 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Summarization and Retrieval for Enhanced Personalization via Large Language Models
Oct 30, 2023



Personalization, the ability to tailor a system to individual users, is an essential factor in user experience with natural language processing (NLP) systems. With the emergence of Large Language Models (LLMs), a key question is how to leverage these models to better personalize user experiences. To personalize a language model's output, a straightforward approach is to incorporate past user data into the language model prompt, but this approach can result in lengthy inputs exceeding limitations on input length and incurring latency and cost issues. Existing approaches tackle such challenges by selectively extracting relevant user data (i.e. selective retrieval) to construct a prompt for downstream tasks. However, retrieval-based methods are limited by potential information loss, lack of more profound user understanding, and cold-start challenges. To overcome these limitations, we propose a novel summary-augmented approach by extending retrieval-augmented personalization with task-aware user summaries generated by LLMs. The summaries can be generated and stored offline, enabling real-world systems with runtime constraints like voice assistants to leverage the power of LLMs. Experiments show our method with 75% less of retrieved user data is on-par or outperforms retrieval augmentation on most tasks in the LaMP personalization benchmark. We demonstrate that offline summarization via LLMs and runtime retrieval enables better performance for personalization on a range of tasks under practical constraints.
Learning to Retrieve Engaging Follow-Up Queries
Feb 21, 2023



Open domain conversational agents can answer a broad range of targeted queries. However, the sequential nature of interaction with these systems makes knowledge exploration a lengthy task which burdens the user with asking a chain of well phrased questions. In this paper, we present a retrieval based system and associated dataset for predicting the next questions that the user might have. Such a system can proactively assist users in knowledge exploration leading to a more engaging dialog. The retrieval system is trained on a dataset which contains ~14K multi-turn information-seeking conversations with a valid follow-up question and a set of invalid candidates. The invalid candidates are generated to simulate various syntactic and semantic confounders such as paraphrases, partial entity match, irrelevant entity, and ASR errors. We use confounder specific techniques to simulate these negative examples on the OR-QuAC dataset and develop a dataset called the Follow-up Query Bank (FQ-Bank). Then, we train ranking models on FQ-Bank and present results comparing supervised and unsupervised approaches. The results suggest that we can retrieve the valid follow-ups by ranking them in higher positions compared to confounders, but further knowledge grounding can improve ranking performance.
REDAT: Accent-Invariant Representation for End-to-End ASR by Domain Adversarial Training with Relabeling
Dec 14, 2020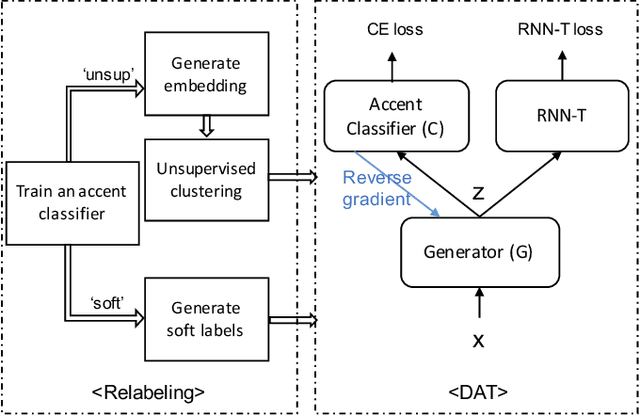
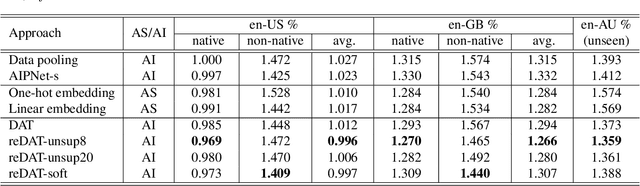
Accents mismatching is a critical problem for end-to-end ASR. This paper aims to address this problem by building an accent-robust RNN-T system with domain adversarial training (DAT). We unveil the magic behind DAT and provide, for the first time, a theoretical guarantee that DAT learns accent-invariant representations. We also prove that performing the gradient reversal in DAT is equivalent to minimizing the Jensen-Shannon divergence between domain output distributions. Motivated by the proof of equivalence, we introduce reDAT, a novel technique based on DAT, which relabels data using either unsupervised clustering or soft labels. Experiments on 23K hours of multi-accent data show that DAT achieves competitive results over accent-specific baselines on both native and non-native English accents but up to 13% relative WER reduction on unseen accents; our reDAT yields further improvements over DAT by 3% and 8% relatively on non-native accents of American and British English.
Streaming End-to-End Bilingual ASR Systems with Joint Language Identification
Jul 08, 2020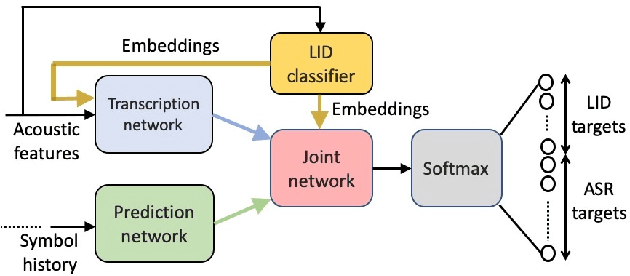
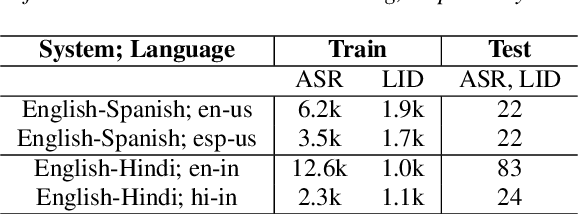
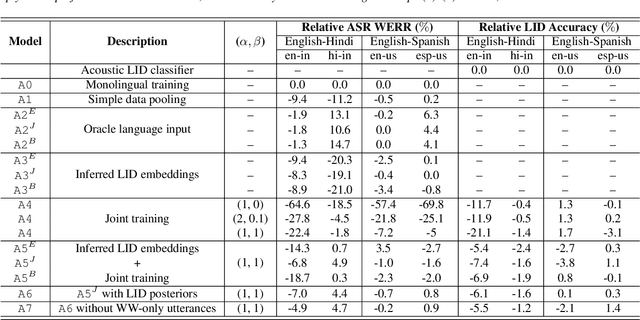
Multilingual ASR technology simplifies model training and deployment, but its accuracy is known to depend on the availability of language information at runtime. Since language identity is seldom known beforehand in real-world scenarios, it must be inferred on-the-fly with minimum latency. Furthermore, in voice-activated smart assistant systems, language identity is also required for downstream processing of ASR output. In this paper, we introduce streaming, end-to-end, bilingual systems that perform both ASR and language identification (LID) using the recurrent neural network transducer (RNN-T) architecture. On the input side, embeddings from pretrained acoustic-only LID classifiers are used to guide RNN-T training and inference, while on the output side, language targets are jointly modeled with ASR targets. The proposed method is applied to two language pairs: English-Spanish as spoken in the United States, and English-Hindi as spoken in India. Experiments show that for English-Spanish, the bilingual joint ASR-LID architecture matches monolingual ASR and acoustic-only LID accuracies. For the more challenging (owing to within-utterance code switching) case of English-Hindi, English ASR and LID metrics show degradation. Overall, in scenarios where users switch dynamically between languages, the proposed architecture offers a promising simplification over running multiple monolingual ASR models and an LID classifier in parallel.
Streaming Language Identification using Combination of Acoustic Representations and ASR Hypotheses
Jun 01, 2020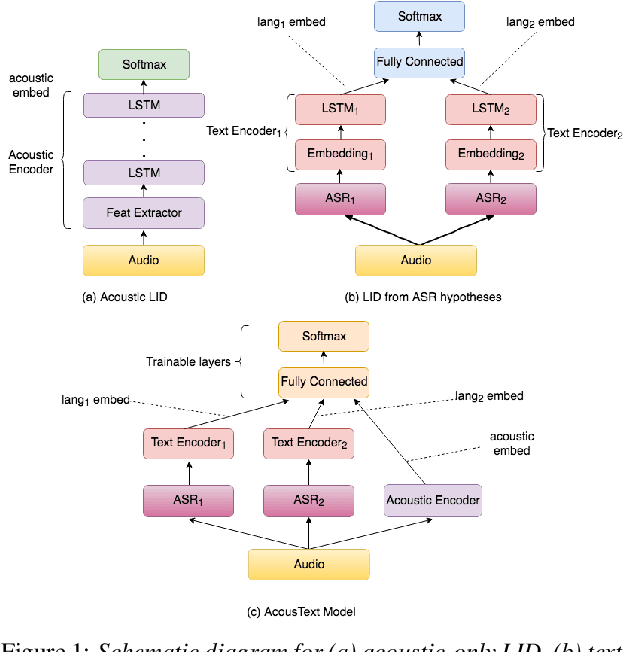
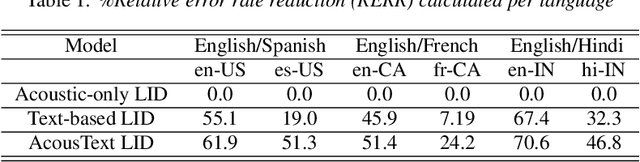
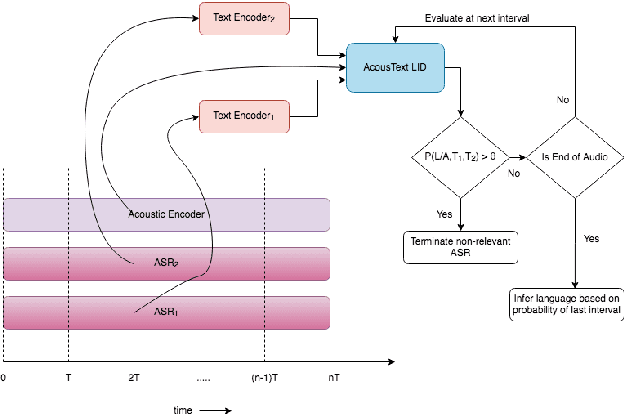

This paper presents our modeling and architecture approaches for building a highly accurate low-latency language identification system to support multilingual spoken queries for voice assistants. A common approach to solve multilingual speech recognition is to run multiple monolingual ASR systems in parallel and rely on a language identification (LID) component that detects the input language. Conventionally, LID relies on acoustic only information to detect input language. We propose an approach that learns and combines acoustic level representations with embeddings estimated on ASR hypotheses resulting in up to 50% relative reduction of identification error rate, compared to a model that uses acoustic only features. Furthermore, to reduce the processing cost and latency, we exploit a streaming architecture to identify the spoken language early when the system reaches a predetermined confidence level, alleviating the need to run multiple ASR systems until the end of input query. The combined acoustic and text LID, coupled with our proposed streaming runtime architecture, results in an average of 1500ms early identification for more than 50% of utterances, with almost no degradation in accuracy. We also show improved results by adopting a semi-supervised learning (SSL) technique using the newly proposed model architecture as a teacher model.
LSTM-based Whisper Detection
Sep 20, 2018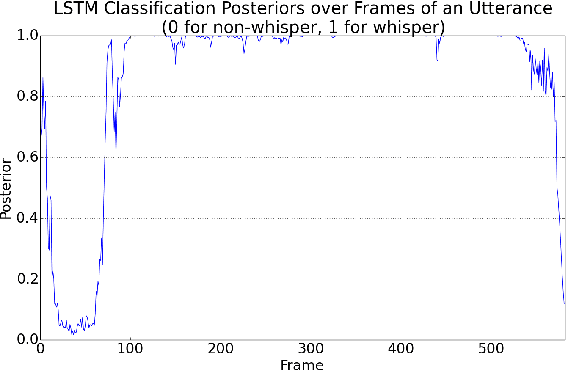

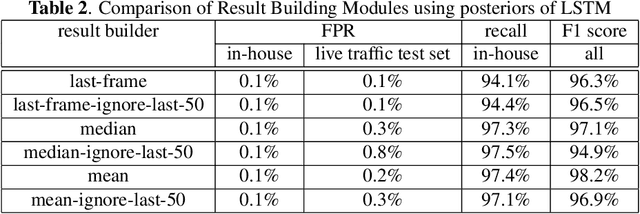
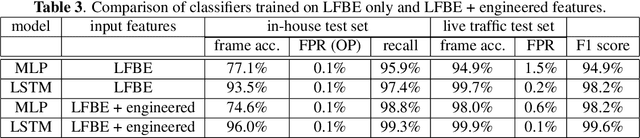
This article presents a whisper speech detector in the far-field domain. The proposed system consists of a long-short term memory (LSTM) neural network trained on log-filterbank energy (LFBE) acoustic features. This model is trained and evaluated on recordings of human interactions with voice-controlled, far-field devices in whisper and normal phonation modes. We compare multiple inference approaches for utterance-level classification by examining trajectories of the LSTM posteriors. In addition, we engineer a set of features based on the signal characteristics inherent to whisper speech, and evaluate their effectiveness in further separating whisper from normal speech. A benchmarking of these features using multilayer perceptrons (MLP) and LSTMs suggests that the proposed features, in combination with LFBE features, can help us further improve our classifiers. We prove that, with enough data, the LSTM model is indeed as capable of learning whisper characteristics from LFBE features alone com- pared to a simpler MLP model that uses both LFBE and features engineered for separating whisper and normal speech. In addition, we prove that the LSTM classifiers accuracy can be further improved with the incorporation of the proposed engineered features.