 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalization Strategies for End-to-End Speech Recognition Systems
Feb 15, 2021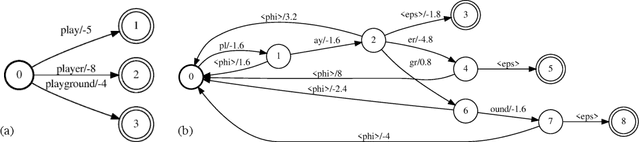
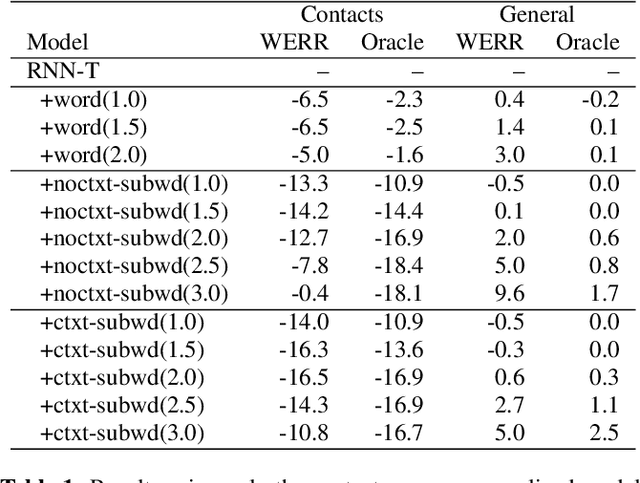
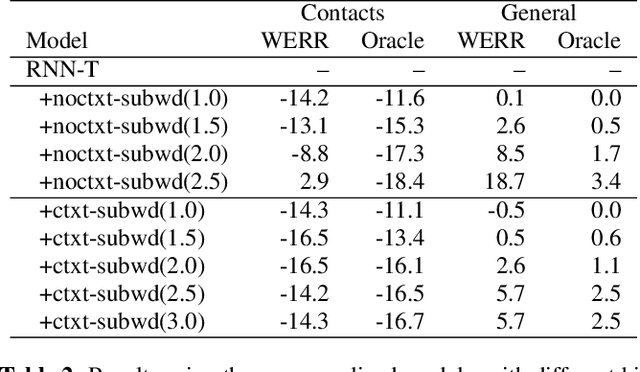
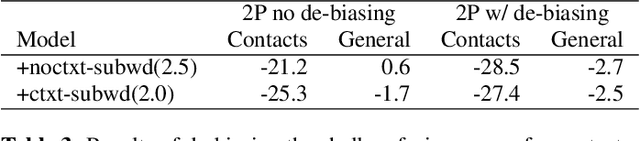
The recognition of personalized content, such as contact names, remains a challenging problem for end-to-end speech recognition systems. In this work, we demonstrate how first and second-pass rescoring strategies can be leveraged together to improve the recognition of such words. Following previous work, we use a shallow fusion approach to bias towards recognition of personalized content in the first-pass decoding. We show that such an approach can improve personalized content recognition by up to 16% with minimum degradation on the general use case. We describe a fast and scalable algorithm that enables our biasing models to remain at the word-level, while applying the biasing at the subword level. This has the advantage of not requiring the biasing models to be dependent on any subword symbol table. We also describe a novel second-pass de-biasing approach: used in conjunction with a first-pass shallow fusion that optimizes on oracle WER, we can achieve an additional 14% improvement on personalized content recognition, and even improve accuracy for the general use case by up to 2.5%.
Scalable Multi Corpora Neural Language Models for ASR
Jul 02, 2019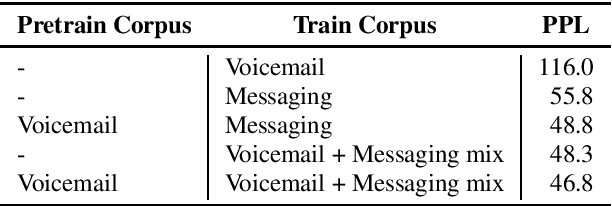


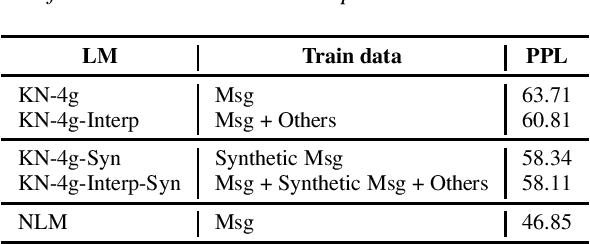
Neural language models (NLM) have been shown to outperform conventional n-gram language models by a substantial margin in Automatic Speech Recognition (ASR) and other tasks. There are, however, a number of challenges that need to be addressed for an NLM to be used in a practical large-scale ASR system. In this paper, we present solutions to some of the challenges, including training NLM from heterogenous corpora, limiting latency impact and handling personalized bias in the second-pass rescorer. Overall, we show that we can achieve a 6.2% relative WER reduction using neural LM in a second-pass n-best rescoring framework with a minimal increase in latency.