 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalization Strategies for End-to-End Speech Recognition Systems
Feb 15, 2021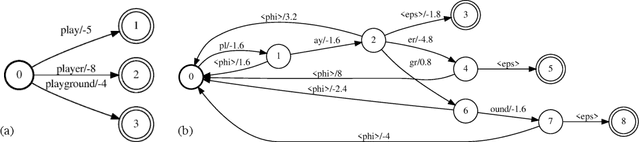
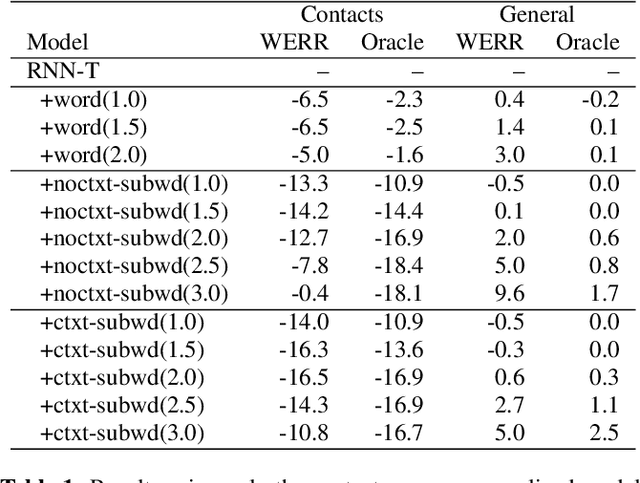
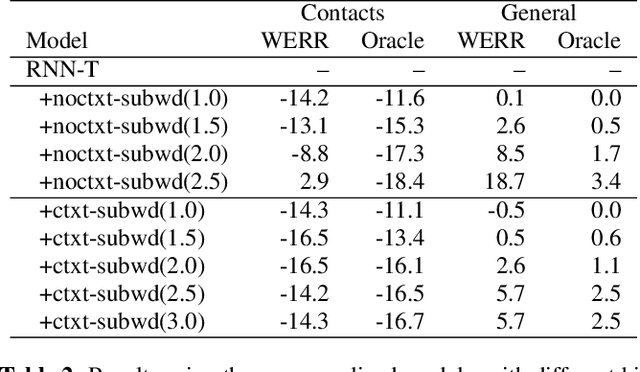
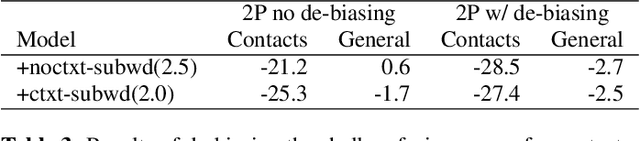
The recognition of personalized content, such as contact names, remains a challenging problem for end-to-end speech recognition systems. In this work, we demonstrate how first and second-pass rescoring strategies can be leveraged together to improve the recognition of such words. Following previous work, we use a shallow fusion approach to bias towards recognition of personalized content in the first-pass decoding. We show that such an approach can improve personalized content recognition by up to 16% with minimum degradation on the general use case. We describe a fast and scalable algorithm that enables our biasing models to remain at the word-level, while applying the biasing at the subword level. This has the advantage of not requiring the biasing models to be dependent on any subword symbol table. We also describe a novel second-pass de-biasing approach: used in conjunction with a first-pass shallow fusion that optimizes on oracle WER, we can achieve an additional 14% improvement on personalized content recognition, and even improve accuracy for the general use case by up to 2.5%.
Domain-aware Neural Language Models for Speech Recognition
Jan 05, 2021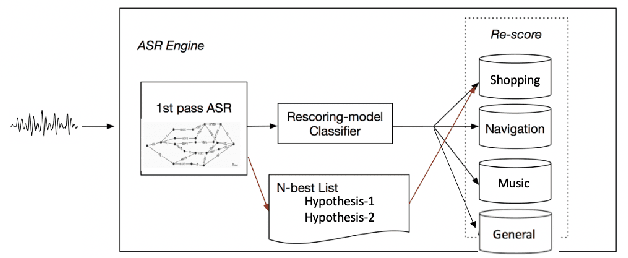
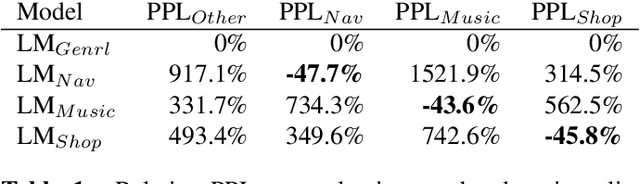

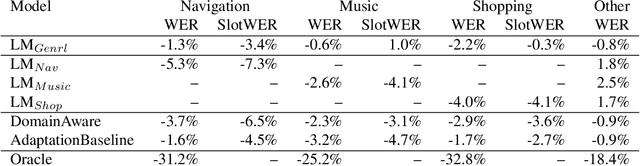
As voice assistants become more ubiquitous, they are increasingly expected to support and perform well on a wide variety of use-cases across different domains. We present a domain-aware rescoring framework suitable for achieving domain-adaptation during second-pass rescoring in production settings. In our framework, we fine-tune a domain-general neural language model on several domains, and use an LSTM-based domain classification model to select the appropriate domain-adapted model to use for second-pass rescoring. This domain-aware rescoring improves the word error rate by up to 2.4% and slot word error rate by up to 4.1% on three individual domains -- shopping, navigation, and music -- compared to domain general rescoring. These improvements are obtained while maintaining accuracy for the general use case.