 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Training Strategies and Model Robustness of Low-Rank Adaptation for Language Modeling in Speech Recognition
Jan 19, 2024The use of low-rank adaptation (LoRA) with frozen pretrained language models (PLMs) has become increasing popular as a mainstream, resource-efficient modeling approach for memory-constrained hardware. In this study, we first explore how to enhance model performance by introducing various LoRA training strategies, achieving relative word error rate reductions of 3.50\% on the public Librispeech dataset and of 3.67\% on an internal dataset in the messaging domain. To further characterize the stability of LoRA-based second-pass speech recognition models, we examine robustness against input perturbations. These perturbations are rooted in homophone replacements and a novel metric called N-best Perturbation-based Rescoring Robustness (NPRR), both designed to measure the relative degradation in the performance of rescoring models. Our experimental results indicate that while advanced variants of LoRA, such as dynamic rank-allocated LoRA, lead to performance degradation in $1$-best perturbation, they alleviate the degradation in $N$-best perturbation. This finding is in comparison to fully-tuned models and vanilla LoRA tuning baselines, suggesting that a comprehensive selection is needed when using LoRA-based adaptation for compute-cost savings and robust language modeling.
Low-rank Adaptation of Large Language Model Rescoring for Parameter-Efficient Speech Recognition
Sep 26, 2023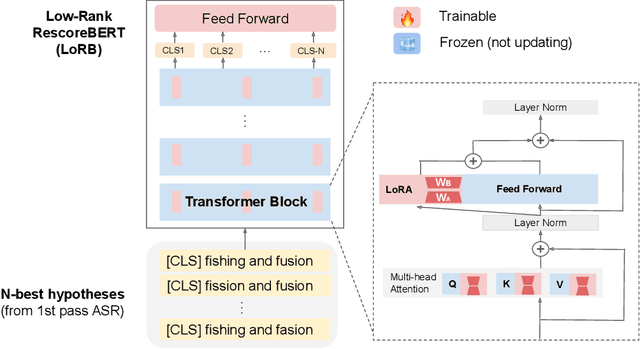
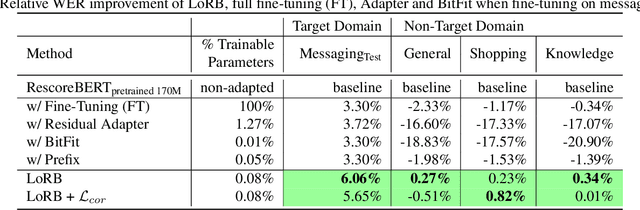
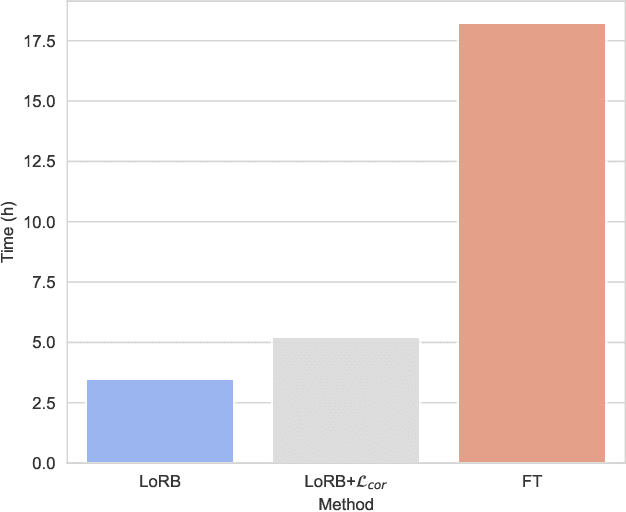
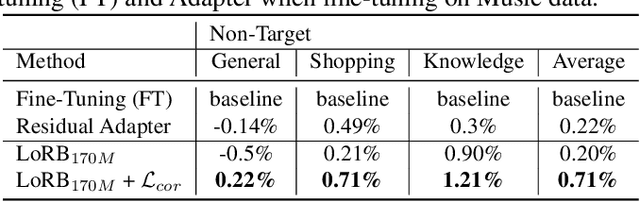
We propose a neural language modeling system based on low-rank adaptation (LoRA) for speech recognition output rescoring. Although pretrained language models (LMs) like BERT have shown superior performance in second-pass rescoring, the high computational cost of scaling up the pretraining stage and adapting the pretrained models to specific domains limit their practical use in rescoring. Here we present a method based on low-rank decomposition to train a rescoring BERT model and adapt it to new domains using only a fraction (0.08%) of the pretrained parameters. These inserted matrices are optimized through a discriminative training objective along with a correlation-based regularization loss. The proposed low-rank adaptation Rescore-BERT (LoRB) architecture is evaluated on LibriSpeech and internal datasets with decreased training times by factors between 5.4 and 3.6.
Streaming Speech-to-Confusion Network Speech Recognition
Jun 02, 2023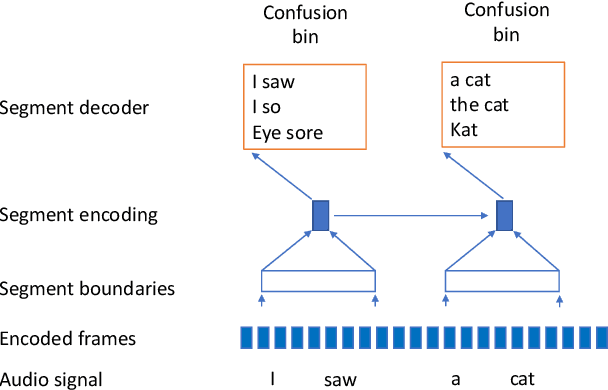
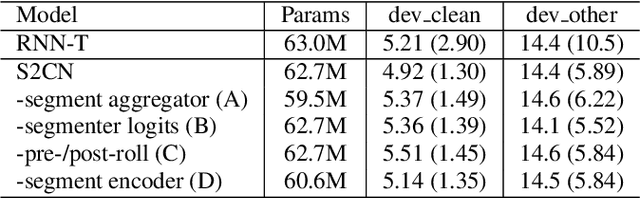
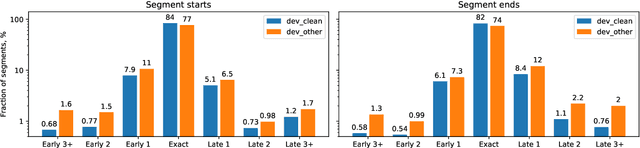
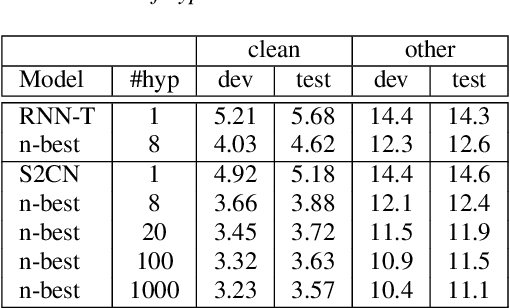
In interactive automatic speech recognition (ASR) systems, low-latency requirements limit the amount of search space that can be explored during decoding, particularly in end-to-end neural ASR. In this paper, we present a novel streaming ASR architecture that outputs a confusion network while maintaining limited latency, as needed for interactive applications. We show that 1-best results of our model are on par with a comparable RNN-T system, while the richer hypothesis set allows second-pass rescoring to achieve 10-20\% lower word error rate on the LibriSpeech task. We also show that our model outperforms a strong RNN-T baseline on a far-field voice assistant task.
PROCTER: PROnunciation-aware ConTextual adaptER for personalized speech recognition in neural transducers
Mar 30, 2023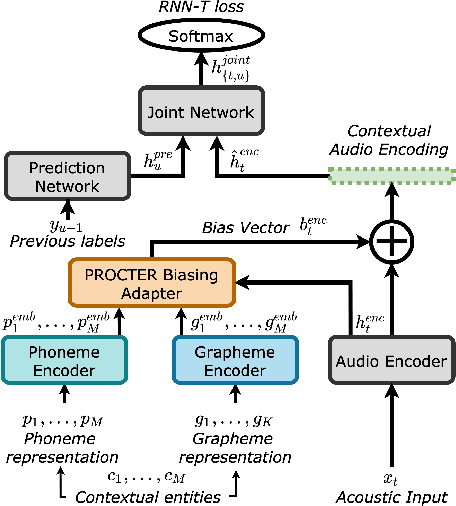
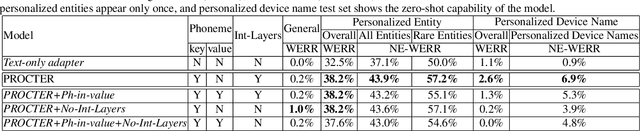

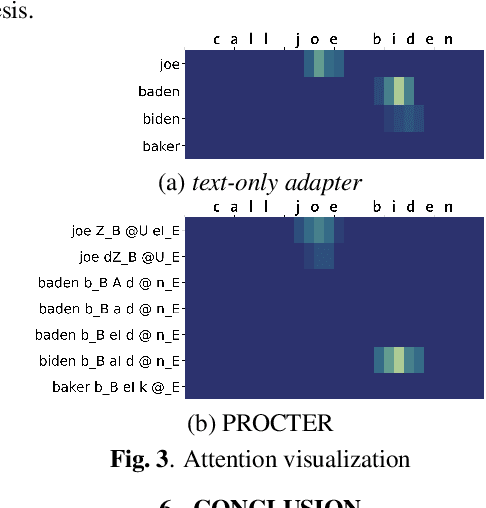
End-to-End (E2E) automatic speech recognition (ASR) systems used in voice assistants often have difficulties recognizing infrequent words personalized to the user, such as names and places. Rare words often have non-trivial pronunciations, and in such cases, human knowledge in the form of a pronunciation lexicon can be useful. We propose a PROnunCiation-aware conTextual adaptER (PROCTER) that dynamically injects lexicon knowledge into an RNN-T model by adding a phonemic embedding along with a textual embedding. The experimental results show that the proposed PROCTER architecture outperforms the baseline RNN-T model by improving the word error rate (WER) by 44% and 57% when measured on personalized entities and personalized rare entities, respectively, while increasing the model size (number of trainable parameters) by only 1%. Furthermore, when evaluated in a zero-shot setting to recognize personalized device names, we observe 7% WER improvement with PROCTER, as compared to only 1% WER improvement with text-only contextual attention
Personalization Strategies for End-to-End Speech Recognition Systems
Feb 15, 2021
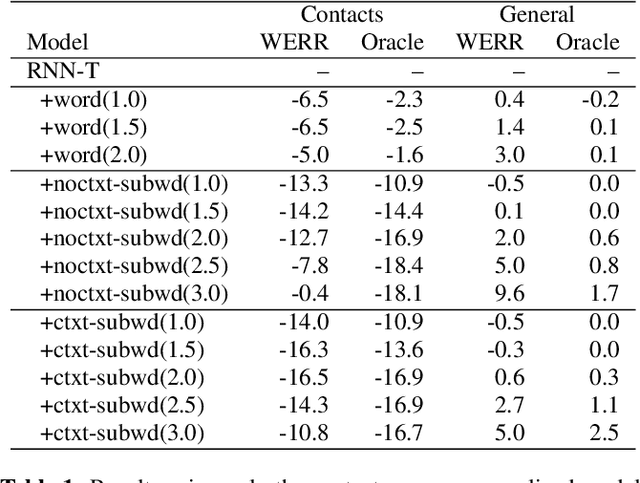
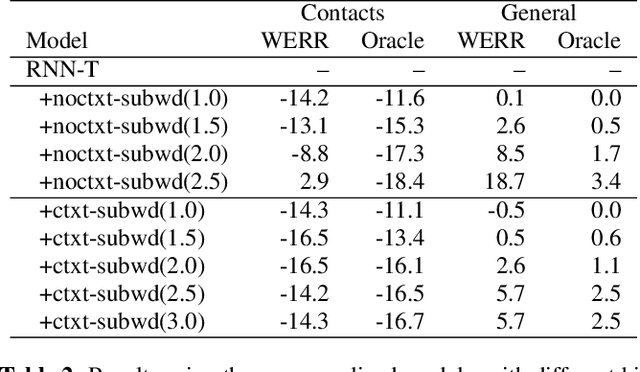
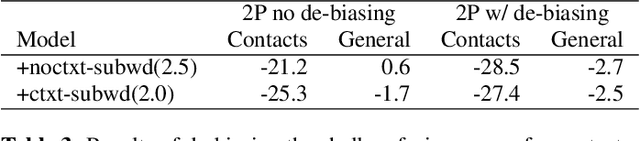
The recognition of personalized content, such as contact names, remains a challenging problem for end-to-end speech recognition systems. In this work, we demonstrate how first and second-pass rescoring strategies can be leveraged together to improve the recognition of such words. Following previous work, we use a shallow fusion approach to bias towards recognition of personalized content in the first-pass decoding. We show that such an approach can improve personalized content recognition by up to 16% with minimum degradation on the general use case. We describe a fast and scalable algorithm that enables our biasing models to remain at the word-level, while applying the biasing at the subword level. This has the advantage of not requiring the biasing models to be dependent on any subword symbol table. We also describe a novel second-pass de-biasing approach: used in conjunction with a first-pass shallow fusion that optimizes on oracle WER, we can achieve an additional 14% improvement on personalized content recognition, and even improve accuracy for the general use case by up to 2.5%.
Domain-aware Neural Language Models for Speech Recognition
Jan 05, 2021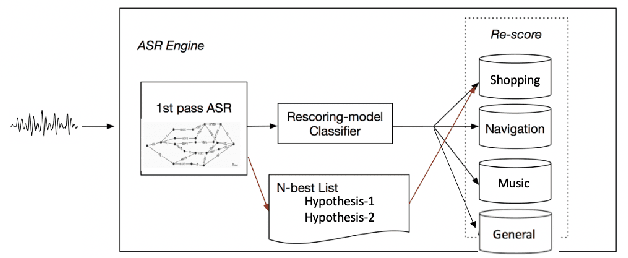
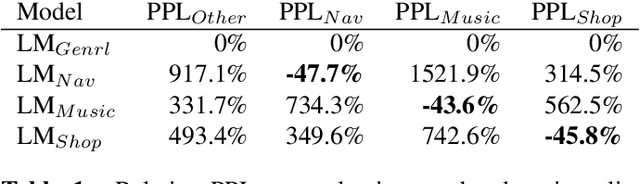

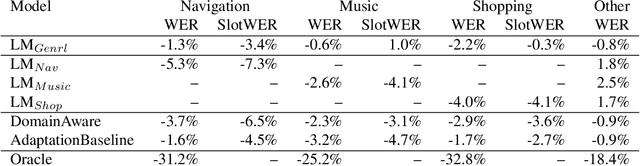
As voice assistants become more ubiquitous, they are increasingly expected to support and perform well on a wide variety of use-cases across different domains. We present a domain-aware rescoring framework suitable for achieving domain-adaptation during second-pass rescoring in production settings. In our framework, we fine-tune a domain-general neural language model on several domains, and use an LSTM-based domain classification model to select the appropriate domain-adapted model to use for second-pass rescoring. This domain-aware rescoring improves the word error rate by up to 2.4% and slot word error rate by up to 4.1% on three individual domains -- shopping, navigation, and music -- compared to domain general rescoring. These improvements are obtained while maintaining accuracy for the general use case.
Improving accuracy of rare words for RNN-Transducer through unigram shallow fusion
Nov 30, 2020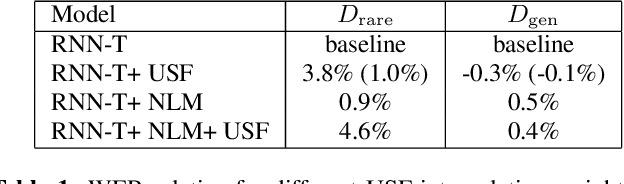

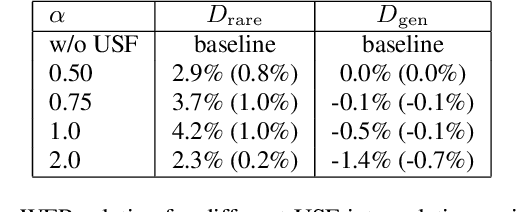
End-to-end automatic speech recognition (ASR) systems, such as recurrent neural network transducer (RNN-T), have become popular, but rare word remains a challenge. In this paper, we propose a simple, yet effective method called unigram shallow fusion (USF) to improve rare words for RNN-T. In USF, we extract rare words from RNN-T training data based on unigram count, and apply a fixed reward when the word is encountered during decoding. We show that this simple method can improve performance on rare words by 3.7% WER relative without degradation on general test set, and the improvement from USF is additive to any additional language model based rescoring. Then, we show that the same USF does not work on conventional hybrid system. Finally, we reason that USF works by fixing errors in probability estimates of words due to Viterbi search used during decoding with subword-based RNN-T.
Multi-task Language Modeling for Improving Speech Recognition of Rare Words
Nov 25, 2020

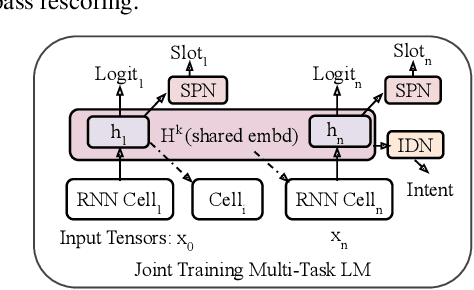
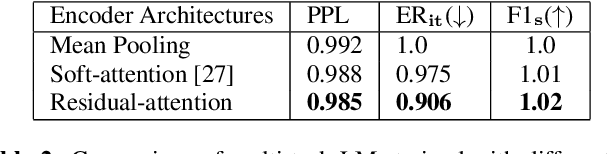
End-to-end automatic speech recognition (ASR) systems are increasingly popular due to their relative architectural simplicity and competitive performance. However, even though the average accuracy of these systems may be high, the performance on rare content words often lags behind hybrid ASR systems. To address this problem, second-pass rescoring is often applied. In this paper, we propose a second-pass system with multi-task learning, utilizing semantic targets (such as intent and slot prediction) to improve speech recognition performance. We show that our rescoring model with trained with these additional tasks outperforms the baseline rescoring model, trained with only the language modeling task, by 1.4% on a general test and by 2.6% on a rare word test set in term of word-error-rate relative (WERR).
Neural Machine Translation For Paraphrase Generation
Jun 25, 2020

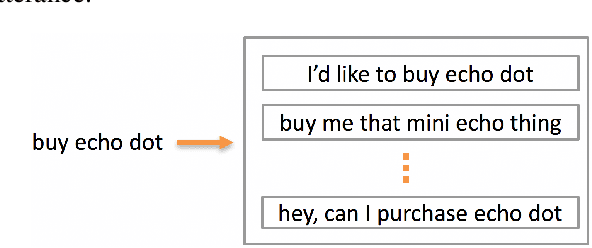
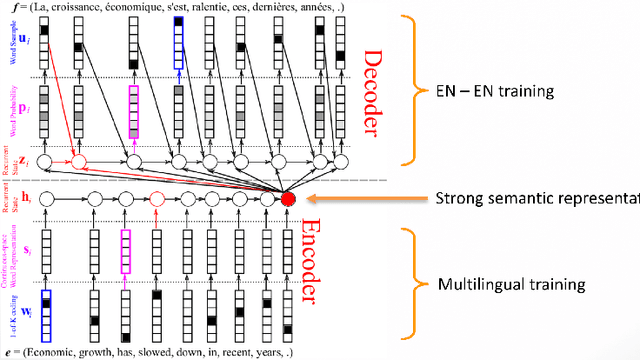
Training a spoken language understanding system, as the one in Alexa, typically requires a large human-annotated corpus of data. Manual annotations are expensive and time consuming. In Alexa Skill Kit (ASK) user experience with the skill greatly depends on the amount of data provided by skill developer. In this work, we present an automatic natural language generation system, capable of generating both human-like interactions and annotations by the means of paraphrasing. Our approach consists of machine translation (MT) inspired encoder-decoder deep recurrent neural network. We evaluate our model on the impact it has on ASK skill, intent, named entity classification accuracy and sentence level coverage, all of which demonstrate significant improvements for unseen skills on natural language understanding (NLU) models, trained on the data augmented with paraphrases.
Scalable Multi Corpora Neural Language Models for ASR
Jul 02, 2019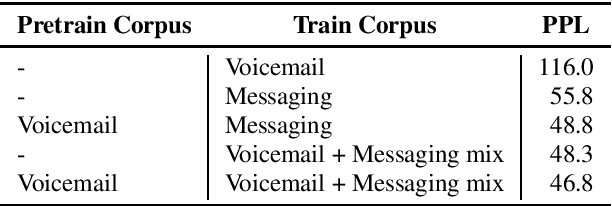


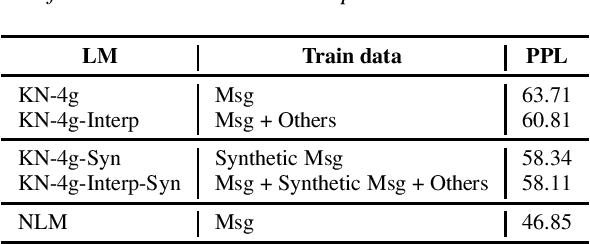
Neural language models (NLM) have been shown to outperform conventional n-gram language models by a substantial margin in Automatic Speech Recognition (ASR) and other tasks. There are, however, a number of challenges that need to be addressed for an NLM to be used in a practical large-scale ASR system. In this paper, we present solutions to some of the challenges, including training NLM from heterogenous corpora, limiting latency impact and handling personalized bias in the second-pass rescorer. Overall, we show that we can achieve a 6.2% relative WER reduction using neural LM in a second-pass n-best rescoring framework with a minimal increase in latency.