 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-aspect Repetition Suppression and Content Moderation of Large Language Models
Apr 20, 2023



Natural language generation is one of the most impactful fields in NLP, and recent years have witnessed its evolution brought about by large language models (LLMs). As the key instrument for writing assistance applications, they are generally prone to replicating or extending offensive content provided in the input. In low-resource data regime, they can also lead to repetitive outputs (Holtzman et al., 2019) [1]. Usually, offensive content and repetitions are mitigated with post-hoc methods, including n-gram level blocklists, top-k and nucleus sampling. In this paper, we introduce a combination of exact and non-exact repetition suppression using token and sequence level unlikelihood loss, repetition penalty during training, inference, and post-processing respectively. We further explore multi-level unlikelihood loss to the extent that it endows the model with abilities to avoid generating offensive words and phrases from the beginning. Finally, with comprehensive experiments, we demonstrate that our proposed methods work exceptionally in controlling the repetition and content quality of LLM outputs.
An Evaluation on Large Language Model Outputs: Discourse and Memorization
Apr 17, 2023We present an empirical evaluation of various outputs generated by nine of the most widely-available large language models (LLMs). Our analysis is done with off-the-shelf, readily-available tools. We find a correlation between percentage of memorized text, percentage of unique text, and overall output quality, when measured with respect to output pathologies such as counterfactual and logically-flawed statements, and general failures like not staying on topic. Overall, 80.0% of the outputs evaluated contained memorized data, but outputs containing the most memorized content were also more likely to be considered of high quality. We discuss and evaluate mitigation strategies, showing that, in the models evaluated, the rate of memorized text being output is reduced. We conclude with a discussion on potential implications around what it means to learn, to memorize, and to evaluate quality text.
USTED: Improving ASR with a Unified Speech and Text Encoder-Decoder
Feb 12, 2022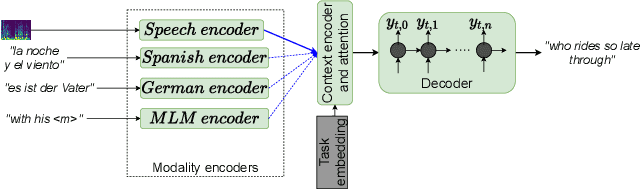
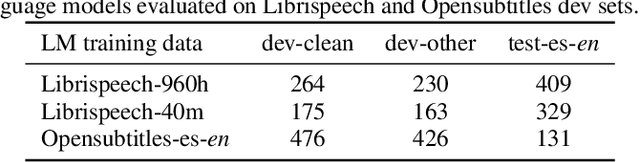
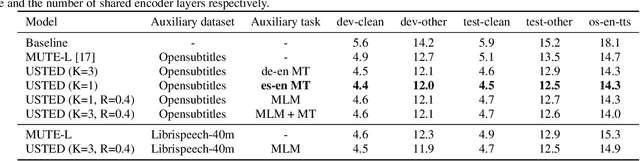
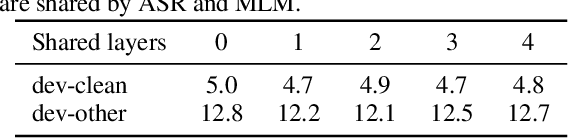
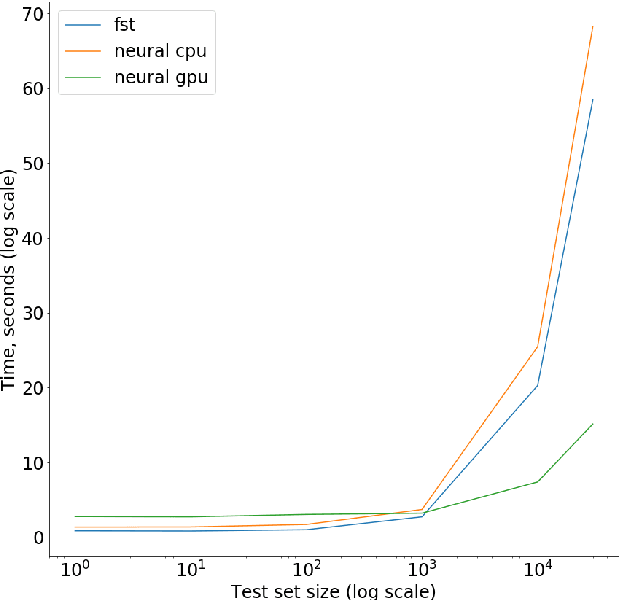
Improving end-to-end speech recognition by incorporating external text data has been a longstanding research topic. There has been a recent focus on training E2E ASR models that get the performance benefits of external text data without incurring the extra cost of evaluating an external language model at inference time. In this work, we propose training ASR model jointly with a set of text-to-text auxiliary tasks with which it shares a decoder and parts of the encoder. When we jointly train ASR and masked language model with the 960-hour Librispeech and Opensubtitles data respectively, we observe WER reductions of 16% and 20% on test-other and test-clean respectively over an ASR-only baseline without any extra cost at inference time, and reductions of 6% and 8% compared to a stronger MUTE-L baseline which trains the decoder with the same text data as our model. We achieve further improvements when we train masked language model on Librispeech data or when we use machine translation as the auxiliary task, without significantly sacrificing performance on the task itself.
Neural Machine Translation for Multilingual Grapheme-to-Phoneme Conversion
Jun 28, 2020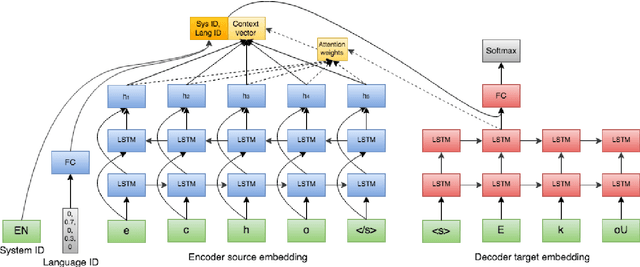

Grapheme-to-phoneme (G2P) models are a key component in Automatic Speech Recognition (ASR) systems, such as the ASR system in Alexa, as they are used to generate pronunciations for out-of-vocabulary words that do not exist in the pronunciation lexicons (mappings like "e c h o" to "E k oU"). Most G2P systems are monolingual and based on traditional joint-sequence based n-gram models [1,2]. As an alternative, we present a single end-to-end trained neural G2P model that shares same encoder and decoder across multiple languages. This allows the model to utilize a combination of universal symbol inventories of Latin-like alphabets and cross-linguistically shared feature representations. Such model is especially useful in the scenarios of low resource languages and code switching/foreign words, where the pronunciations in one language need to be adapted to other locales or accents. We further experiment with word language distribution vector as an additional training target in order to improve system performance by helping the model decouple pronunciations across a variety of languages in the parameter space. We show 7.2% average improvement in phoneme error rate over low resource languages and no degradation over high resource ones compared to monolingual baselines.
Neural Machine Translation For Paraphrase Generation
Jun 25, 2020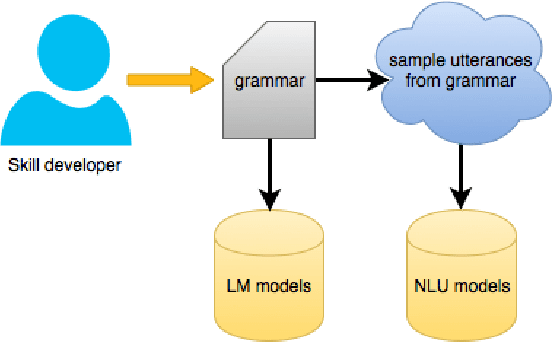

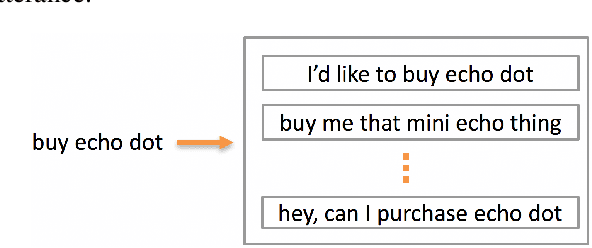
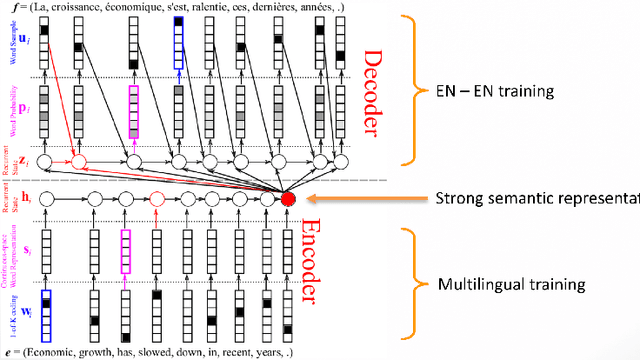
Training a spoken language understanding system, as the one in Alexa, typically requires a large human-annotated corpus of data. Manual annotations are expensive and time consuming. In Alexa Skill Kit (ASK) user experience with the skill greatly depends on the amount of data provided by skill developer. In this work, we present an automatic natural language generation system, capable of generating both human-like interactions and annotations by the means of paraphrasing. Our approach consists of machine translation (MT) inspired encoder-decoder deep recurrent neural network. We evaluate our model on the impact it has on ASK skill, intent, named entity classification accuracy and sentence level coverage, all of which demonstrate significant improvements for unseen skills on natural language understanding (NLU) models, trained on the data augmented with paraphrases.