biasing models to be dependent on any subword symbol table. We also describe a novel second-pass de-biasing approach: used in conjunction with a first-pass shallow fusion that optimizes on oracle WER, we can achieve an additional 14% improvement on personalized content recognition, and even improve accuracy for the general use case by up to 2.5%.
Streaming Language Identification using Combination of Acoustic Representations and ASR Hypotheses
Jun 01, 2020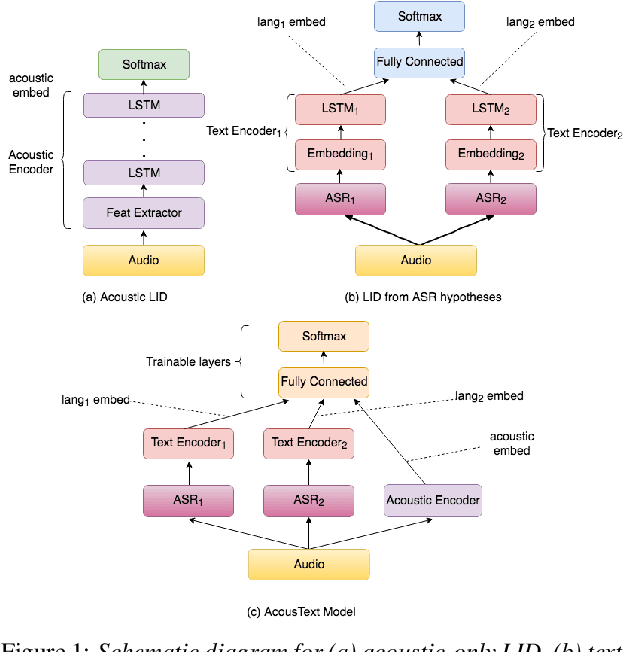
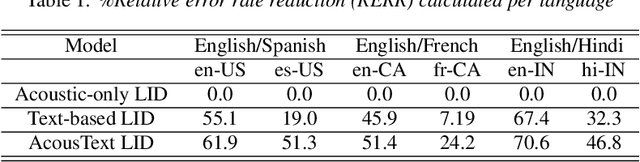
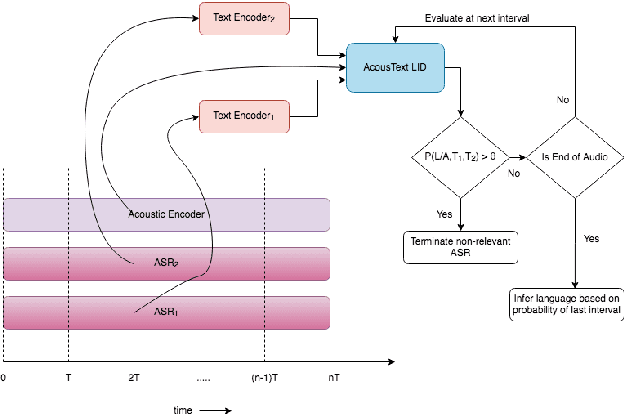

This paper presents our modeling and architecture approaches for building a highly accurate low-latency language identification system to support multilingual spoken queries for voice assistants. A common approach to solve multilingual speech recognition is to run multiple monolingual ASR systems in parallel and rely on a language identification (LID) component that detects the input language. Conventionally, LID relies on acoustic only information to detect input language. We propose an approach that learns and combines acoustic level representations with embeddings estimated on ASR hypotheses resulting in up to 50% relative reduction of identification error rate, compared to a model that uses acoustic only features. Furthermore, to reduce the processing cost and latency, we exploit a streaming architecture to identify the spoken language early when the system reaches a predetermined confidence level, alleviating the need to run multiple ASR systems until the end of input query. The combined acoustic and text LID, coupled with our proposed streaming runtime architecture, results in an average of 1500ms early identification for more than 50% of utterances, with almost no degradation in accuracy. We also show improved results by adopting a semi-supervised learning (SSL) technique using the newly proposed model architecture as a teacher model.